本文全面阐述了容器技术的发展历程、关键技术、架构和当前的行业生态,特别是容器技术在云环境中的应用和演进。
什么是容器?
容器是一种虚拟化技术,用于封装应用程序及其所有依赖项和配置,以便能够在不同的计算机环境中运行。软件容器提供了一种轻量级、一致性的运行环境,使得应用程序在开发、测试和部署时更加可移植和可靠。
容器的特点
1.跨平台性: 容器可以在不同的操作系统和云平台上运行,确保应用程序在各种环境中的一致性。这种跨平台性使得应用程序更易于移植和部署。
2.一致性和可重复性: 容器封装了应用程序及其所有依赖项和配置,确保了开发、测试和生产环境的一致性。通过使用容器,可以避免由于环境差异而引起的问题,实现可重复的构建和部署过程。
3.资源隔离: 容器提供了一定程度的隔离,使得多个容器可以在同一主机上并行运行而互不干扰。这种隔离性能够确保应用程序的稳定性和安全性。
4.快速部署和启动: 容器可以在几秒钟内启动,相比于传统的虚拟机来说,启动时间更短。这使得应用程序的部署和扩展更加迅速和灵活。
5.高可伸缩性: 容器架构支持自动化的横向扩展,可以根据需求动态地增加或减少容器实例。这种高可伸缩性使得应用程序能够更好地应对流量和负载的变化。
6.环境隔离: 容器提供了独立的运行环境,每个容器都有自己的文件系统、网络和进程空间。这种环境隔离有助于防止应用程序之间的相互影响,提高了系统的稳定性和安全性。
7.资源效率: 容器共享主机操作系统的内核,相比虚拟机,容器更加轻量级,更加节省系统资源。
8.持续集成和持续部署(CI/CD): 容器与持续集成和持续部署工具集成紧密,使得开发团队能够更容易地实现自动化构建、测试和部署流程。
虚拟化
1974 年波佩克和戈德堡在论文 《可虚拟第三代架构的规范化条件》 就明确提出了虚拟化系统结构的三个条件:
3.效率性(Efficiency):绝大多数的客户机指令应该由主机硬件直接执行而无需控制程序的参与。
依据以上条件,可以将虚拟化分为两种类型,就是当前流行的裸机型和主机型。
类型一(裸机型)(硬件虚拟化)
直接运行在物理硬件上,没有底层操作系统。这种类型通常用于企业级虚拟化平台,例如VMware ESXi和Microsoft Hyper-V。
类型二(主机型)(软件虚拟化)
运行在操作系统之上,类似于其他应用程序。这种类型通常用于开发和测试环境,例如Oracle VirtualBox和VMware Workstation。
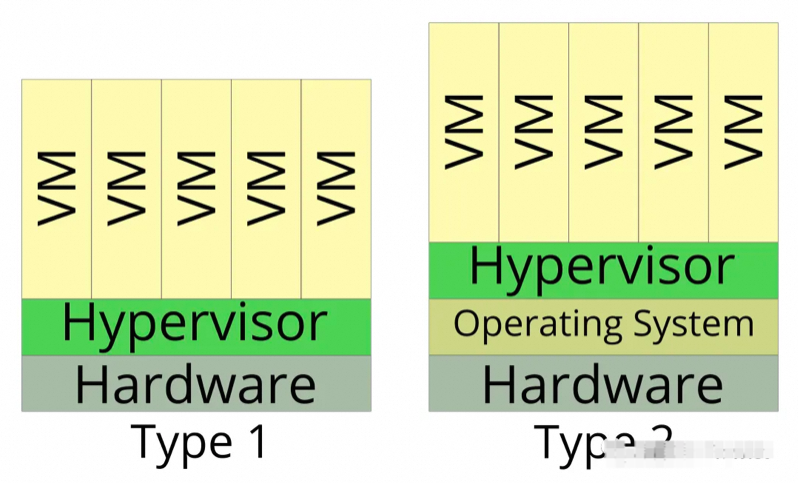
两种类型
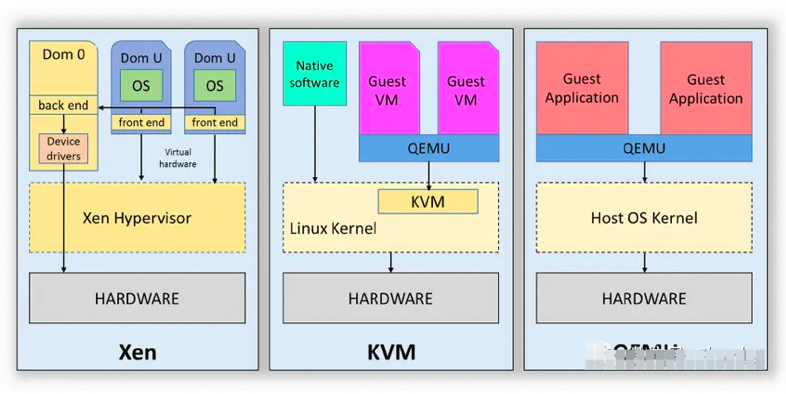
三种经典的实现方案
软件虚拟化(Type 2类型)
全软件模拟,运行在操作系统之上的,主要有以下特点:
5.隔离:Type 2 Hypervisor 创建的每个虚拟机都与其他虚拟机以及主机系统隔离。这使用户能够在受控环境中尝试不同的操作系统、配置和应用程序。
主要产品有 Type 2 Hypervisor 的常见示例包括:
3.Virtual PC 2004
硬件虚拟化(Type 1类型)
硬件虚拟化是一种将物理计算资源抽象和分隔,以创建多个独立的虚拟环境的技术。这种虚拟化的目标是在同一物理硬件上运行多个操作系统和应用程序,从而更有效地利用硬件资源。硬件虚拟化通常涉及使用称为虚拟机(VM)的软件层将物理硬件分隔成多个虚拟环境。
主要产品有 Type 1 Hypervisor 的常见示例包括:
4.KVM
从虚拟化到容器
容器化演进
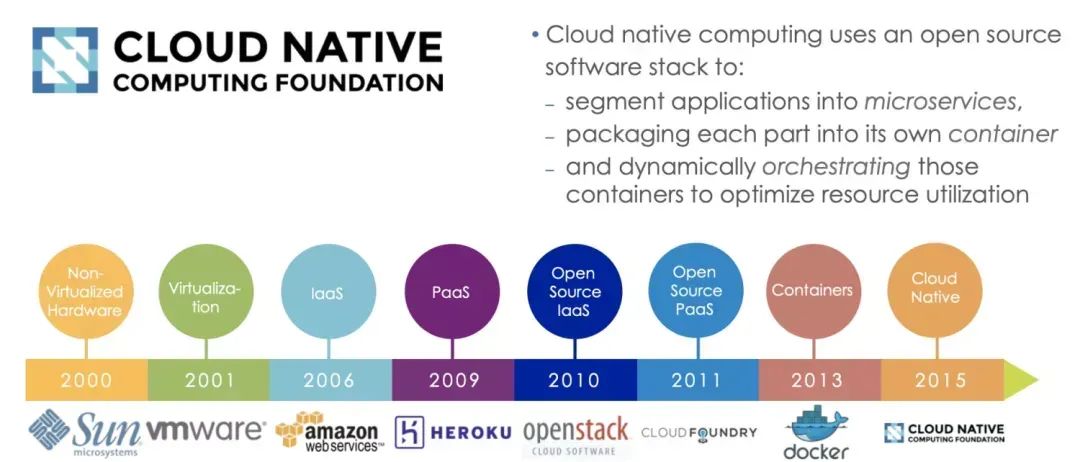
1979 年,Unix v7 系统支持 chroot,为应用构建一个独立的虚拟文件系统视图。1999 年,FreeBSD 4.0 支持 jail,第一个商用化的 OS 虚拟化技术。2004 年,Solaris 10 支持 Solaris Zone,第二个商用化的 OS 虚拟化技术。2005 年,OpenVZ 发布,非常重要的 Linux OS 虚拟化技术先行者。2004 年 - 2007 年,Google 内部大规模使用 Cgroups 等的 OS 虚拟化技术。2006 年,Google 开源内部使用的 process container 技术,后续更名为 cgroup。2008 年,Cgroups 进入了 Linux 内核主线。2008 年,LXC(Linux Container)项目具备了 Linux 容器的雏型。2011 年,CloudFoundry 开发 Warden 系统,一个完整的容器管理系统雏型。2013 年,Google 通过 Let Me Contain That For You (LMCTFY) 开源内部容器系统。2013 年,Docker 项目正式发布,让 Linux 容器技术逐步席卷天下。2014 年,Kubernetes 项目正式发布,容器技术开始和编排系统起头并进。2015 年,由 Google,Redhat、Microsoft 及一些大型云厂商共同创立了 CNCF,云原生浪潮启动。2016 年 - 2017 年,容器生态开始模块化、规范化。CNCF 接受 Containerd、rkt项目,OCI 发布 1.0,CRI/CNI 得到广泛支持。2017 年 - 2018 年,容器服务商业化。AWS ECS,Google EKS,Alibaba ACK/ASK/ECI,华为 CCI,Oracle Container Engine for Kubernetes;VMware,Redhat 和 Rancher 开始提供基于 Kubernetes 的商业服务产品。2017 年 - 2019 年,容器引擎技术飞速发展,新技术不断涌现。2017 年底 Kata Containers 社区成立, 2018 年 5 月 Google 开源 gVisor 代码,2018 年 11 月 AWS 开源 firecracker,阿里云发布安全沙箱 1.0。2020 年 - 202x 年,容器引擎技术升级,Kata Containers 开始 2.0 架构,阿里云发布沙箱容器 2.0....
