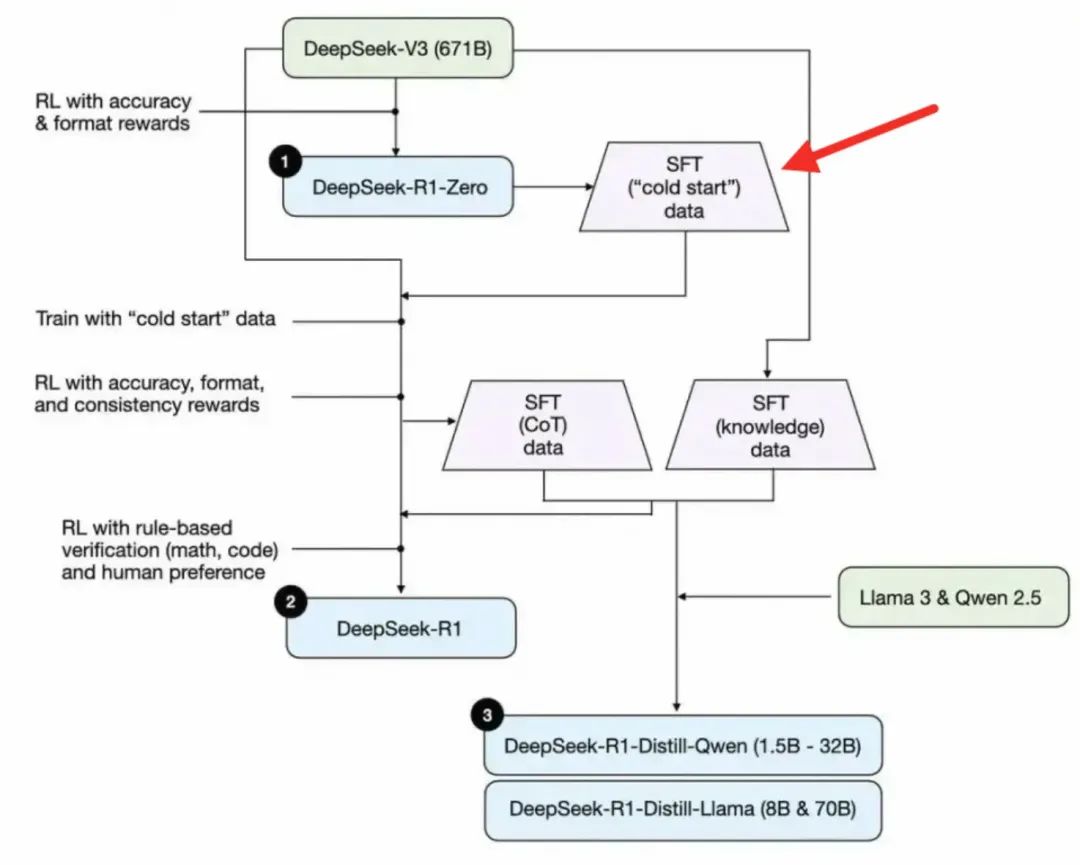
随着DeepSeek的火爆使用,其背后的训练技术也值得深入学习,整体DeepSeek相关的训练过程如下图所示。
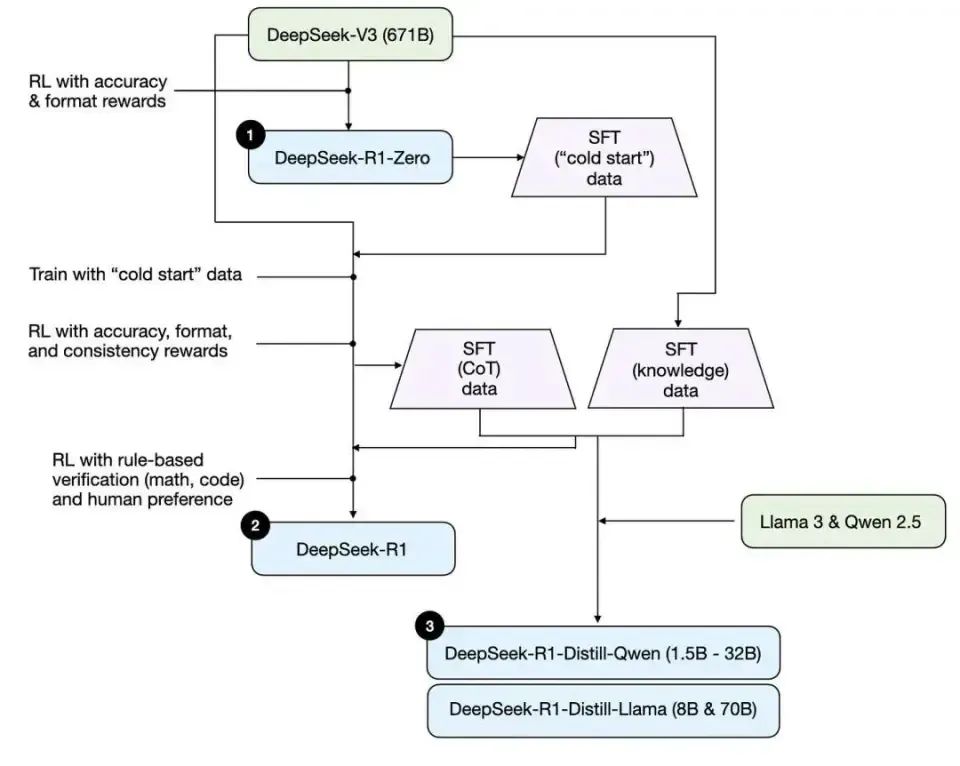
其中主要涉及以下三个模型,其中DeepSeek-R1-Zero模型所涉及的强化学习算法,是DeepSeek最核心的部分之一,本次我们主要重现的也是这个部分。
是在基础模型DeepSeek-V3上进行强化学习(RL)后得到了DeepSeek-R1-Zero模型。该模型学会了如何推理、创建思维链序列,并具备自我验证和反思等能力。尽管DeepSeek-R1-Zero的学习能力令人惊叹,但它存在语言混合、可读性差等严重问题。
首先使用数千个思维链(CoT)序列示例形式的冷启动数据,在DeepSeek-V3上进行监督微调(SFT),目的是为强化学习创建一个更稳定的起点,解决DeepSeek-R1-Zero存在的问题。接着进行强化学习,并设置奖励机制,以促进语言一致性,增强在科学、编码和数学等任务上的推理能力。然后,再次进行监督微调,这次加入了非推理重点的训练示例,帮助模型保留写作、角色扮演等更多通用能力。最后,再次进行强化学习,以更好地符合人类偏好。最终得到了一个拥有6710亿参数的高性能模型。
他们基于Qwen和Llama架构,对参数在15亿 – 700亿之间的较小模型进行微调,得到了一组更轻量、更高效且推理能力更强的模型。这极大地提高了开发人员的可及性,因为许多提炼后的模型可以在他们的设备上快速运行。
强化学习(TRL):主要采用了huggingface提供的grpo_trainer方案(参考链接:https://gist.github.com/willccbb/4676755236bb08cab5f4e54a0475d6fb)
数据集:主要通过数据集gsm8k进行训练
GPU: 单张A10,显存24G
模型:Qwen2.5-0.5B-Instruct
# 基于目前最新的vllm 0.7.2进行验证pip install vllm -U# 基于目前最新的trl 0.15.1进行验证pip install trl -U
import reimport torchfrom modelscope import AutoTokenizer, AutoModelForCausalLMfrom modelscope.msdatasets import MsDatasetfrom trl import