本文是技术人面试系列个人项目篇,作者总结了一些自己的实战项目经验
双人对战答题、公司对战抢答。
1、如何设计排行榜
-
个人总得分和总排名实时更新;
-
个人排行榜按分数、时间、次数、正确率展示;
-
日榜、过去N日榜滚动更新;
性能优化过程
最终结果:
-
高效快速:能在数百毫秒内找到玩家排名以及进行更新
-
强一致性以及持久化、排名准确
-
可以扩展到任意数量的玩家
-
吞吐量有限制,只能支持约每秒 500次更新。
方案优化过程
方案1:每日一个滚动榜,当日汇聚(费时间)
方案2:全局N个滚动榜同时写(费空间)
方案3:实时更新,常数次写操作
2、如何解决重复答题
利用setnx防止重复答题
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。 利用Redis的单线程特性对共享资源进行串行化处理。
// 获取锁推荐使用set的方式String result = jedis.set(lockKey, requestId, "NX", "EX", expireTime)// 推荐使用redis+lua脚本String lua = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";Object result = jedis.eval(lua, Collections.singletonList(lockKey)3、一个题目被多个人抢答
2、获取Corp:Activ:Qust: 的值,创建redis事务,给这个key的值-1;
3、执行这个事务,如果key的值被修改过则回滚,key不变;
4、如何管理昵称重复
-
使用 K 个哈希函数对元素值进行 K 次计算,得到 K 个哈希值。
-
根据得到的哈希值,在位数组中把对应下标的值置为 1。 Na
5、如何管理出题定时任务
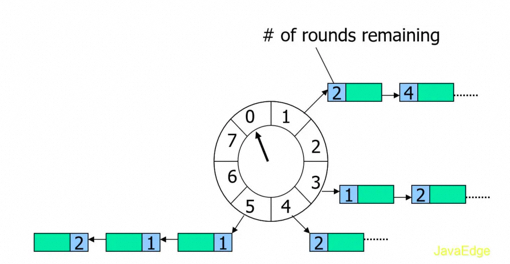
-
将缓存在 timeouts 队列中的定时任务转移到时间轮中对应的槽中
-
根据当前指针定位对应槽,处理该槽位的双向链表中的定时任务,从链表头部开始迭代:
-
属于当前时钟周期则取出运行
-
不属于则将其剩余的时钟周期数减一
-
检测时间轮的状态。如果时间轮处于运行状态,则循环执行上述步骤,不断执行定时任务。
6、如何解决客户端断连
技术选型
方案设计
-
秒杀业务简单,每个秒杀活动的商品是事先定义好的,商品有明确的类型和数量,卖完即止;
-
秒杀活动定时上架,消费者可以在活动开始后,通过秒杀入口进行抢购秒杀活动;
-
秒杀活动由于商品物美价廉,开始售卖后,会被快速抢购一空;
-
秒杀活动持续时间短,访问冲击量大,秒杀系统需要应对这种爆发性的访问模型;
-
业务的请求量远远大于售卖量,大部分是陪跑的请求,秒杀系统需要提前规划好处理策略;
-
前端访问量巨大,系统对后端数据的访问量也会短时间爆增,对数据存储资源进行良好设计;
-
活动期间会给整个业务系统带来超大负荷,需要制定各种策略,避免系统过载而宕机;
-
售卖活动商品价格低廉,存在套利空间,各种非法作弊手段层出,需要提前规划预防策略;
1、如何解决超卖?