容器的发展
容器技术近 20 年的发展历史,大致可以将其分为四个历史阶段。
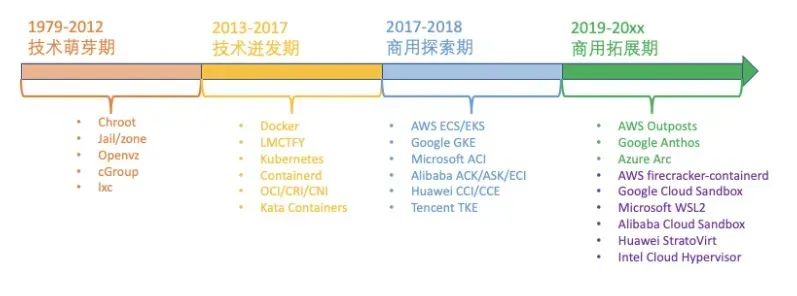
当前容器主要还是以k8s为主导的生态。
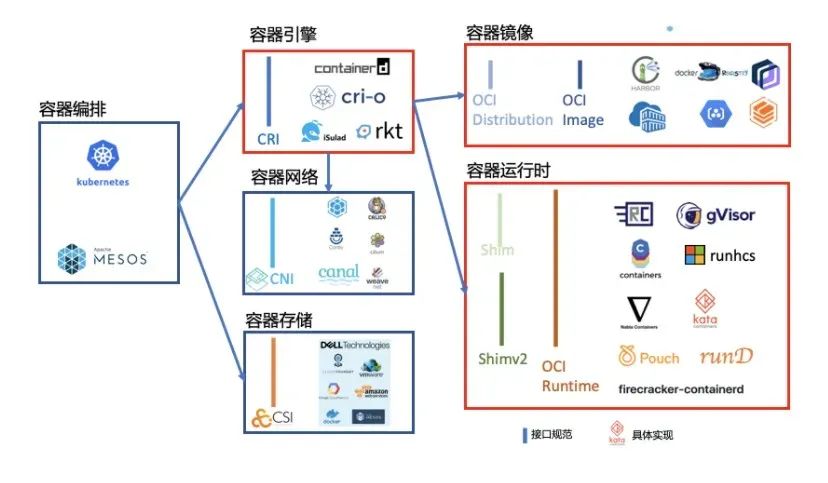
k8s生态
容器技术的基础
cgroup 资源控制器
cgroup介绍
Control Groups(cgroups)是 Linux 内核的一个功能,用于限制、账户和隔离进程组(包括它们的任务和资源)。cgroups提供了对系统资源(如CPU、内存、磁盘 I/O等)的精细控制,允许系统管理员将资源分配和限制应用到一组进程上,是google在2007年提出的,在2008年的时候合并到2.6的linux内核中。
主要有以下使用场景:
5.动态资源管理
cgroup技术初探
cgroup是由一个个的子系统构成的,比如cpu,memory等。
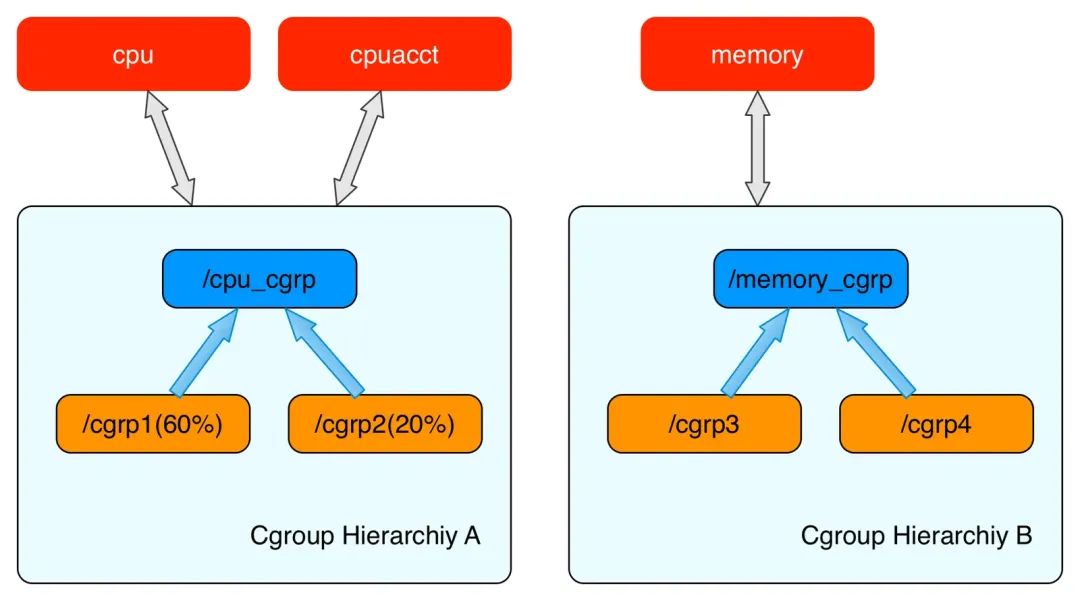
每一个层级结构中是一颗树形结构,树的每一个节点是一个cgroup结构体(比如cpu_cgrp, memory_cgrp)。第一个cgroups层级结构attach了cpu子系统和cpuacct子系统, 当前cgroups层级结构中的cgroup结构体就可以对cpu的资源进行限制,并且对进程的cpu使用情况进行统计。第二个cgroups层级结构attach了memory子系统,当前cgroups层级结构中的cgroup结构体就可以对memory的资源进行限制。
当前云安全中心的客户端使用cgroup已经超过2年的时间,大大提高了客户端的稳定性,减少对客户正常业务的影响。
namespace
Linux 的命名空间(namespace)提供了一种内核级别隔离系统资源的方法,通过将系统的全局资源放在不同的命名空间中以实现资源隔离的目的。
|
类型 |
描述 |
|
Cgroup |
Cgroup root directory cgroup 根目录 |
|
IPC |
System V IPC, POSIX message queues 信号量,消息队列 |
|
Network |
Network devices, stacks, ports, etc.网络设备,协议栈,端口等等 |
|
Mount |
Mount points 挂载点 |
|
PID |
Process IDs 进程号 |
|
User |
用户和组 ID |
|
UTS |
系统主机名和 NIS(Network Information Service) 主机名(有时称为域名) |
|
Time |
时钟 |
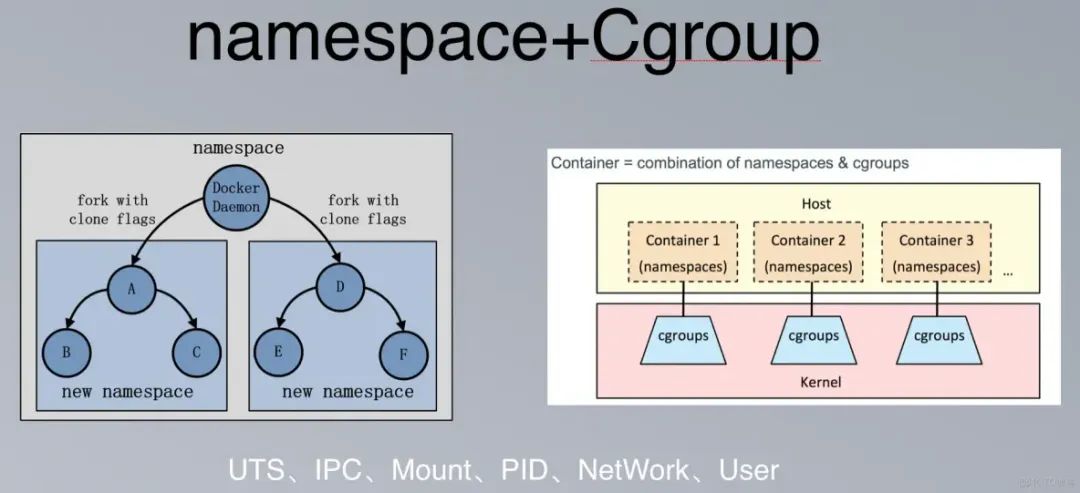
容器网络
网络虚拟化
虚拟化容器是以 Linux 名称(namespace)空间的隔离性为基础来实现的,那解决隔离的容器之间、容器与宿主机之间、乃至跨物理网络的不同容器间通信问题的责任,很自然也落在了 Linux 网络虚拟化技术的肩上。
Linux 网络虚拟化的主要技术是 Network Namespace,以及各类虚拟设备,例如 Veth、Linux Bridge、tap/tun 等,虚拟化的本质是现实世界的映射,这些虚拟设备像现实世界中的物理设备一样彼此协作,将各个独立的 namespace 连接起来,构建出不受物理环境局限的各类网络拓扑架构。