GRPOConfig, GRPOTrainerSYSTEM_PROMPT = """You need to answer in XML format, includeand , respond in the following format: ......"""XML_COT_FORMAT = """{reasoning}{answer}"""def extract_xml_answer(text: str) -> str:answer = text.split("" )[-1]answer = answer.split("")[0]return answer.strip()def extract_hash_answer(text: str) -> str | None:if "####" not in text:return Nonereturn text.split("####")[1].strip()def get_gsm8k_questions(split="train") -> MsDataset:data = MsDataset.load('modelscope/gsm8k', subset_name='main', split=split)data = data.map(lambda x: {'prompt': [{'role': 'system', 'content': SYSTEM_PROMPT},{'role': 'user', 'content': x['question']}],'answer': extract_hash_answer(x['answer'])})return datadataset = get_gsm8k_questions()# Reward functionsdef correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]:responses = [completion[0]['content'] for completion in completions]q = prompts[0][-1]['content']extracted_responses = [extract_xml_answer(r) for r in responses]print('-' * 20, f"Question:n{q}", f"nAnswer:n{answer[0]}", f"nResponse:n{responses[0]}",f"nExtracted:n{extracted_responses[0]}")return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]def int_reward_func(completions, **kwargs) -> list[float]:responses = [completion[0]['content'] for completion in completions]extracted_responses = [extract_xml_answer(r) for r in responses]return [0.5 if r.isdigit() else 0.0 for r in extracted_responses]def strict_format_reward_func(completions, **kwargs) -> list[float]:pattern = r"n.*?n nn.*?n "responses = [completion[0]["content"] for completion in completions]# 新增调试日志matches = []for idx, r in enumerate(responses):print(f"n--- Processing response {idx} ---")print("Raw content:", repr(r)) # 使用 repr() 显示转义字符match = re.fullmatch(pattern, r, re.DOTALL)print("Match result:", bool(match))matches.append(match)return [0.5 if match else 0.0 for match in matches]def soft_format_reward_func(completions, **kwargs) -> list[float]:pattern = r".*? s*.*? "responses = [completion[0]["content"] for completion in completions]matches = [re.fullmatch(pattern, r, re.DOTALL) for r in responses]return [0.5 if match else 0.0 for match in matches]def