纯数据库乐观锁+事务的方式性能比较差,但是如果不计成本和考虑场景的话也完全够用,因为任何没有机器配置的指标,都是耍流氓。如果我采用 Oracle 的数据库、100 多核的刀锋服务器、SSD 的硬盘,即使是纯数据库的扣减方案,也是可以达到单机上万的 TPS 的。
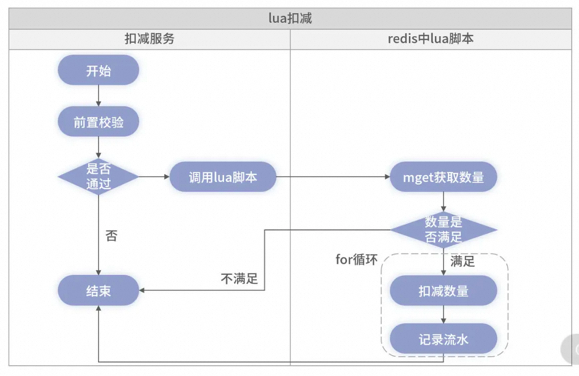
纯缓存方案虽不会导致超卖,但因缓存不具备事务特性,极端情况下会存在缓存里的数据无法回滚,导致出现少卖的情况。且架构中的异步写库,也可能发生失败,导致多扣的数据丢失。
2、如何解决重复下单?
mysql唯一索引+分布式锁
3、如何防刷?
IP限流 | 验证码 | 单用户 | 单设备 | IMEI | 源IP |均设置规则
4、热key问题如何解决?
1、缓存集群可以单节点进行主从复制和垂直扩容;
2、利用应用内的前置缓存,但是需注意需要设置上限;
3、延迟不敏感,定时刷新,实时感知用主动刷新;
4、和缓存穿透一样,限制逃逸流量,单请求进行数据回源并刷新前置;
5、应对高并发的读请求
-
计数器限流,例如5秒内技术1000请求,超数后限流,未超数重新计数;
-
滑动窗口限流,解决计数器不够精确的问题,把一个窗口拆分多滚动窗口;
-
令牌桶限流,类似景区售票,售票的速度是固定的,拿到令牌才能去处理请求;
-
漏桶限流,生产者消费者模型,实现了恒定速度处理请求,能够绝对防止突发流量;
流量控制效果从好到差依次是:漏桶限流 > 令牌桶限流 > 滑动窗口限流 > 计数器限流; 其中,只有漏桶算法真正实现了恒定速度处理请求,能够绝对防止突发流量超过下游系统承载能力。
不过,漏桶限流也有个不足,就是需要分配内存资源缓存请求,这会增加内存的使用率。而令牌桶限流算法中的“桶”可以用一个整数表示,资源占用相对较小,这也让它成为最常用的限流算法。正是因为这些特点,漏桶限流和令牌桶限流经常在一些大流量系统中结合使用。
6、应对高并发的写请求
-
削峰:恶意用户拦截
对于单用户多次点击、单设备、IMEI、源IP均设置规则;
-
采用比较成熟的漏桶算法、令牌桶算法,也可以使用guava开箱即用的限流算法;
可以集群限流,但单机限流更加简洁和稳定;
-
当前层直接过滤一定比例的请求,最大承载值前需要加上兜底逻辑;
-
对于已经无货的产品,本地缓存直接返回;
-
单独部署,减少对系统正常服务的影响,方便扩缩容;
-
削去秒杀场景下的峰值写流量——流量削峰
-