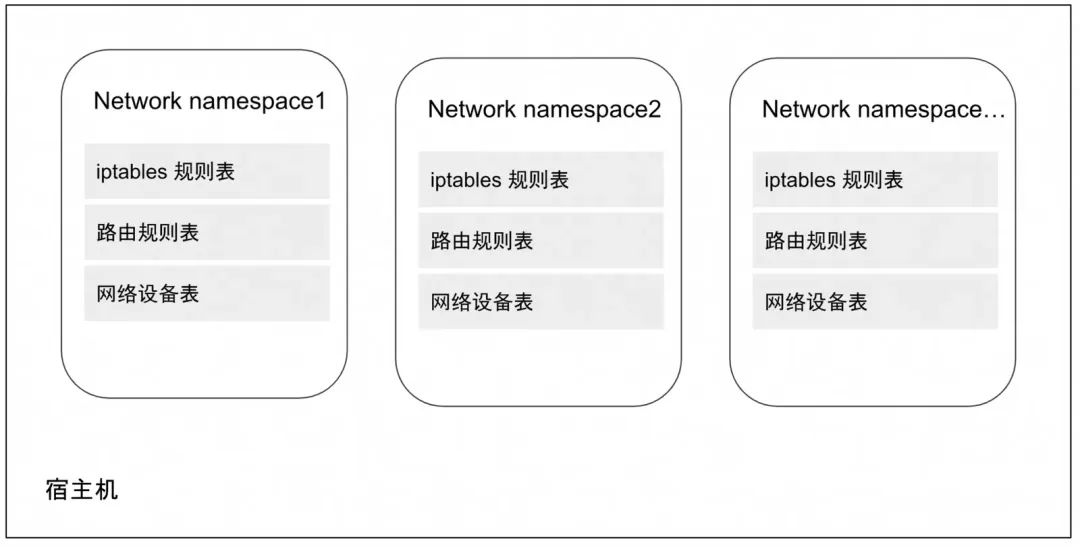
namespace在网络上的隔离
linux虚拟设备
-
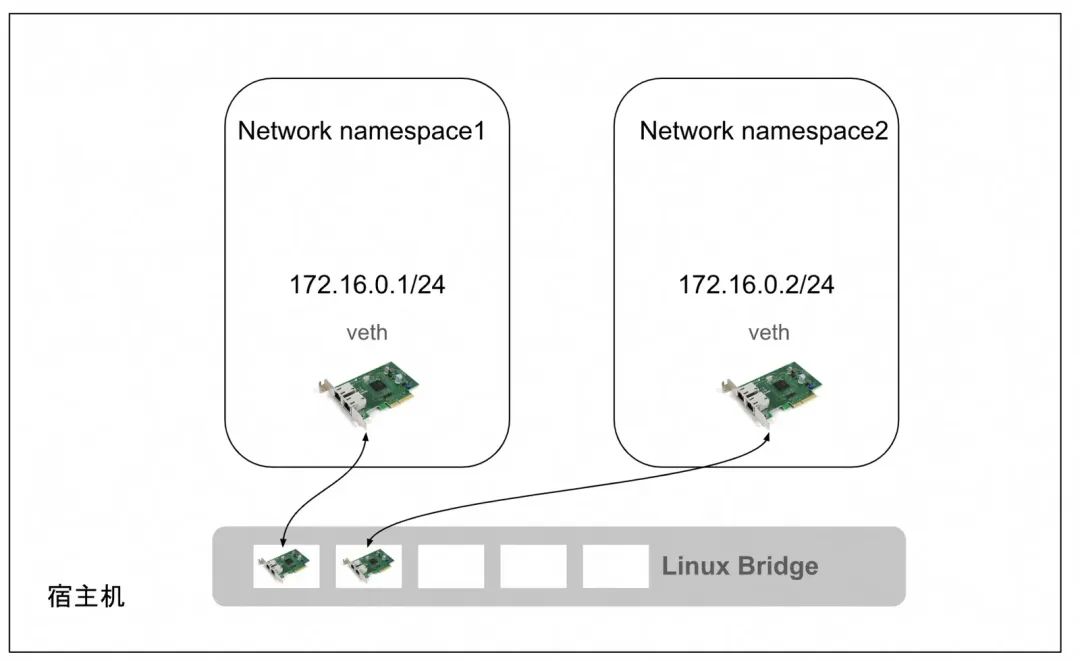
veth:Virtual Ethernet,虚拟以太网设备,用来让两个隔离的Network Namespace可以互相通信,都是成对出现也叫veth-pair。
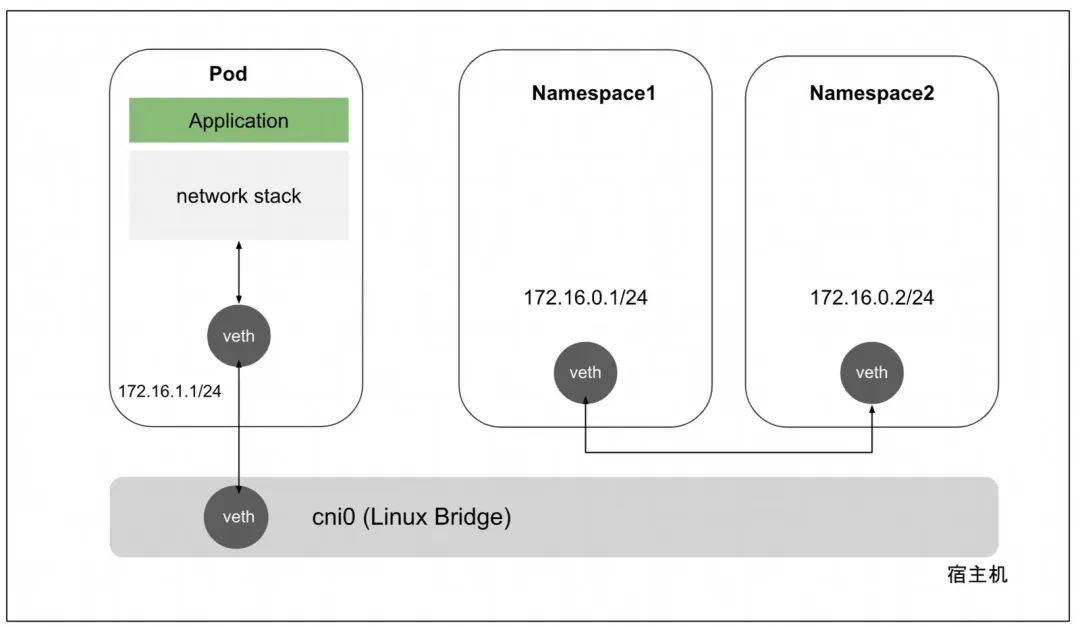
-
Linux bridge,在主机层面,如果需要多个主机之间需要网络联通,那么我们需要一个交换机(二层设备),在linux的虚拟网络系统中,我们可以通过虚拟网桥来实现此功能Linux Bridge是Linux kernel 2.2版本开始提供的二层转发工具,与物理交换机机制一致,能够接入任何二层的网络设备(无论是真实的物理设备,例如eth0或者虚拟设备,例如veth、tap 等)。不过Linux Bridge与普通物理交换机还有有一点不同,普通的交换机只会单纯地做二层转发,Linux Bridge却还能把发给它的数据包再发送到主机的三层协议栈中。
-
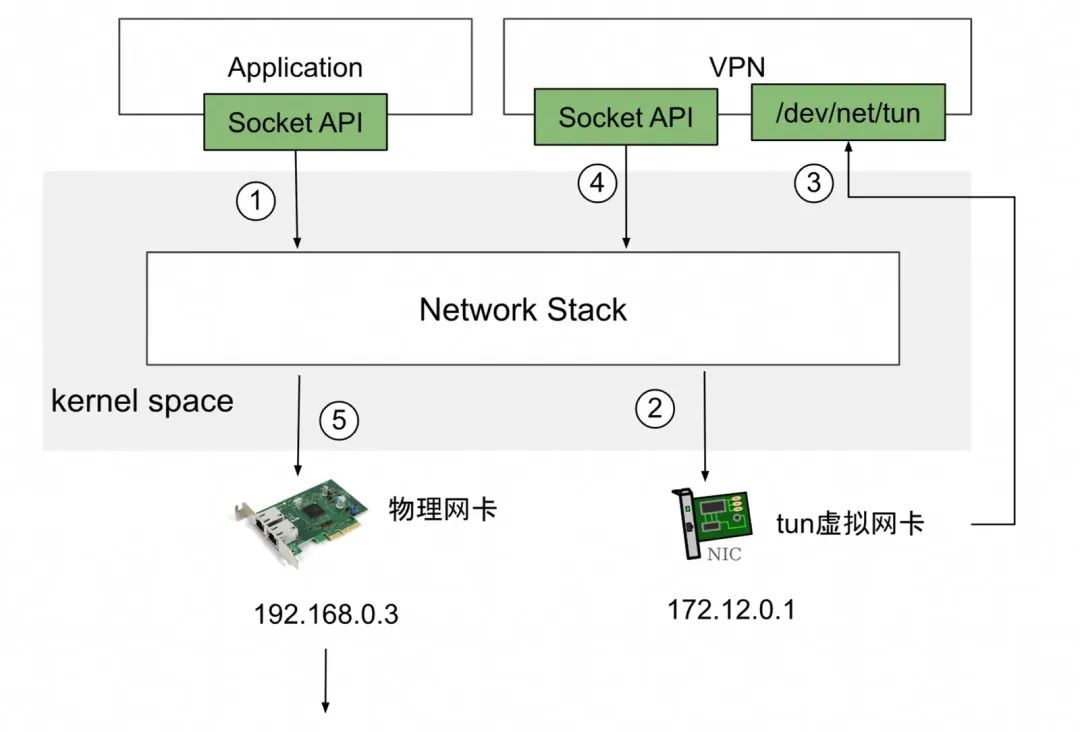
tun/tap:tun和tap是Linux提供的两个相对独立的虚拟网络设备,其中tap模拟了网络层设备,工作在L3,操作IP报文,tun则模拟了以太网设备,工作在L2,操作的是数据帧。当前云网络的基础协议VxLan就是基于隧道技术实现的,比如云网络的基础SDN(Software Definded Network,软件定义网络)。
docker详解
docker的初衷 “Build,Ship and Run Any App,Anywhere” (构建,发布和运行任何应用程序,在任何地方)回过头立看,已然实现。
docker构成
docker起始于2013年,经历了10年的发展,我们从下面一张图可以窥探docker结合k8s之后的变化。
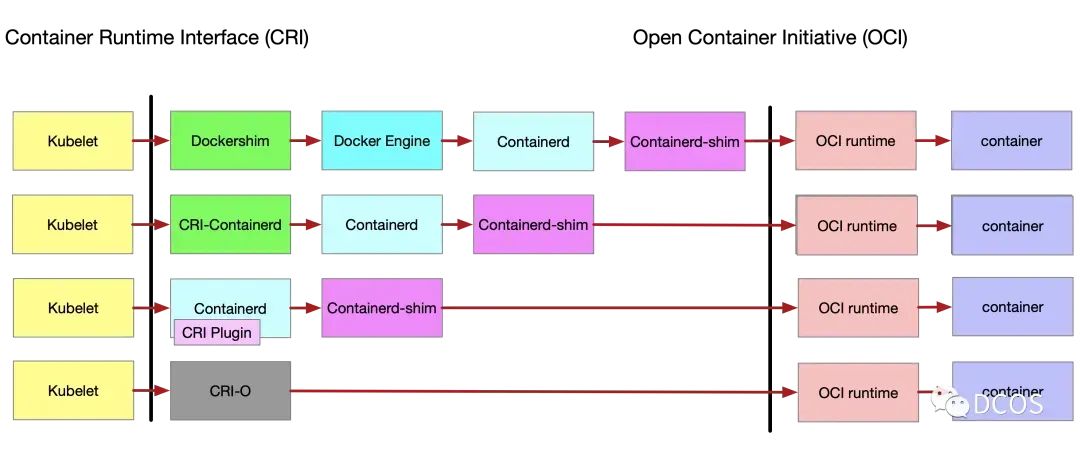
重大时间点:
-
2015年6月 Docker大会DockerCon推送容器标准,成立OCI组织; -
2015年12月 runc开源,2019年OCI接管,纳入oci生态; -
2017年2月 Docker宣布开源containerd,3月成为CNCF孵化项目; -
2017年3月 CRI1.0版本发布,定义了K8S和runc的标准;
很多组件,比如 dockerd、containerd-shim等都已经渐渐的在容器生态中淘汰。
运行时分类
经过docker的拆分和发展,我们可以将容器运行时根据功能做拆分:
1.只关注如namespace、cgroups、镜像拆包等基础的容器运行时实现被称为低层运行时(low-level container runtime), 目前应用最广泛的低层运行时是runc和kata(run-v)。
2.支持更多高级功能,例如镜像管理、CRI实现的运行时被称为高层运行时(high-level container runtime),目前应用最广泛高层运行时是containerd和cri-o。
