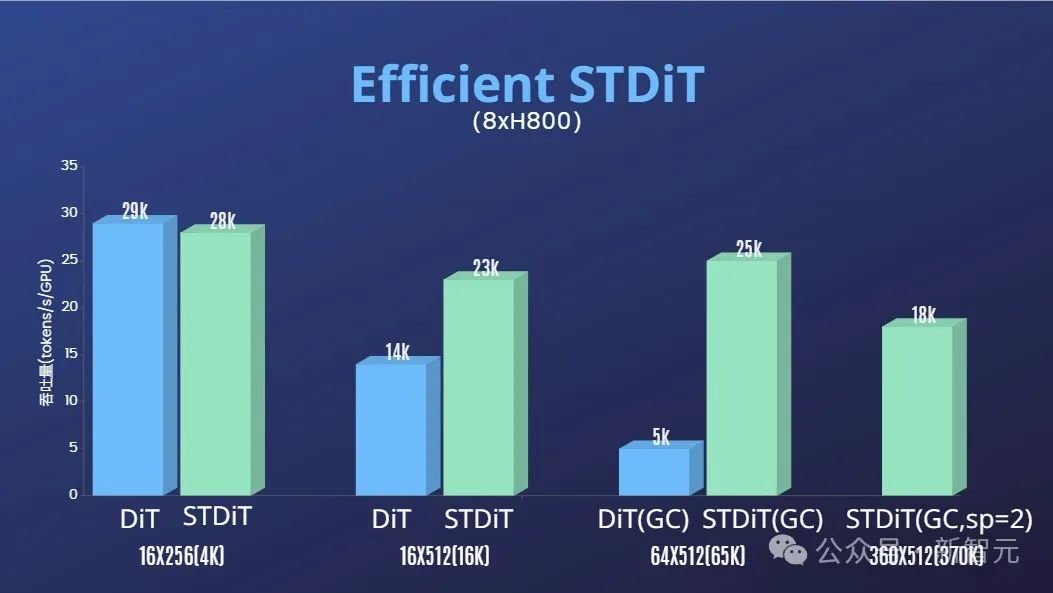
除了大幅降低Sora复现的技术门槛,提升视频生成在时长、分辨率、内容等多个维度的质量,作者团队还提供了Colossal-AI加速系统进行Sora复现的高效训练加持。通过算子优化和混合并行等高效训练策略,在处理64帧、512×512分辨率视频的训练中,实现了1.55倍的加速效果。同时,得益于Colossal-AI的异构内存管理系统,在单台服务器上(8 x H800)可以无阻碍地进行1分钟的1080p高清视频训练任务。此外,在作者团队的报告中,我们也发现STDiT模型架构在训练时也展现出卓越的高效性。和采用全注意力机制的DiT相比,随着帧数的增加,STDiT实现了高达5倍的加速效果,这在处理长视频序列等现实任务中尤为关键。
作者团队提及,他们将会继续维护和优化Open-Sora项目,预计将使用更多的视频训练数据,以生成更高质量、更长时长的视频内容,并支持多分辨率特性,切实推进AI技术在电影、游戏、广告等领域的落地。参考资料:[1] https://arxiv.org/abs/2212.09748 Scalable Diffusion Models with Transformers[2] https://arxiv.org/abs/2310.00426 PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis[3] https://arxiv.org/abs/2311.15127 Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets[4] https://arxiv.org/abs/2401.03048 Latte: Latent Diffusion Transformer for Video Generation[5] https://huggingface.co/stabilityai/sd-vae-ft-mse-original[6] https://github.com/google-research/text-to-text-transfer-transformer[7] https://github.com/haotian-liu/LLaVA[8] https://hpc-ai.com/blog/open-sora-v1.0












0 条评论