通过异步处理简化秒杀请求中的业务流程——异步处理
-
解耦,实现秒杀系统模块之间松耦合——解耦
-
将秒杀请求暂存于消息队列,业务服务器响应用户“秒杀结果正在处理中。。。”,释放系统资源去处理其它用户的请求。
-
削峰填谷,削平短暂的流量高峰,消息堆积会造成请求延迟处理,但秒杀用户对于短暂延迟有一定容忍度。秒杀商品有 1000 件,处理一次购买请求的时间是 500ms,那么总共就需要 500s 的时间。这时你部署 10 个队列处理程序,那么秒杀请求的处理时间就是 50s,也就是说用户需要等待 50s 才可以看到秒杀的结果,这是可以接受的。这时会并发 10 个请求到达数据库,并不会对数据库造成很大的压力。
-
如主要流程是生成订单、扣减库存;
-
次要流程比如购买成功之后会给用户发优惠券,增加用户的积****分。
-
此时秒杀只要处理生成订单,扣减库存的耗时,发放优惠券、增加用户积分异步去处理了。
-
使用 HTTP 或者 RPC 同步调用,即提供一个接口,实时将数据推送给数据服务。系统的耦合度高,如果其中一个服务有问题,可能会导致另一个服务不可用。
-
使用消息队列将数据全部发送给消息队列,然后数据服务订阅这个消息队列,接收数据进行处理。
7、如何保证数据一致性
// 延迟双删,用以保证最终一致性,防止小概率旧数据读请求在第一次删除后更新数据库
public void write(String key,Object data){
redis.delKey(key);
db.updateData(data);
Thread.sleep(1000);
redis.delKey(key);
}-
更新数据库数据; -
数据库会将操作信息写入binlog日志当中; -
另起一段非业务代码,程序订阅提取出所需要的数据以及key; -
尝试删除缓存操作,若删除失败,将这些信息发送至消息队列; -
重新从消息队列中获得该数据,重试操作;
-
先删缓存,将更新数据库的写操作放进有序队列中 -
从缓存查不到的读操作也进入有序队列
-
读请求积压,大量超时,导致数据库的压力:限流、熔断 -
如何避免大量请求积压:将队列水平拆分,提高并行度。
8、可靠性如何保障
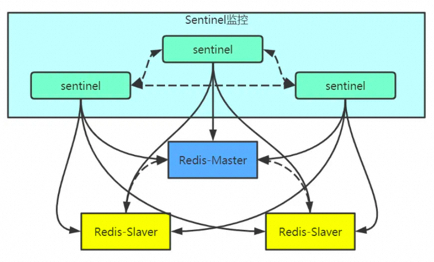
9、秒杀系统瓶颈-日志
秒杀服务单节点需要处理的请求 QPS 可能达到 10 万以上。一个请求从进入秒杀服务到处理失败或者成功,至少会产生两条日志。也就是说,高峰期间,一个秒杀节点每秒产生的日志可能达到 30 万条以上。
