编写一个程序,开启3个线程A,B,C,给定一组数据,将该数据分成3部分,分别让ABC三个线程进行排序处理(存储到本地文件中),三个线程处理完成之后,将这个三个文件内容读取后合并成一个有序文件,返回文件路径:
演示了如何使用多线程对给定数据进行分块排序并合并:
import java.io.*;
import java.util.*;
import java.util.concurrent.*;
public class MultiThreadSort {
public static String sort(int[] data, int threadCount) throws IOException, InterruptedException, ExecutionException {
int chunkSize = data.length / threadCount;
List<File> chunkFiles = new ArrayList<>();
ExecutorService executor = Executors.newFixedThreadPool(threadCount);
for (int i = 0; i < threadCount; i++) {
int startIndex = i * chunkSize;
int endIndex = (i == threadCount - 1) ? data.length : (i + 1) * chunkSize;
int[] chunk = Arrays.copyOfRange(data, startIndex, endIndex);
File chunkFile = new File(String.format("chunk%d.dat", i));
chunkFiles.add(chunkFile);
executor.submit(new SortTask(chunk, chunkFile));
}
executor.shutdown();
executor.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
String outputPath = "output.dat";
merge(chunkFiles, outputPath);
return outputPath;
}
private static void merge(List<File> chunkFiles, String outputPath) throws IOException {
PriorityQueue<ChunkReader> heap = new PriorityQueue<>();
try (BufferedWriter bw = new BufferedWriter(new FileWriter(outputPath))) {
List<ChunkReader> chunkReaders = new ArrayList<>();
for (File chunkFile : chunkFiles) {
ChunkReader reader = new ChunkReader(chunkFile);
chunkReaders.add(reader);
if (reader.hasNext()) {
heap.offer(reader);
}
}
while (!heap.isEmpty()) {
ChunkReader reader = heap.poll();
bw.write(reader.nextInt());
if (heap.isEmpty()) {
bw.newLine();
} else {
bw.write(" ");
}
if (reader.hasNext()) {
heap.offer(reader);
} else {
reader.close();
chunkReaders.remove(reader);
}
}
for (ChunkReader reader : chunkReaders) {
reader.close();
}
}
}
private static class SortTask implements Runnable {
private final int[] data;
private final File outputFile;
public SortTask(int[] data, File outputFile) {
this.data = data;
this.outputFile = outputFile;
}
@Override
public void run() {
Arrays.sort(data);
try (DataOutputStream dos = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(outputFile)))) {
for (int x : data) {
dos.writeInt(x);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
private static class ChunkReader implements Comparable<ChunkReader>, Closeable {
private final DataInputStream dis;
private int current;
public ChunkReader(File file) throws IOException {
this.dis = new DataInputStream(new BufferedInputStream(new FileInputStream(file)));
this.current = dis.readInt();
}
public int nextInt() throws IOException {
int ret = current;
if (dis.available() > 0) {