count_xml(text) -> float:count = 0.0if text.count("n" ) == 1:count += 0.125if text.count("nn") == 1:count += 0.125if text.count("nn" ) == 1:count += 0.125count -= len(text.split("nn")[-1]) * 0.001if text.count("n") == 1:count += 0.125count -= (len(text.split("n")[-1]) - 1) * 0.001return countdef xmlcount_reward_func(completions, **kwargs) -> list[float]:contents = [completion[0]["content"] for completion in completions]return [count_xml(c) for c in contents]model_name = "Qwen/Qwen2.5-0.5B-Instruct"output_dir = "outputs/Qwen-0.5B-GRPO"run_name = "Qwen-0.5B-GRPO-gsm8k"training_args = GRPOConfig(output_dir=output_dir,run_name=run_name,learning_rate=5e-6,adam_beta1=0.9,adam_beta2=0.99,weight_decay=0.1,warmup_ratio=0.1,lr_scheduler_type='cosine',logging_steps=1,bf16=True,per_device_train_batch_size=8,gradient_accumulation_steps=4,num_generations=8,max_prompt_length=256,max_completion_length=200,num_train_epochs=1,save_steps=100,max_grad_norm=0.1,log_on_each_node=False,use_vllm=True,vllm_gpu_memory_utilization=.2,vllm_device="cuda:0",report_to="none")model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype=torch.bfloat16,device_map=None).to("cuda")tokenizer = AutoTokenizer.from_pretrained(model_name)tokenizer.pad_token = tokenizer.eos_tokentrainer = GRPOTrainer(model=model,processing_class=tokenizer,reward_funcs=[xmlcount_reward_func,soft_format_reward_func,strict_format_reward_func,int_reward_func,correctness_reward_func],args=training_args,train_dataset=dataset,)trainer.train()
如上面代码所示,主要涉及以下5个奖励函数
4.1. correctness_reward_func(正确性奖励函数)
检查模型的输出是否与参考答案 (answer) 完全匹配,匹配则奖励 2.0,否则 0.0。
4.2. int_reward_func(整数检测奖励函数)
检查模型输出是否是纯数字(整数),是则奖励 0.5,否则 0.0。
4.3. strict_format_reward_func(严格格式奖励函数)
严格格式奖励,必须完全匹配
4.4. soft_format_reward_func(宽松格式奖励函数)
允许更灵活的格式,只要包含
4.5. count_xml,xmlcount_reward_func(XML 结构评分函数)
计算模型输出 XML 结构的完整度,并给予相应奖励。奖励规则:
检查 XML 结构完整度:
每个正确的标签匹配增加 0.125 奖励:
\n:+0.125
:+0.125
考虑额外文本的惩罚:
如果 后面有多余的内容,则减少奖励 0.001 × 额外字符数
核心参数说明如下:
1.gradient_accumulation_steps=4:每进行4次的前向传播和反向传播后,才会执行一次权重更新;
2.max_completion_length=200: 表示限制模型返回最大长度200;
3.save_steps=100:表示每运行100步才保存一次checkpoint;
gsm8k数据集一共接近8000条数据,每4次会更新一次,则需要更新2000次,每100步保存一次,则需要生成20个checkpoint。