-
每秒日志量远高于磁盘 IOPS,直接写磁盘会影响服务性能和稳定性 -
大量日志导致服务频繁分配,频繁释放内存,影响服务性能。 -
服务异常退出丢失大量日志的问题
-
Tmpfs,即临时文件系统,它是一种基于内存的文件系统。我们可以将秒杀服务写日志的文件放在临时文件系统中。相比直接写磁盘,在临时文件系统中写日志的性能至少能提升 100 倍,每当日志文件达到 20MB 的时候,就将日志文件转移到磁盘上,并将临时文件系统中的日志文件清空;
-
可以参考内存池设计,将给logger分配缓冲区,每一次的新写可以复用Logger对象;
-
参考kafka的缓冲池设计,当缓冲区达到大小和间隔时长临界值时,调用Flush函数,减少丢失的风险;
1、单聊消息可靠传输
-
请求报文(request,后简称为为R),客户端主动发送给服务端。
-
应答报文(acknowledge,后简称为A),服务器被动应答客户端的报文。
-
通知报文(notify,后简称为N),服务器主动发送给客户端的报文
A 消息请求 MSG:R => S 消息应答 MSG:A => S 消息通知B MSG:N
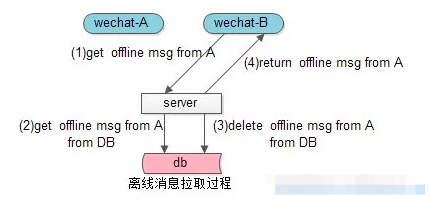
图片来源于网络
-
如用户勾选全量则返回计数,在用户点击时拉取。 -
如用户未勾选全量则返回最近全部离线消息,客户端针对用户id进行计算。 -
全量离线信息可以通过客户端异步线程分页拉取,减少卡顿 -
将ACK和分页第二次拉取的报文重合,可以较少离线消息拉取交互的次数
2、群聊消息如何保证不丢不重
在线的群友能第一时间收到消息;
离线的群友能在登陆后收到消息。
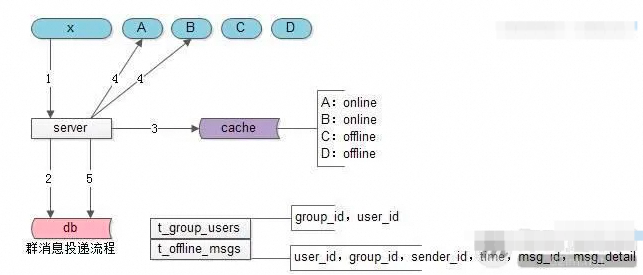
图片来源于网络
-
群消息发送者x向server发出群消息;
-
server去db中查询群中有多少用户(x,A,B,C,D);
-
server去cache中查询这些用户的在线状态;
-
对于群中在线的用户A与B,群消息server进行实时推送;
-
对于群中离线的用户C与D,群消息server进行离线存储。
-
离线消息表只存储用户的群离线消息msg_id,降低数据库的冗余存储量;
-
加入应用层的ACK,才能保证群消息一定到达,服务端幂等性校验及客户端去重,保证不重复;
-
每条群消息都ACK,会给服务器造成巨大的冲击,通过批量ACK减少消息风暴扩散系数的影响;