current = dis.readInt();
} else {
current = Integer.MAX_VALUE;
}
return ret;
}
public boolean hasNext() throws IOException {
return dis.available() > 0;
}
@Override
public void close() throws IOException {
dis.close();
}
@Override
public int compareTo(ChunkReader o) {
return Integer.compare(current, o.current);
}
}
}
这个程序的输入是一个整数数组和线程数,输出是合并后的有序文件路径。程序首先将原始数据分成了 $threadCount$ 个块,每个块都在一个单独的线程中排序并保存到一个文件中。然后程序使用归并排序的思想将这些块合并成一个有序文件。具体来说,程序首先将每个块的第一个元素放入一个小根堆中。然后程序从小根堆中取出最小的元素,并将它写入输出文件中。如果这个元素来自某个块的最后一个元素,则该块的读取器被关闭。程序重复这个过程,直到所有块都被读取完毕。
简单说就是,n个排序好的小文件,优先队列里的只持有小文件的readInt()也就是第一个,每次读取时会比较优先队列的里元素,取最小的一个,取完的当前文件继续移动指针,直到取完所有的数据,这样取出来的数据一定是有序的;
实际上解决的思路是把问题缩小了,缩小到维护n个小文件的top,再用把当前文件读取对象的offer进去;优先队列天然就是按排序规则排序好的;通过移动指针和对比并写入到文件就实现对大批数据的排序;
以下是一个使用示例:
import java.io.IOException;
import java.util.Arrays;
import java.util.Random;
public class Main {
public static void main(String[] args) throws IOException, InterruptedException, ExecutionException {
int[] data = new int[10000000];
Random rand = new Random();
for (int i = 0; i < data.length; i++) {
data[i] = rand.nextInt(1000000);
}
String outputPath = MultiThreadSort.sort(data, 3);
System.out.println("Output file: " + outputPath);
}
}
在这个示例中,我们生成了一个包含 10000000 个随机整数的数组,并将其保存到一个文件中。然后我们使用 MultiThreadSort.sort 方法对这些整数进行排序,使用 3 个线程进行处理。最后,我们打印合并后的有序文件路径。
使用 Java 多线程实现将一组有序数据分成3等分,并由3个线程依次处理并写入文件的示例代码:
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class Main {
public static void main(String[] args) {
int[] data = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15}; // 原始数据
int len = data.length;
int partLen = len / 3; // 每个线程处理的数据长度
// 创建3个线程,并分别传入不同的数据段
Thread t1 = new Thread(new Worker(data, 0, partLen));
Thread t2 = new Thread(new Worker(data, partLen, partLen * 2));
Thread t3 = new Thread(new Worker(data, partLen * 2, len));
// 启动3个线程
t1.start();
t2.start();
t3.start();
// 等待3个线程结束
try {
t1.join();
t2.join();
t3.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 输出文件路径
System.out.println("文件路径:/path/to/XXX");
}
static class Worker implements Runnable {
private final int[] data;
private final int start;
private final int end;
public Worker(int[] data, int start, int end) {
this.data = data;
this.start = start;
this.end = end;
}
@Override
public void run() {
try {
BufferedWriter writer = new BufferedWriter(new FileWriter("/path/to/XXX", true));
for (int i = start; i < end; i++) {
writer.write(data[i] + "\n");
}
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
在上面的代码中,我们首先定义了一组有序数据 data,然后将其分成了3等分,每个线程处理其中一部分数据。具体来说,我们创建了3个线程 t1、t2、t3,每个线程传入不同的数据段,即 data[0, partLen-1]、data[partLen, partLen*2-1]、data[partLen*2, len-1]。