通过python train.py > train.log运行代码,通过tail -f train.log进行实时日志查看,最后整体效果如下图所示,最后有效数据1868个,运行时间是2:25:25。

GRPO Trainer会记录很多训练过程中的指标,主要包括在:
-
completion_length:完成时长; -
reward/{reward_func_name}:每个 reward 函数计算的奖励; -
reward:平均奖励; -
reward_std :奖励组内的平均标准差; -
kl : 根据完成次数计算的模型和参考模型之间的平均 KL 散度。
其中我们主要关注以下两个奖励指标:
-
准确性奖励:基于响应的正确性(对应correctness_reward_func) -
格式奖励:确保响应符合结构指南(对应strict_format_reward_func和soft_format_reward_func)
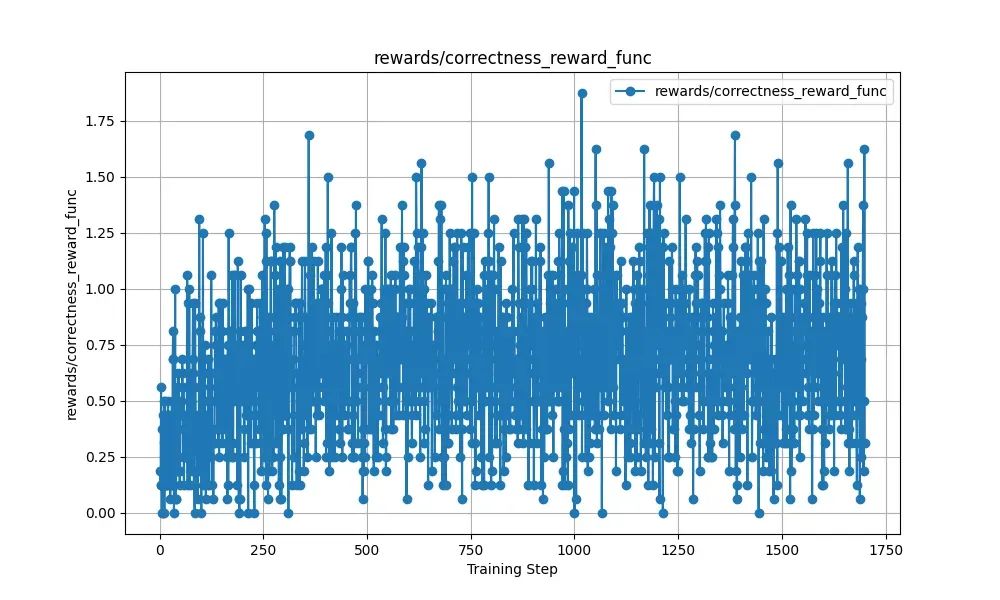
2.1. 准确性奖励
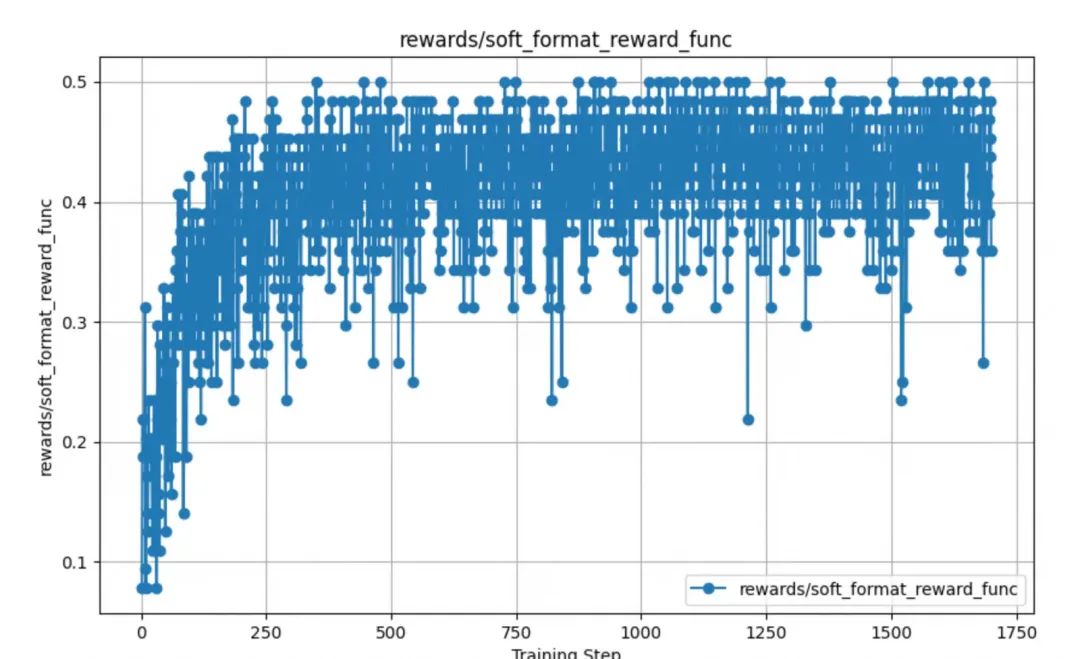
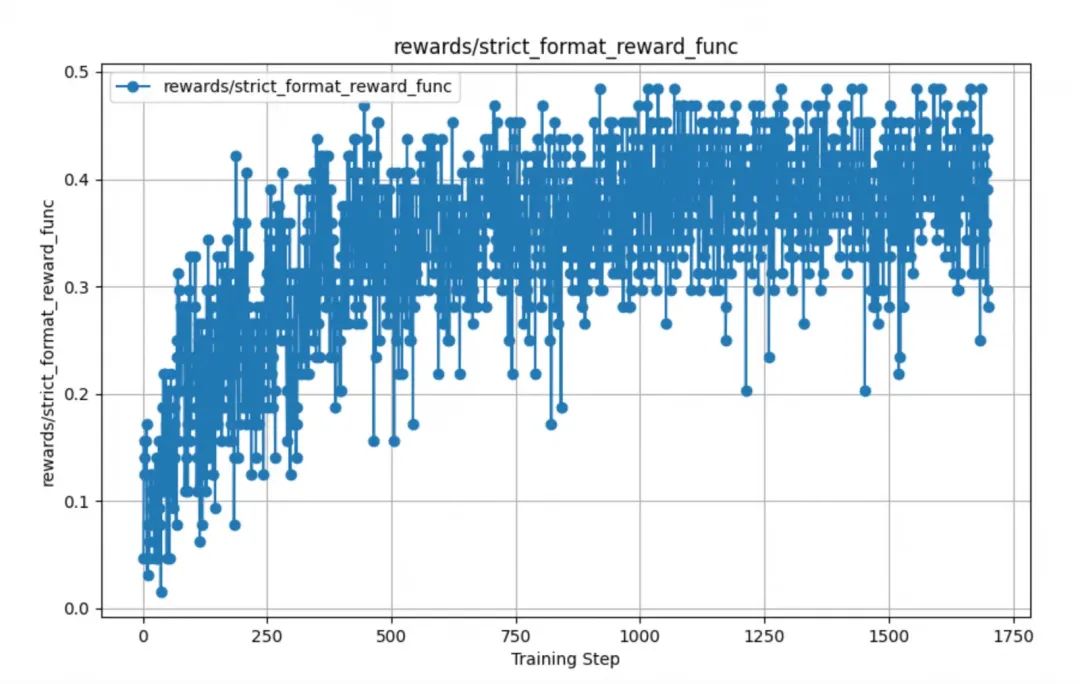
2.2. 格式奖励
格式和答案都不对,而且不稳定:
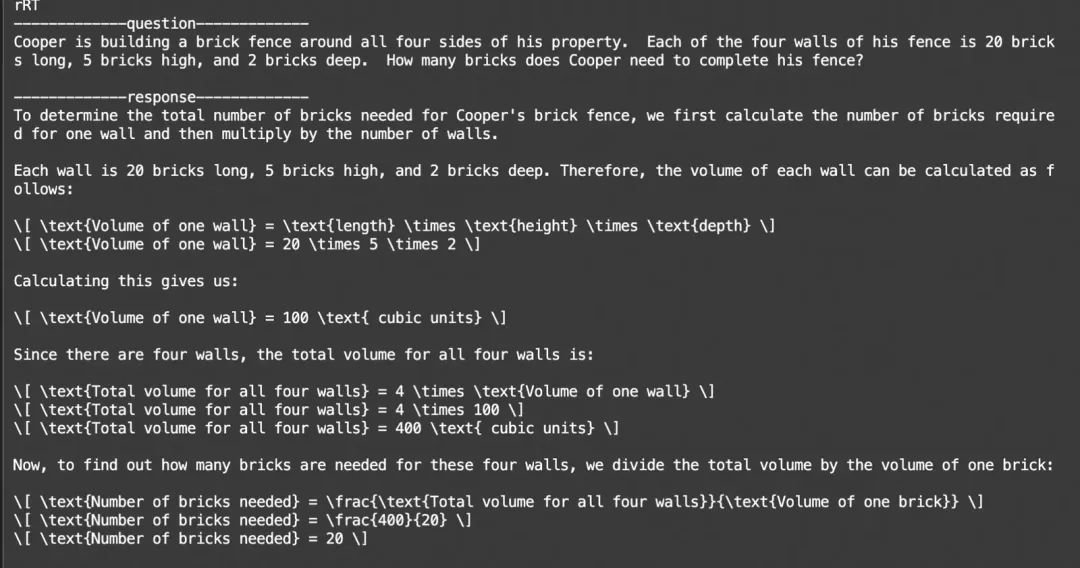
格式和答案都满足要求:

通过对比微调前后的模型,虽然我们这次使用的是一个0.5B的小模型,数据量也不大,但是还是可以通过这个流程,体验强化学习的整个流程,对我们理解强化学习还是很有好处的。并且从整个实验中,也理解了DeepSeek整个方案设计的原因,其中以下几个点印象深刻。
通过对训练后的奖励函数数据进行分析发现,其中模型的格式奖励函数strict_format_reward_func和soft_format_reward_func,都是在训练到固定步数左右的时候,得分开始突然上升,然后后续就逐渐稳定,如下图所示。可以看到,宽松校验在500步的时候已经基本稳定到0.5的分数,而由于严格模式对格式更加严格,所以严格模式在1000步的时候才到稳定。通过这样的数据,可以指导我们下一步进行实验数据调整,从而获取最佳的checkponit模型进行导出。
我们可以看到模型在早期训练的时候,效果很差,模型基本都是在瞎试。所以为了加快训练,deepseek加入了SFT的数据解决冷启动的问题,如下面的截图所示。通过R1-Zero生成SFT的数据,解决了R1的冷启动问题。
0 条评论