-
群离线消息过多:拉取过慢,可以通过分页懒拉取改善。
3、如何保证消息的时序性
-
Id通过借鉴微信号段+跳跃的方式保证趋势递增;
-
单聊借鉴数据库设计,单点序列化同步到其他节点保证多机时序;
-
群聊消息使用单点序列化保证各个发送者的消息相对时序;
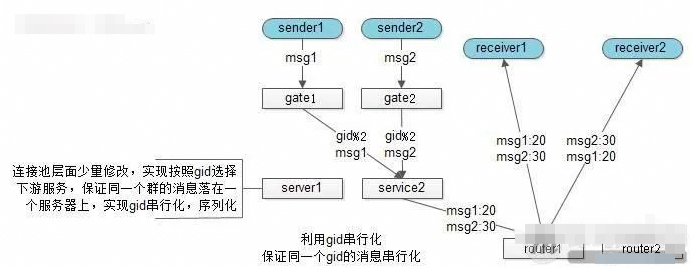
-
利用服务器单点序列化时序,可能出现服务端收到消息的时序,与发出序列不一致;
-
在A往B发出的消息中,加上发送方A本地的一个绝对时序,来表示接收方B的展现时序;
-
群聊消息保证一个群聊落在一个service上然后通过本地递增解决全局递增的瓶颈问题;
4、推拉结合
-
服务器在缓存集群里存储所有用户的在线状态 -> 保证状态可查;
-
用户状态实时变更,任何用户登录/登出时,需要推送所有好友更新状态;
-
A登录时,先去数据库拉取自己的好友列表,再去缓存获取所有好友的在线状态;
-
好友状态推拉结合,首页置顶亲密、当前群聊,采用推送,否则可以采用轮询拉取的方式同步;
-
群友的状态,由于消息风暴扩散系数过大,可以采用按需拉取,延时拉取的方式同步;
-
系统消息/开屏广告等这种实时产生的消息,可以采用推送的方式获取消息;
5、好友推荐
物联网架构
物联网是互联网的外延。将用户端延伸和扩展到物与人的连接。物联网模式中,所有物品与网络连接,并进行通信和场景联动。互联网通过电脑、移动终端等设备将参与者联系起来,形成的一种全新的信息互换方式。
DCM系统架构
-
设备感知层(Device):利用射频识别、二维码、传感器等技术进行数据采集; -
网络传输层(Connect):依托通信网络和协议,实现可信的信息交互和共享; -
应用控制层(Manage):分析和处理海量数据和信息,实现智能化的决策和控制;
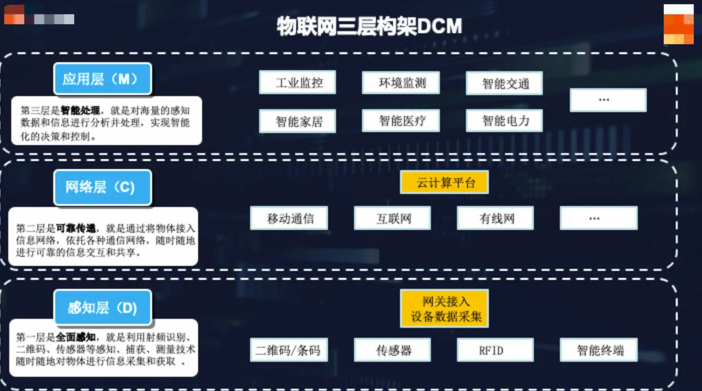
三要素
-
设备联网:通过不同的网络协议和通信标准,实现设备与控制端的连接;
-
云端分析:提供监控、存储、分析等数据服务,以及保障客户的业务数据安全;
-
云边协同:云端接受设备上报数据,下发设备管控指令;
云 / 边 / 端协同
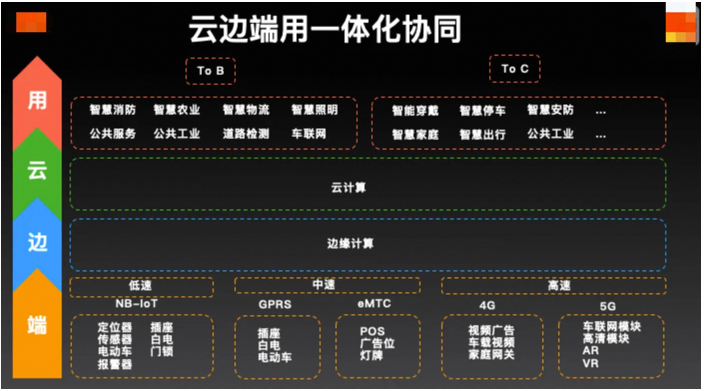
物联网平台接入
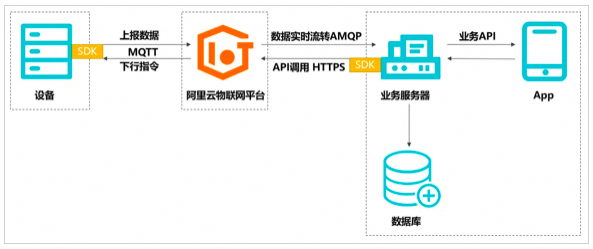
-