然后我们启动了这3个线程,并等待它们全部处理完毕。在每个线程的 run() 方法中,我们使用 BufferedWriter 将处理的数据写入到文件中,每个数字占一行。最后输出文件路径。
需要注意的是,由于多个线程同时写入同一个文件,可能会导致写入顺序错乱的问题。因此,我们使用 BufferedWriter 来确保写入的顺序是正确的。同时,由于文件写入操作可能会出现异常,需要在代码中进行异常处理。
下面是一个示例代码,可以实现将给定一组有序数据分成3等分,然后让3个线程 A、B、C 分别处理并将结果写入文件中。在处理过程中,要保证线程 A、B、C 的输出顺序。
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Arrays;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class ThreeWaySplit {
private static final int NUM_THREADS = 3;
public static void main(String[] args) throws IOException, InterruptedException {
int[] data = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
String filePath = "output.txt";
BufferedWriter writer = new BufferedWriter(new FileWriter(filePath));
CyclicBarrier barrier = new CyclicBarrier(NUM_THREADS);
int chunkSize = data.length / NUM_THREADS;
for (int i = 0; i < NUM_THREADS; i++) {
int start = i * chunkSize;
int end = (i == NUM_THREADS - 1) ? data.length : (i + 1) * chunkSize;
int[] chunk = Arrays.copyOfRange(data, start, end);
Thread thread = new Thread(new Worker(chunk, writer, barrier, i));
thread.start();
}
writer.close();
System.out.println("Output file path: " + filePath);
}
private static class Worker implements Runnable {
private final int[] data;
private final BufferedWriter writer;
private final CyclicBarrier barrier;
private final int id;
public Worker(int[] data, BufferedWriter writer, CyclicBarrier barrier, int id) {
this.data = data;
this.writer = writer;
this.barrier = barrier;
this.id = id;
}
@Override
public void run() {
try {
for (int i : data) {
writer.write(Integer.toString(i));
writer.newLine();
writer.flush();
barrier.await();
}
} catch (IOException | InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
}
}
注:为了简化示例代码,这里将数据固定在代码中。在实际应用中,可以通过参数传递或者从文件等数据源中读取数据。
在上面的代码中,我们首先将原始数据分成 3 个块,并创建 3 个线程,每个线程处理一个块的数据。在每个线程中,我们使用 BufferedWriter 将数据写入到文件中,并使用 CyclicBarrier 控制线程的输出顺序。具体来说,当一个线程写入完一个数字后,调用 barrier.await() 方法等待其他线程写入完毕,然后再进行下一次的写入。
最终,在所有数据处理完成后,我们关闭文件输出流,并输出输出文件的路径。
在上面的代码中,线程的输出顺序无法得到保证,因为我们只是使用 CyclicBarrier 控制了线程的执行顺序,并不能保证线程写入文件的顺序。正确的做法是使用 Semaphore 来实现线程的同步和顺序。
下面是一个示例代码,可以实现将给定一组有序数据分成3等分,然后让3个线程 A、B、C 分别处理并将结果写入文件中,保证线程 A、B、C 的输出顺序,并输出文件路径。
以下是代码的高亮显示:
package demo;
import com.google.common.collect.Lists;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.*;
public class WriteSortNumberFileMain {
private static final int NUM_THREADS = 3;
public static void main(String[] args) throws IOException, InterruptedException {
int[] data = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
String filePath = "output.txt";
FileWriter fileWriter = new FileWriter(filePath);