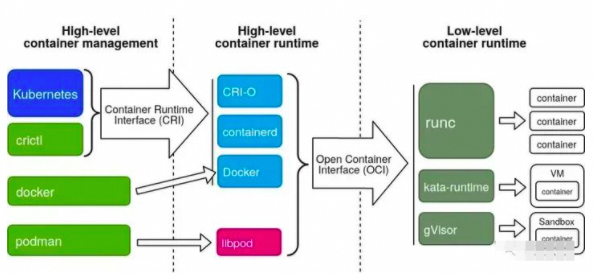
这两类运行时按照各自的分工,共同协作完成容器整个生命周期的管理工作。
高级运行时
CRI标准
早期Kubernetes完全依赖且绑定Docker,并没有过多考虑够日后使用其他容器引擎的可能性。当时kubernetes管理容器的方式通过内部的DockerManager直接调用Docker API来创建和管理容器。

Docker盛行之后,CoreOS推出了rkt运行时实现,Kubernetes又实现了对rkt的支持,随着容器技术的蓬勃发展,越来越多运行时实现出现,如果还继续使用与Docker类似强绑定的方式,Kubernetes的工作量将无比庞大。Kubernetes要重新考虑对所有容器运行时的兼容适配问题了。
Kubernetes从1.5版本开始,在遵循OCI基础上,将容器操作抽象为一个接口,该接口作为Kubelet 与运行时实现对接的桥梁,Kubelet通过发送接口请求对容器进行启动和管理,各个容器运行时只要实现这个接口就可以接入Kubernetes,这便是CRI(Container Runtime Interface,容器运行时接口)。
CRI实现上是一套通过Protocol Buffer定义的API,如下图:
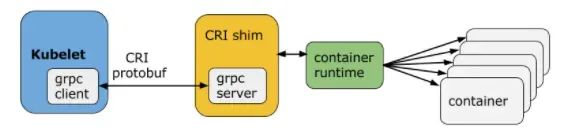
从上图可以看出:CRI主要有gRPC client、gRPC Server和具体容器运行时实现三个组件。其中Kubelet作为gRPC Client调用CRI接口,CRI shim作为gRPC Server 来响应CRI请求,并负责将CRI请求内容转换为具体的运行时管理操作。因此,任何容器运行时实现想要接入Kubernetes,都需要实现一个基于CRI接口规范的CRI shim(gRPC Server)。
containerd
containerd主要负责工作包括:
-
容器生命周期管理,通过和底层操作系统和硬件交互,负责容器的创建、启动、停止、删除等生命周期管理; -
镜像管理,管理容器镜像的下载、存储和加载; -
容器网络,提供了一些接口,允许网络插件通过CNI(Container Networking Interface)与容器交互,实现容器的网络连接和配置; -
安全和隔离,支持对容器的安全性和隔离进行管理。它通过集成Linux命名空间、cgroups等技术,确保容器在运行时与其他容器和主机系统隔离; -
OCI标准支持,对遵循 Open Container Initiative(OCI) 标准,这意味着它与符合 OCI 规范的容器和镜像兼容。这种标准化使得 containerd 能够与其他符合同一规范的工具和平台集成; -
插件系统,提供了一个插件系统,允许用户根据需要扩展其功能。这意味着用户可以选择使用特定的存储后端、日志记录器等插件,以满足其特定的需求。
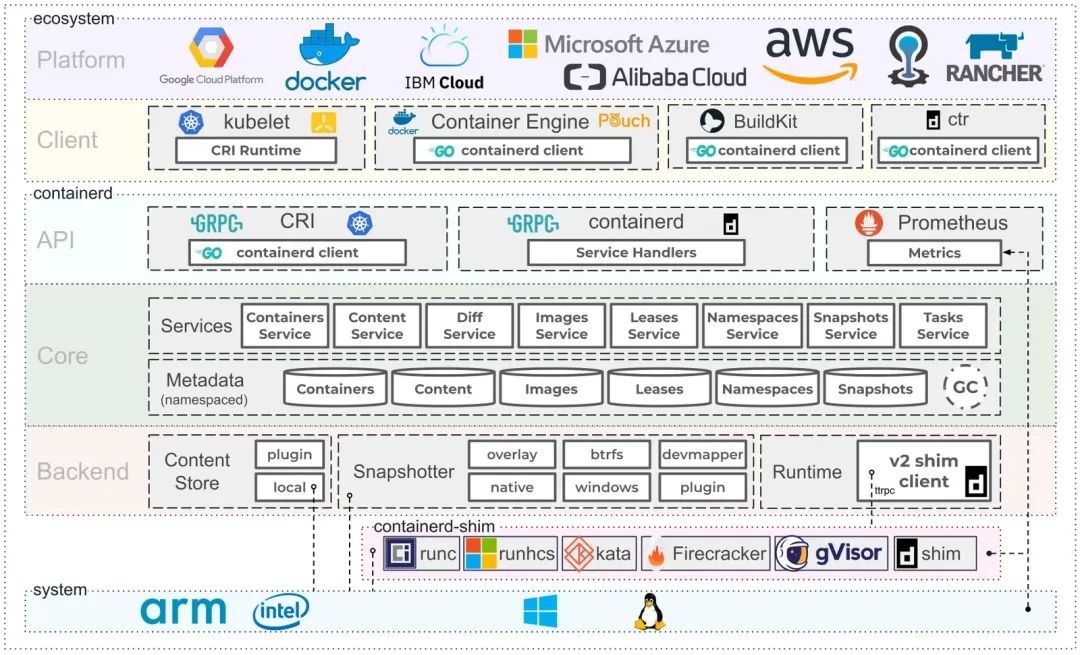