设备建立MQTT长连接,上报数据(发布Topic和Payload)到物联网平台; -
物联网平台通过配置规则,通过RocketMQ、AMQP等队列转发到业务平台;
-
业务服务器基于HTTPS协议调用的API接口,发布Topic指令到物联网平台; -
物联网平台通过MQTT协议,使用发布(指定Topic和Payload)到设备端;
门锁接入

各种协议
-
由于必须由设备主动向服务器发送数据,难以主动向设备推送数据; -
物联网场景中的设备多样,运算受限的设备,难以实现JSON数据格式的解析;
简化了HTTP协议的RESTful API,它适用于在资源受限的通信的IP网络。
MQTT协议采用发布/订阅模式,物联网终端都通过TCP连接到云端,云端通过主题的方式管理各个设备关注的通讯内容,负责将设备与设备之间消息的转发。
用于业务系统例如PLM,ERP,MES等进行数据交换。
开源形式组织产生的网络即时通信协议。被IETF国际标准组织完成了标准化工作。
IOT流量洪峰
-
上下行拆分
上行消息特征:并发量高、可靠性和时延性要求低
下行消息特征:并发量低、控制指令的成功率要求高
-
海量Topic下性能
Kafka海量Topic性能会急剧下降,Zookeeper协调也有瓶颈
多泳道消息队列可以实现IoT消息队列的故障隔离
-
实时消息优先处理
NB门禁实时产生的开门指令必须第一优先级处理,堆积的消息降级
设计成无序、不持久化的,并与传统的FIFO队列隔离
-
连接、计算、存储分离
Broker只做流转分发,实现无状态和水平扩展
计算交给Flink,存储交给nosqlDB,实现高吞吐写
-
消息策略-推拉结合
MQTT针对电池类物联网设备,AMQP针对安全性较高的门禁设备
消费端离线时存到queue,在线时将实时消息和从queue中拉取的消息一起推送
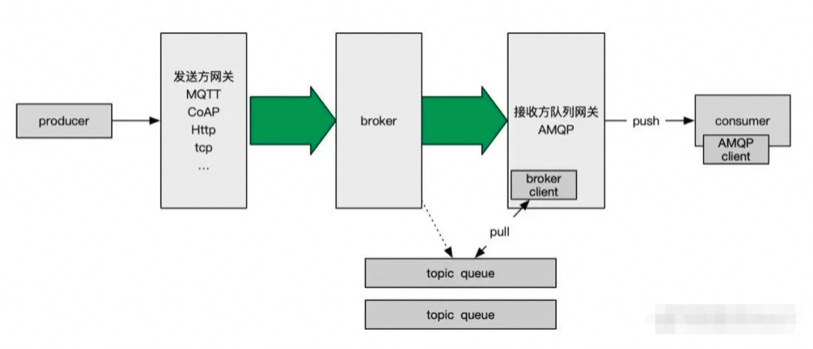
图片来源于网络
-
人工Sharding:部署多个Kafka集群,通过不同mq连接来隔离; -
合并Topic,客户端封装subTopic。比如一个服务的N个统计项,会消费到无关消息; 基于这个思路,使用Kafka Streams或者Hbase列存储来聚合;
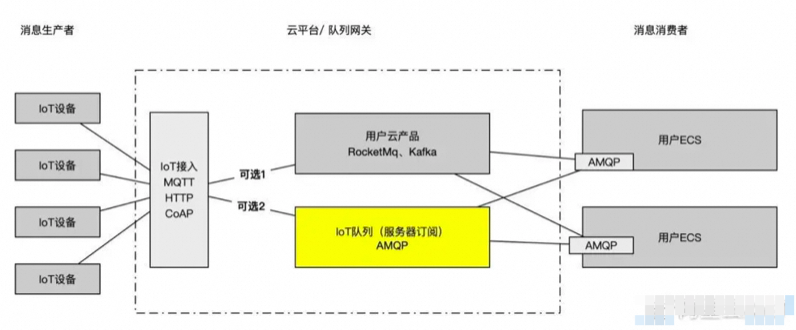
图片来源于网络
社区直播带货
使用端 / 边 / 云三级架构,客户端加密传输,边缘节点转发、云侧转码并持久化。
产品的背景