BufferedWriter writer = new BufferedWriter(fileWriter);
Semaphore[] semaphores = new Semaphore[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; i++) {
semaphores[i] = new Semaphore(1);
if (i != 0) {
semaphores[i].acquire();
}
}
ExecutorService executorService = Executors.newFixedThreadPool(NUM_THREADS);
int chunkSize = data.length / NUM_THREADS;
List<Future<?>> futureList = Lists.newArrayList();
for (int i = 0; i < NUM_THREADS; i++) {
int start = i * chunkSize;
int end = (i == NUM_THREADS - 1) ? data.length : (i + 1) * chunkSize;
int[] chunk = Arrays.copyOfRange(data, start, end);
futureList.add(executorService.submit(new Worker(chunk, writer, semaphores[i], semaphores[(i + 1) % NUM_THREADS])));
}
semaphores[0].release();
futureList.forEach(item-> {
try {
item.get();
} catch (Throwable e) {
e.printStackTrace();
}
});
writer.flush();
fileWriter.close();
writer.close();
executorService.shutdown();
System.out.println("Output file path: " + filePath);
}
private static class Worker implements Runnable {
private final int[] data;
private final BufferedWriter writer;
private final Semaphore currentSemaphore;
private final Semaphore nextSemaphore;
public Worker(int[] data, BufferedWriter writer, Semaphore currentSemaphore, Semaphore nextSemaphore) {
this.data = data;
this.writer = writer;
this.currentSemaphore = currentSemaphore;
this.nextSemaphore = nextSemaphore;
}
@Override
public void run() {
try {
currentSemaphore.acquire();
for (int i : data) {
writer.write(i + " ");
}
nextSemaphore.release();
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
}
}在上面的代码中,我们使用了 Semaphore 来控制线程的执行顺序和输出顺序。首先,我们创建了一个大小为 3 的 Semaphore 数组,用于控制线程的执行顺序。线程 A、B、C 分别使用 semaphores[0]、semaphores[1]、semaphores[2] 控制执行顺序,当一个线程完成输出后,它会释放 nextSemaphore,等待 currentSemaphore 被其他线程释放后再进行下一次输出。具体来说,一个线程在输出一次后,会先 acquire currentSemaphore,然后输出一个数字,再 release nextSemaphore,等待下一个数字的输出。
在主线程中,我们首先将 semaphores[0] release,使得线程 A 可以开始执行。然后,我们在主线程中等待所有线程的 currentSemaphore 被释放,即所有线程的输出都完成后,再关闭文件输出流,并输出输出文件的路径。
需要注意的是,这里的实现仅仅是一种可能的解决方案,具体的实现方式可能因编程语言、应用场景等因素而异。
leetcode:
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
说明: 你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
解题思路:
利用异或的性质
x ^ x = 0
0 ^ x = x,相同为0,相异为1,通过异或相同的数抵消掉了,剩下一个多余的数。
代码实现:
class Solution {
public int singleNumber(int[] nums) {
int res=0;
for(int num:nums){
res ^= num;
}
return res;
}
}
这是一个经典的字符串问题,可以使用滑动窗口算法来解决。具体来说,我们可以使用两个指针i和j来表示当前子串的左右边界,初始时i和j都为0。然后,我们不断地将j向右移动,直到遇到重复字符为止。此时,我们就找到了以i为左边界的最长无重复字符的子串。接着,我们将i向右移动一位,缩小子串的范围,直到子串中不再包含重复字符为止。这样,我们就可以依次找到以每个字符作为左边界的最长无重复字符的子串,并取其中最长的那个作为结果。
Java 代码的实现:
public int lengthOfLongestSubstring(String s) {
if (s == null || s.length() == 0) {
return 0;
}
Map<Character, Integer> map = new HashMap<>();
int l = 0, r = 0, len = s.length(), size = 0;
while (r < len) {
if (map.containsKey(s.charAt(r))) {
l = Math.max(l, map.get(s.charAt(r)) + 1);
}
map.put(s.charAt(r), r);
r++;
size = Math.max(size, r - l);
}
return size;
}
在上面的代码中,我们先判断字符串 s 是否为空或者长度为 0,如果是则直接返回 0。然后,我们使用一个 HashMap 来记录每个字符上一次出现的位置。我们使用两个指针 l 和 r 来表示当前子串的左右边界,初始时 l 和 r 都为 0。在每次移动 r 的过程中,我们判断字符 s.charAt(r) 是否出现过。如果出现过,我们将左边界 l 移动到重复字符上一次出现的位置的下一位,然后更新该字符的位置。如果没有出现过,我们将该字符和它的位置加入到 HashMap 中,并更新最长子串的长度。最后,我们将 r 向右移动一位,继续遍历字符串 s。
需要注意的是,这种方法的时间复杂度是 O(n),其中 n 是字符串 s 的长度,因为我们最多只需要遍历一次字符串 s。而且它只需要使用一个 HashMap 来记录每个字符上一次出现的位置,因此空间复杂度是 O(min(n, m)),其中 m 是字符集的大小。
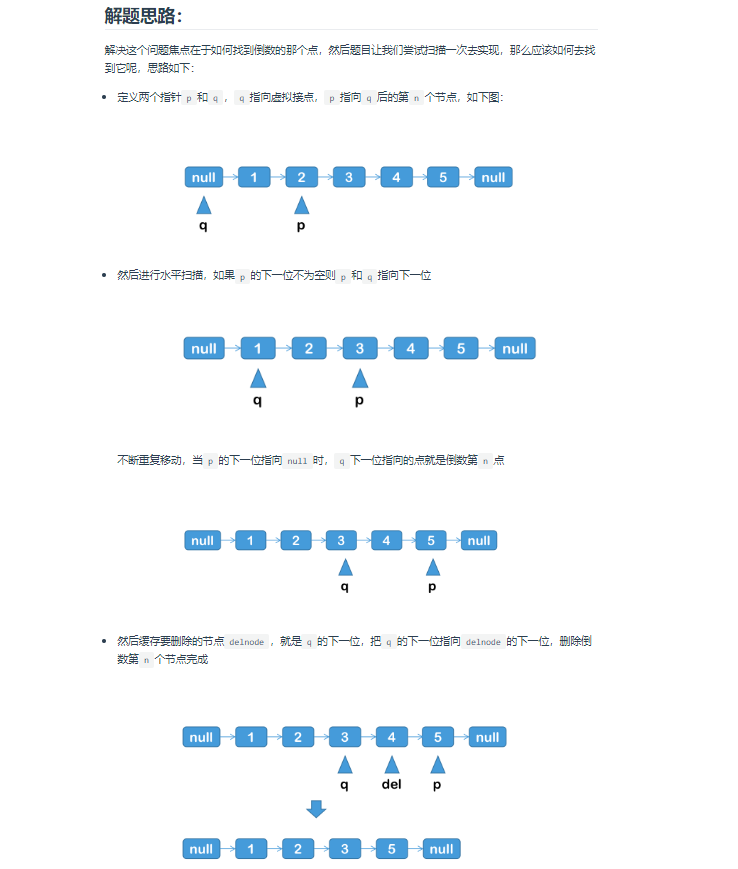
删除链表的倒数第N个节点:
要删除链表的倒数第N个节点,可以使用双指针算法。
算法步骤如下:
- 定义两个指针
p和q,初始时都指向链表的头节点。 - 将
p指针向前移动N步。如果此时p指向空节点,则说明要删除的是头节点,直接返回头节点的下一个节点即可。 - 将
p和q指针同时向前移动,直到p指向空节点。此时q指向的节点即为要删除的节点的前一个节点。 - 将
q的next指针指向要删除节点的下一个节点,完成删除操作。
下面是 Java 代码实现:
class ListNode {
int val;
ListNode next;
ListNode(int val) {
this.val = val;
}
}
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode p = dummy, q = dummy;
for (int i = 0; i < n; i++) {
p = p.next;
}
while (p.next != null) {
p = p.next;
q = q.next;
}
q.next = q.next.next;
return dummy.next;
}
这个 Java 代码中同样使用了虚拟头节点 dummy,这样我们就不需要特判要删除的是头节点的情况。
好的,下面给出一个测试用例。
public static void main(String[] args) {
// 创建链表 1 -> 2 -> 3 -> 4 -> 5
ListNode head = new ListNode(1);
head.next = new ListNode(2);
head.next.next = new ListNode(3);
head.next.next.next = new ListNode(4);
head.next.next.next.next = new ListNode(5);
// 删除链表倒数第2个节点,即节点4
head = removeNthFromEnd(head, 2);
// 遍历链表,输出 1 -> 2 -> 3 -> 5
ListNode p = head;
while (p != null) {
System.out.print(p.val + " -> ");
p = p.next;
}
System.out.println("null");
}
这个测试用例中,我们创建了一个链表 1 -> 2 -> 3 -> 4 -> 5,然后删除链表倒数第2个节点,即节点4,最后遍历链表,输出 1 -> 2 -> 3 -> 5,验证删除操作的正确性。
InnoDB 是 MySQL 的一种存储引擎,它的底层数据结构采用 B+ 树来实现索引。B+ 树是一种多路搜索树,它的每个节点可以存储多个关键字和对应的指针,因此它能够在读取大量数据时,减少 I/O 操作,提高查询效率。B+ 树相比于 B 树,具有以下优点:
- 减少磁盘 I/O 次数:B+ 树的非叶子节点只存储关键字,不存储数据,而叶子节点则按照顺序存储关键字和对应的数据。这样可以减少磁盘 I/O 次数,提高查询效率。
- 提高查询效率:B+ 树的叶子节点形成一个有序链表,可以进行范围查询和排序操作。
- 更好的磁盘块利用率:B+ 树的每个节点可以存储多个关键字和对应的指针,因此每个磁盘块可以存储更多的数据,提高了磁盘块的利用率。
- 更容易实现高效的范围查询:因为 B+ 树的叶子节点形成有序链表,所以可以很容易地实现高效的范围查询。
B 树与 B+ 树的主要区别在于,B 树的非叶子节点和叶子节点都可以存储数据,而 B+ 树的非叶子节点只存储关键字,叶子节点按照顺序存储关键字和对应的数据。相比之下,B+ 树更适合用于实现高效的数据库索引。B 树相对于 B+ 树的优点是,它在进行查询时,每个节点都可以进行数据查找,因此对于数据量较小的情况下,它的查询效率可能会高于 B+ 树。但是,随着数据量的增加,B 树的查询效率会逐渐降低。
总的来说,InnoDB 选择 B+ 树作为索引的底层数据结构,是因为 B+ 树能够更好地支持范围查询、排序和减少磁盘 I/O 操作等操作,能够更好地满足数据库系统的需求。
0 条评论