上面containerd官方提供的架构图,可以看出containerd采用的是C/S架构,服务端通过unix domain socket暴露低层的gRPC API接口出去,客户端通过这些API管理节点上的容器,每个containerd只负责一台机器,Pull镜像,对容器的操作(启动、停止等),网络,存储都是由containerd完成。具体运行容器由runc负责,实际上只要是符合OCI规范的容器都可以支持。
为了解耦,containerd将系统划分成了不同的组件,每个组件都由一个或多个模块协作完成(Core 和Backend部分),每一种类型的模块都以插件的形式集成到Containerd中,而且插件之间是相互依赖的,例如,上图中的每一个长虚线的方框都表示一种类型的插件,包括Service Plugin、Metadata Plugin、GC Plugin、Runtime Plugin等,其中Service Plugin又会依赖Metadata Plugin、GC Plugin和Runtime Plugin。每一个小方框都表示一个细分的插件,例如Metadata Plugin依赖Containers Plugin、Content Plugin等。
-
Content Plugin: 提供对镜像中可寻址内容的访问,所有不可变的内容都被存储在这里。 -
Snapshot Plugin: 用来管理容器镜像的文件系统快照,镜像中的每一层都会被解压成文件系统快照。
总体来看containerd作为高级运行时,可以分为三个大块:Storage、Metadata 和Runtime。
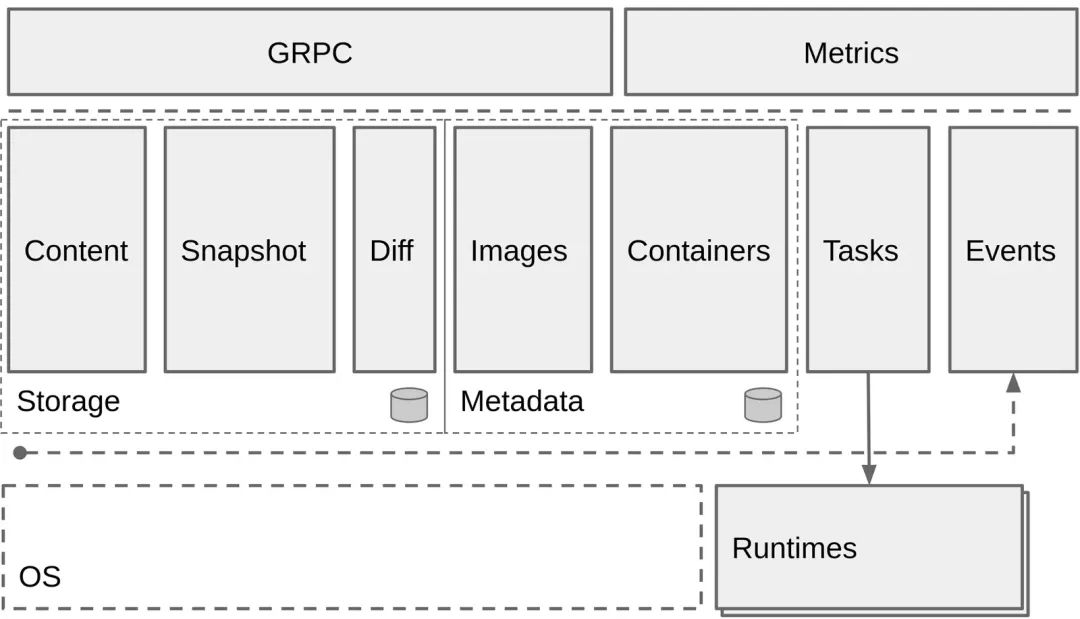
containerd创建bundle的数据流
bundles是指被Runtime使用的配置、元数据、rootfs数据。一个bundle就是一个运行时的容器在磁盘上的表现形式,简化为文件系统中的一个目录。
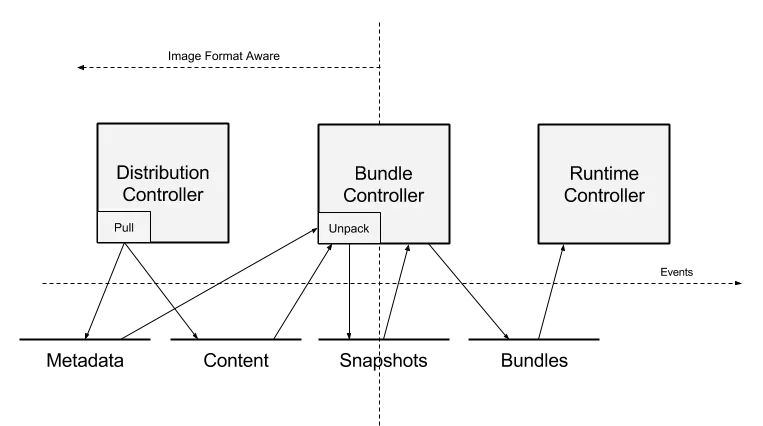
1.指示Distribution Controller去拉取一个具体的镜像,Distribution将镜像分层内容存储到内容存储中(content store),将镜像名和root manifest pointers注册到元数据存储中(metadata store)。
2.一旦镜像拉取完成,用户可以指示Bundle Controller将镜像分解包到一个bundle中。从内容存储中消费后,图像中的层被解压缩到快照组件中。
3.当容器的rootfs的快照准备好时,Bundle Controller控制器可以使用image manifest和配置来准备执行配置。其中一部分是将挂载从snapshot模块输入到执行配置中。
4.然后将准备好的bundle给Runtime子系统以执行, Runtime子系统将读取bundle配置来创建一个运行的容器。
低级运行时
OCI开放容器标准
Linux 基金会于 2015 年 6 月成立OCI(Open Container Initiative)组织,旨在围绕容器格式和运行时制定一个开放的工业化标准。
标准化容器的宗旨具体分为如下五条。
-
操作标准化:容器的标准化操作包括使用标准容器感觉创建、启动、停止容器,使用标准文件系统工具复制和创建容器快照,使用标准化网络工具进行下载和上传; -
内容无关:内容无关指不管针对的具体容器内容是什么,容器标准操作执行后都能产生同样的效果。如容器可以用同样的方式上传、启动,不管是 php 应用还是mysql数据库服务; -