上线时间,从调研到正式上线用了 3个月时间,上线后一个月内就要经历双十二挑战。在这么紧的上线时间要求下,需要用到公司提供的所有优势,包括cdn网络,直播牌照等。
面临的挑战
-
直播数据是实时生成的,所有不能够进行预缓存;
-
直播随时会发生,举办热点活动,相关服务器资源需要动态分配;
-
直播的延迟对于用户体验影响很大,需要控制在秒级;
-
直播sdk是内嵌在社区应用里的,整体要求不能超过5M;
协议的比较
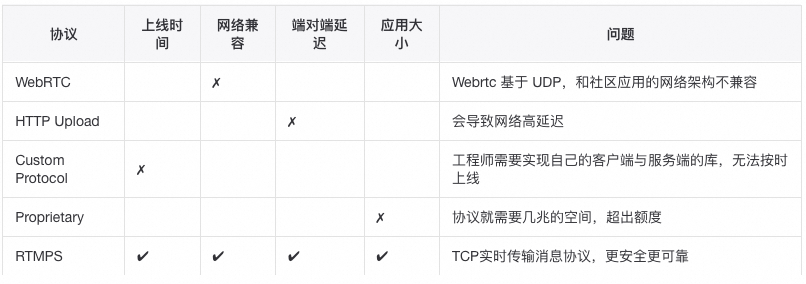
整体流程
-
直播端使用 RTMPS 协议发送直播数据到边缘节点(POP) -
POP 使用RTMP发送数据到数据中心(DC) -
DC 将数据编码成不同的清晰度并进行持久化存储 云端转码主要有两种分辨率400×400 和 720×720. -
播放端通过 MPEG-DASH / RTMPS 协议接收直播数据
如果用户网络不好MPEG-DASH会自动转换成低分辨率
直播流程
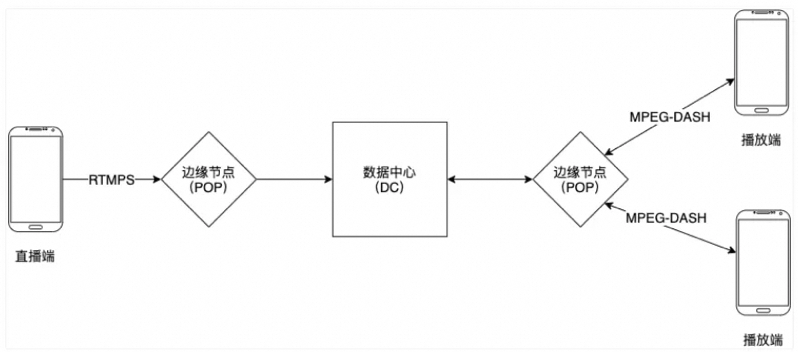
-
直播端使用 RTMPS 协议发送直播流数据到 POP 内的就近的代理服务器;
-
代理服务器转发直播流数据到数据中心的网关服务器(443转80);
-
网关服务器使用直播 id 的一致性哈希算法发送直播数据到指定的编码服务器;
-
编码服务器有几项职责:
-
4.1 验证直播数据的格式是否正确;
-
4.2 关联直播 id 以及编码服务器第一映射,保证客户端即使连接中断或者服务器扩容时,在重新连接的时候依然能够连接到相同的编码服务器;
-
4.3 使用直播数据编码成不同解析度的输出数据;
-
4.4 使用 DASH 协议输出数据并持久化存储;
播放流程
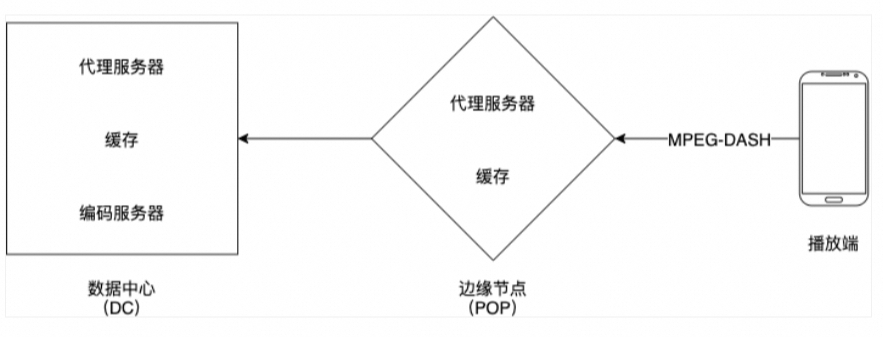
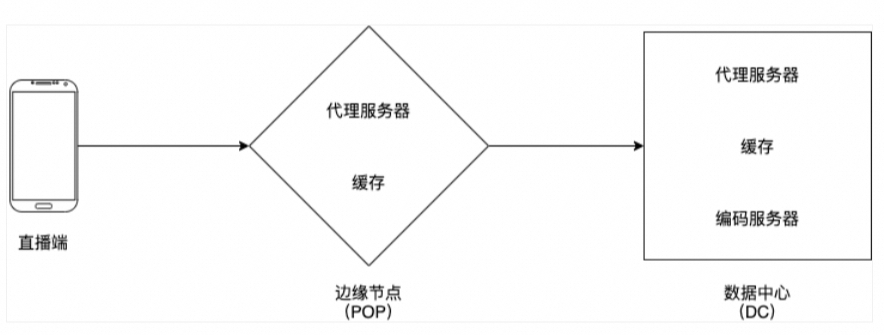
-
播放端使用 HTTP DASH 协议向 POP 拉取直播数据;
-
POP 里面的代理服务器会检查数据是否已经在 POP 的缓存内。如果是的话,缓存会返回数据给播放端,否则,代理服务器会向 DC 拉取直播数据;
-
DC 内的代理服务器会检查数据是否在 DC 的缓存内,如果是的话,缓存会返回数据给 POP,并更新 POP 的缓存,再返回给播放端。不是的话,代理服务器会使用一致性哈希算法向对应的编码服务器请求数据,并更新 DC 的缓存,返回到 POP,再返回到播放端;
-
项目的成功不,代码只是内功,考虑适配不同的网络、利用可利用的资源; -
惊群效应在热点服务器以及许多组件中都可能发生; -
开发大型项目需要对吞吐量和时延、安全和性能做出妥协; -
保证架构的灵活度和可扩展性,为内存、服务器、带宽耗尽做好规划;
直播高可用方案
-
根据网络连接速度来自动调整视频质量;
-
使用短时间的数据缓存来解决直播端不稳定,瞬间断线的问题;
-
根据网络质量自动降级为音频直播以及播放;
-
当多个播放端向同一个 POP 请求直播数据的时候,如果数据不在缓存中;
-
这时候只有一个请求 A 会到 DC 中请求数据,其他请求会等待结果;
-
但是如果请求 A 超时没有返回数据的话,所有请求会一起向 DC 访问数据;
-
这时候就会加大 DC 的压力,触发惊群效应;
-
解决这个问题的方法就是通过实际的情况来调整请求超时的时间。这个时间如果太长的话会带来直播的延迟,太短的话会经常触发惊群效应(每个时间窗口只允许触发一次,设置允许最大回源数量);
性能优化方案
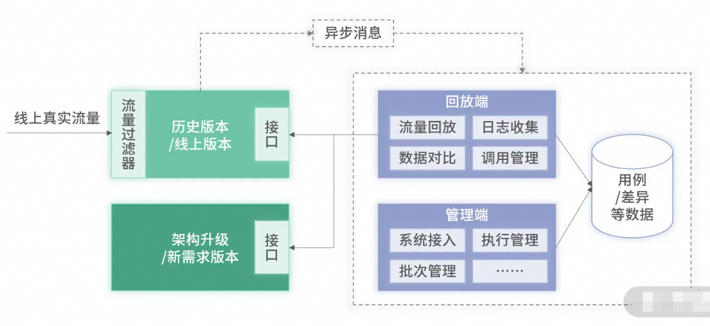
流量回放自动化测试
系统级的重构,测试回归的工作量至少都是以月为单位,对于人力的消耗巨大。一种应对方案是,先不改造,到系统实在扛不住了再想办法。另一种应对方案是,先暂停需求,全力进行改造。但在实际工作场景中,上述应对策略往往很难实现。
1、读服务均是查询,它是无状态的。
图片来源于网络
-
日志收集,主要作用是收集被测系统的真实用户请求,基于一定规则处理后作为系统用例;
Spring 里的 Interceptor 、Servlet 里的 Filter 过滤器,对所有请求的入参和出参进行记录,并通过 MQ 发送出去。(注意错峰、过滤写、去重等)。
-
数据回放是基于收集的用例,对被测系统进行数据回放,发起自动化测试回归;
离线回放:只调用新服务,将返回的数据和日志里的出参进行比较,日志比较大
实时回放:去实时调用线上系统和被测系统,并存储实时返回回放的结果信息,线上有负担。
并行回放:新版本不即时上线,每次调用老版本接口时概率实时回放新版本接口,耗时间周期。
-
差异对比,通过差异对比自动发现与预期不一致的用例,进而确定 Bug。 采用文本对比,可以直观地看到哪个字段数据有差异,从而更快定位到问题。正常情况下,只要存在差异的数据,均可认为是 Bug,是需要进行修复的。
0 条评论