基础设施无关:无论是个人的笔记本电脑还是AWS S3,亦或是Openstack,或者其他基础设施,都应该对支持容器的各项操作; -
为自动化量身定制:制定容器统一标准,是操作内容无关化、平台无关化的根本目的之一,就是为了可以使容器操作全平台自动化; -
工业级交付:制定容器标准一大目标,就是使软件分发可以达到工业级交付成为现实。
OCI 有了三个主要的规范标准:
-
runtime-spec(容器运行时标准):定义了容器运行的配置,环境和生命周期。即如何运行一个容器,如何管理容器的状态和生命周期,如何使用操作系统的底层特性(namespace,cgroup,pivot_root 等); -
image-spec(容器镜像标准):定义了镜像的格式,配置(包括应用程序的参数,环境信息等),依赖的元数据格式等,简单来说就是对镜像的静态描述; -
distribution-spec(镜像分发标准):即规定了镜像上传和下载的网络交互过程。
根据OCI标准,当前流行的RUNC解决方案有以下三种:
-
opencontainers/runc:前面已经提到过很多次了,是OCI Runtime的参考实现。 -
kata-containers/runtime:容器标准反攻虚拟机,前身是clearcontainers/runtime与hyperhq/runv,通过virtcontainers提供高性能OCI标准兼容的硬件虚拟化容器,Linux Only,且需要特定硬件。 -
google/gvisor:gVisor是一个Go实现的用户态内核,包含了一个OCI兼容的Runtime实现,目标是提供一个可运行非受信代码的容器运行时沙盒,目前是Linux Only,其他架构可能会支持。
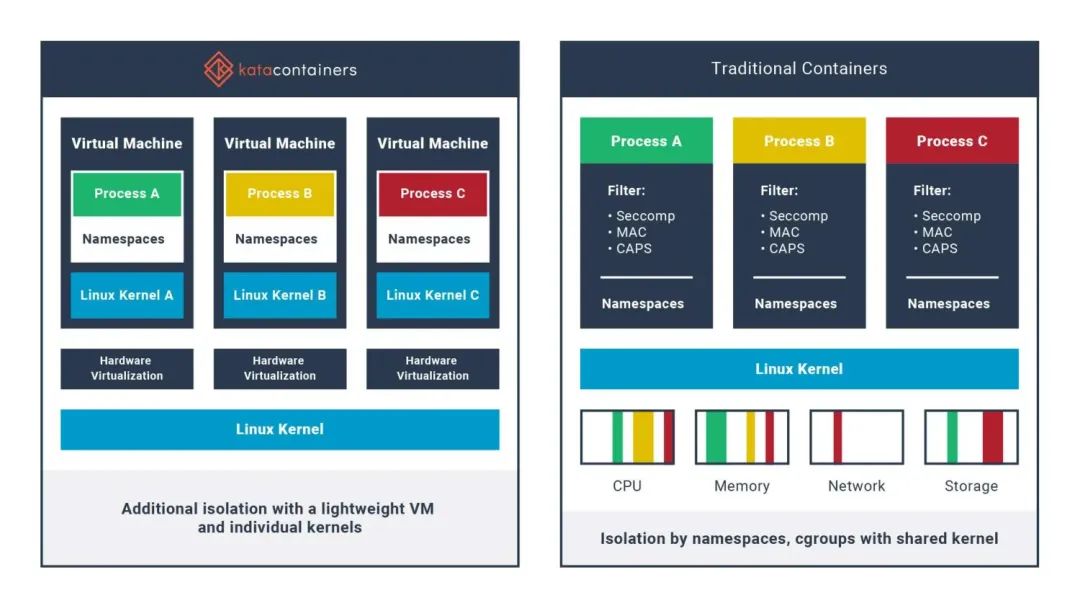
安全容器
云安全中心容器主动防御
尽管容器有许多技术优势,然而传统以runc为代表基于共享内核技术进行的软隔离还是存在一定的风险性。如果某个恶意程序利用系统缺陷从容器中逃逸,就会对宿主机造成严重威胁,尤其是公有云环境,安全威胁很可能会波及到其他用户的数据和业务。
将虚拟机的安全优势与容器的高速及可管理性相结合,为用户提供标准化、安全、高性能的容器解决方案,于是就有了Kata Containers 。
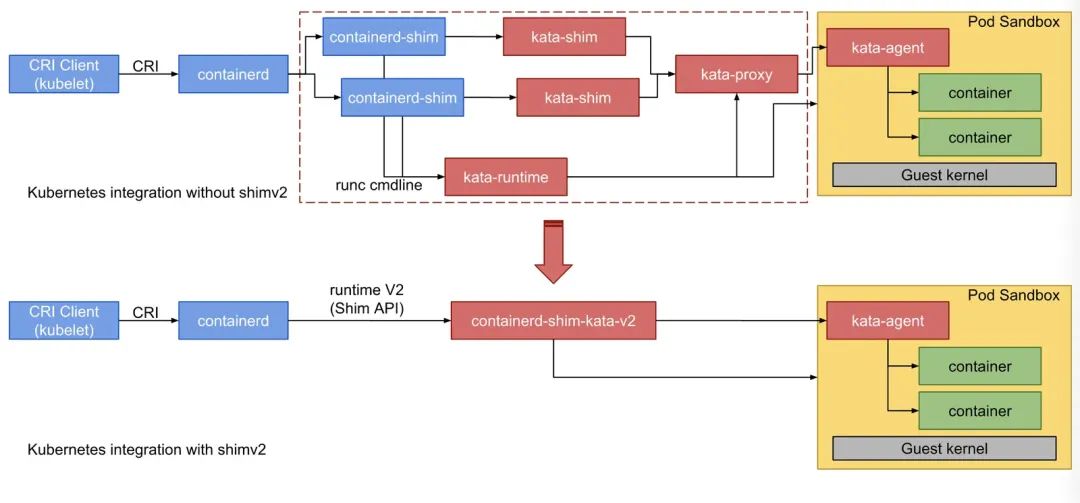
Kata Containers运行符合OCI规范,同时兼容Kubernetes CRI(虚拟机级别的Pod 实现)。为了缩短容器的调用链、高效地和Kubernetes CRI集成,Kata-Container 直接将containerd-shim和kata-shim以及kata-proxy融合到一起。CRI和Kata Containers的集成下图所示:
容器编排
什么是容器编排?
容器编排是指对容器化应用程序的自动化部署、协调和管理过程。容器编排工具被设计用于简化和自动化在多个容器之间的通信、调度、伸缩和维护等任务。这些工具可以确保容器在整个应用程序生命周期中保持一致、可靠且高效运行。
容器编排的发展

常见的编排工具有mesos,swarm,k8s等,当前市场最流行的还是k8s。
为什么k8s能最终胜出?
4.容器标准的普及;
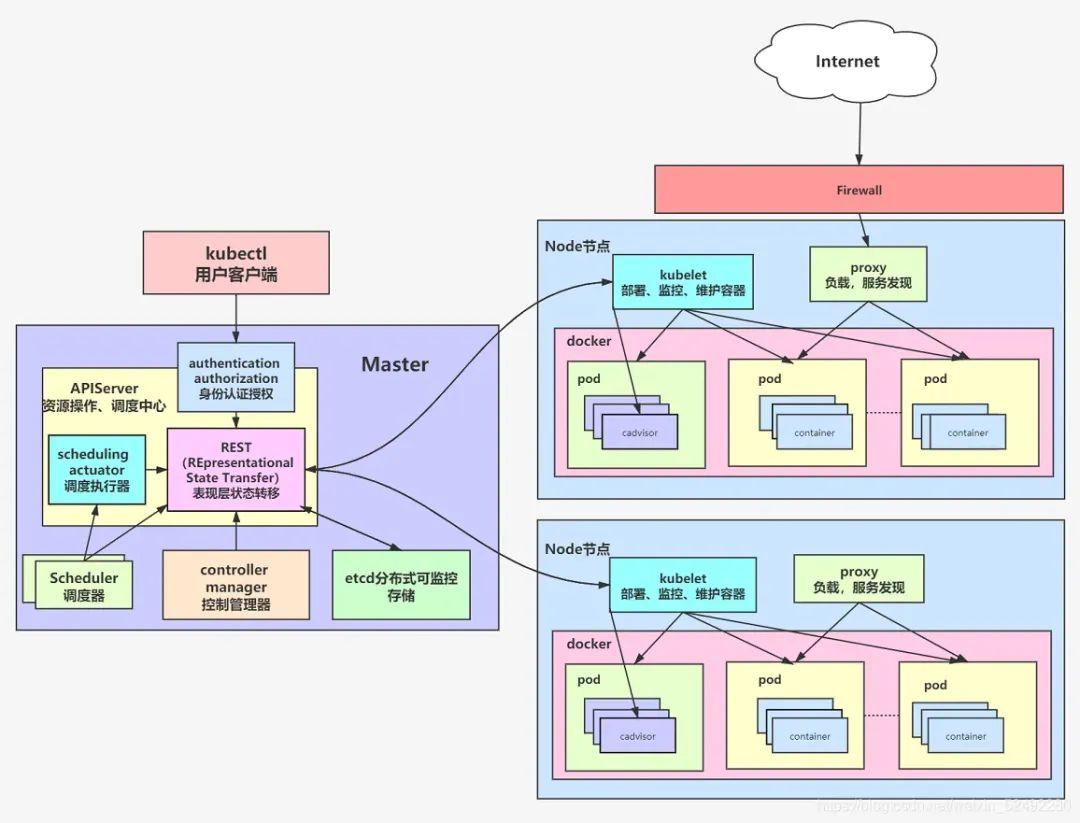
单租 -> 多租
ECI弹性容器实例
ECI从1.0已经演进到当前的3.0,从运营在on ecs到和ecs混部。
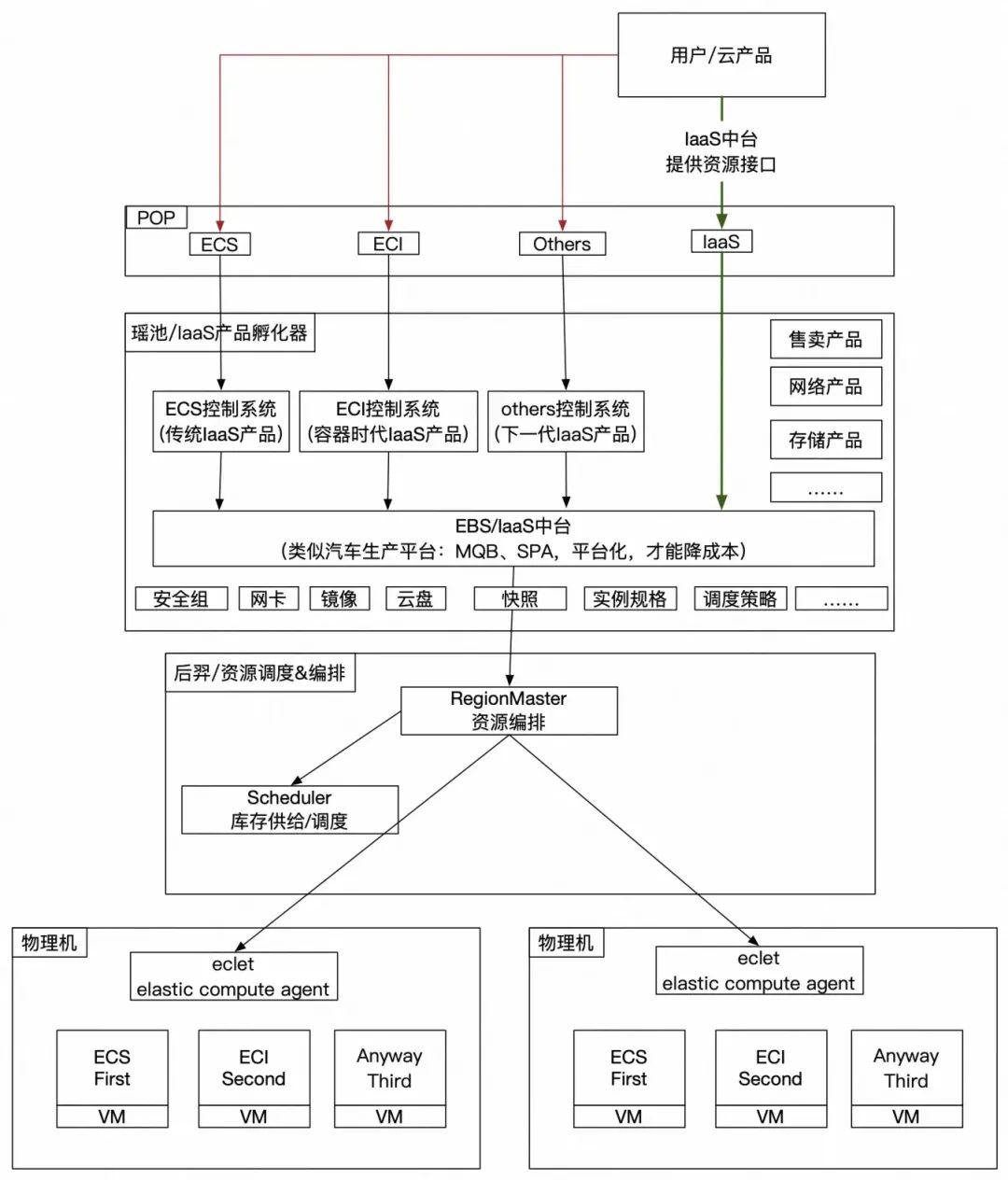
架构分层:
4.资源供给&资源调度&资源编排;
如何生产一个ECI实例
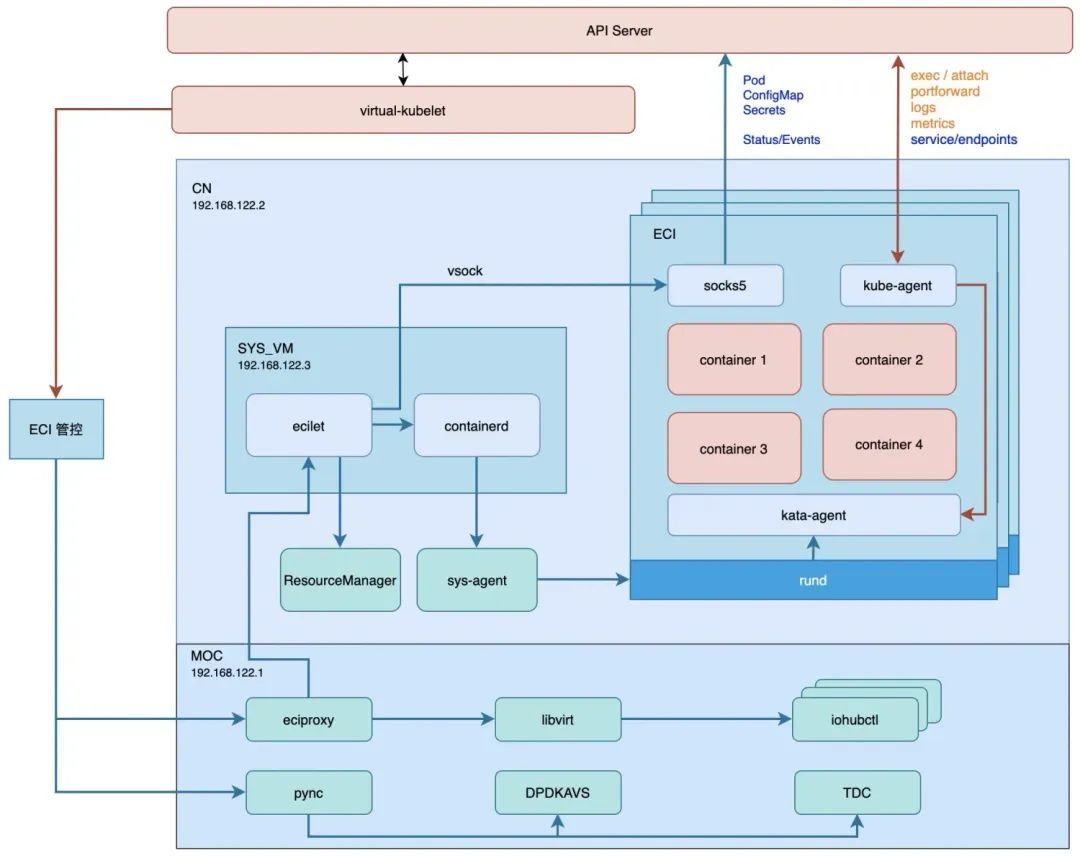
4、containerd调用cn上的sys-agent(由于containerd置于sysvm内,无法与rund直接通讯,所以需要sys-agent进行转发请求)进而调用rund生产sandbox,rund guest内的containerd拉取容器镜像,进而kata-agent生产容器。至此一台完整的ECI实例被生产出来,用户可以欢快地跑自己的应用了。
rund安全容器
前面已经介绍了kata-container,rund是阿里云在容器安全的实现方案,RunD 作为一种轻量级安全容器运行时,提出了 host-to-guest 的全栈优化方案来解决以下三个问题:
-
容器的文件系统可以根据用户镜像只读和不需要持久化的特点进行定制;
-
客户机中的操作系统基础映像等可以在多个安全容器间共享和按需压缩以降低内存开销;
-
高并发创建 cgroup 会导致高同步时延,尤其在高密场景下带来的高调度开销。
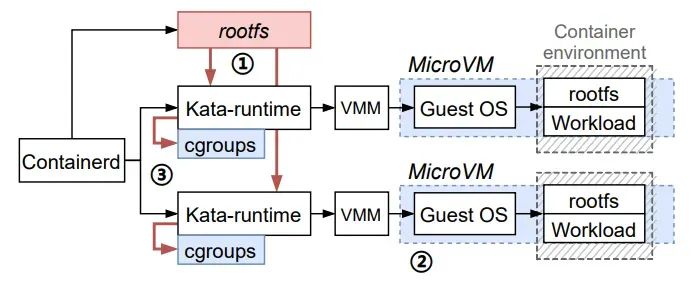
rund方案解决的问题,并发启动Kata容器的步骤
以kata作为容器运行时,并发瓶颈点在于创建rootfs(红色块步骤1)和创建cgroups(红色线步骤3)密度瓶颈点在于MicroVM的高额内存开销(蓝色块步骤2)和大量cgroups的调度维护开销(蓝色块步骤3)。
rund方案架构图如下:
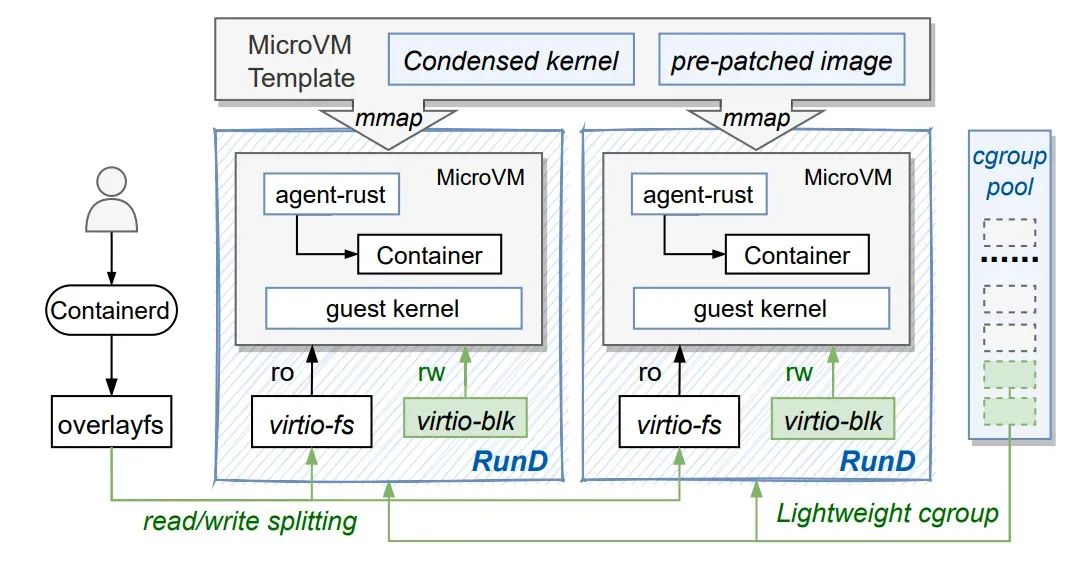
rund架构图
RunD设计并总结了host-to-guest的全栈解决方案。RunD运行时通过virtio-fs提供只读层,使用built-in storage为virtio-blk创建一个非持久的读写层,并使用 overlayfs将前者和后者挂载为最终的容器rootfs,从而进行读/写分离。RunD利用集成了精简内核的microVM模板,并采用预处理的镜像创建一个新的microVM,进一步分摊了不同的microVM的开销。在创建安全容器时,RunD从cgroup池绑定一个轻量级的cgroup进行资源管理。
基于上述优化,当使用RunD作为安全容器运行时,安全容器将按照以下步骤启动:
第三步:hypervisor使用microVM模板创建所需的沙箱,并通过overlayfs将rootfs 挂载到沙箱中;
最后一个轻量级的cgroup从cgroup池中被重命名,然后绑定到沙箱上,管理资源使用。
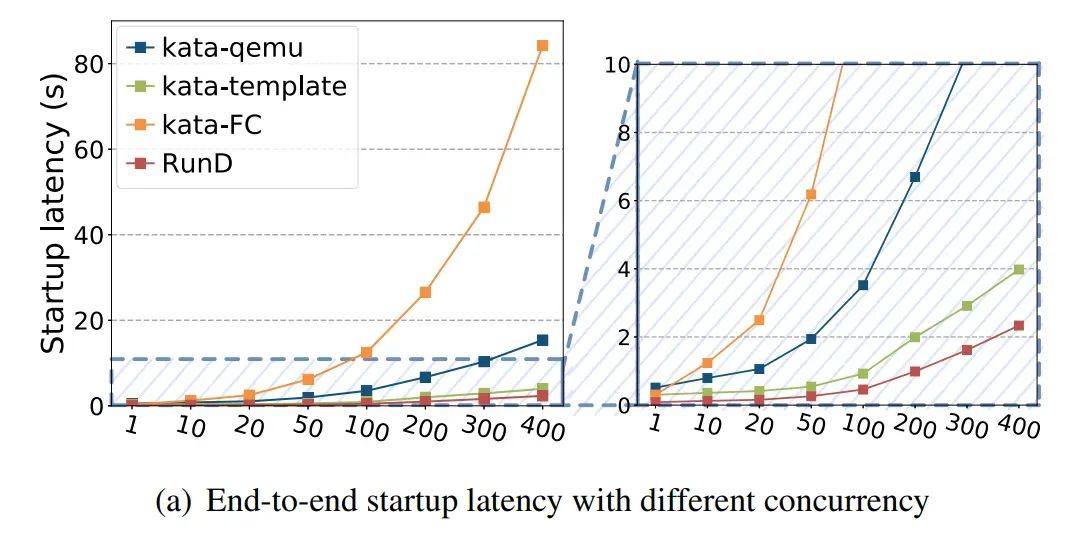
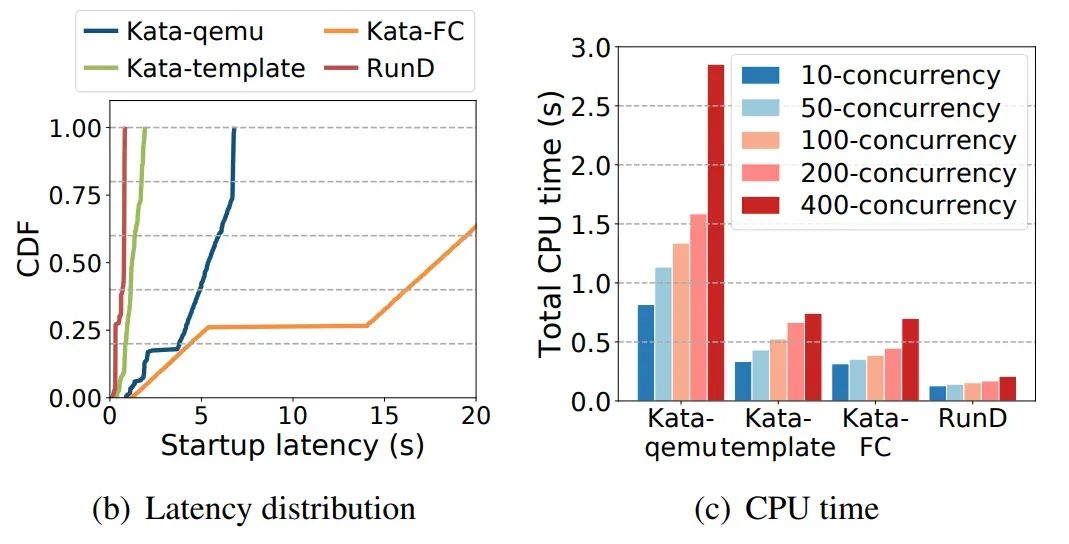
并发性能总结:RunD能够在88ms内启动一个单独沙盒,并具备在 1 秒内同时启动 200个沙箱的并发能力,与现有技术相比,具有最小的延迟波动和CPU开销。
参考文档:
0 条评论