一、 Java本地缓存技术介绍
1.1 HashMap
-
优点:简单粗暴,不需要引入第三方包,比较适合一些比较简单的场景。
-
缺点:没有缓存淘汰策略,定制化开发成本高。
public class LRUCache extends LinkedHashMap {/*** 可重入读写锁,保证并发读写安全性*/private ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();private Lock readLock = readWriteLock.readLock();private Lock writeLock = readWriteLock.writeLock();/*** 缓存大小限制*/private int maxSize;public LRUCache(int maxSize) {super(maxSize + 1, 1.0f, true);this.maxSize = maxSize;}public Object get(Object key) {readLock.lock();try {return super.get(key);} finally {readLock.unlock();}}public Object put(Object key, Object value) {writeLock.lock();try {return super.put(key, value);} finally {writeLock.unlock();}}protected boolean removeEldestEntry(Map.Entry eldest) {return this.size() > maxSize;}}
1.2 Guava Cache
-
优点:支持最大容量限制,两种过期删除策略(插入时间和访问时间),支持简单的统计功能。
-
缺点:springboot2和spring5都放弃了对Guava Cache的支持。
1.3 Caffeine
public class CaffeineCacheTest {public static void main(String[] args) throws Exception {//创建guava cacheCacheString, String> loadingCache = Caffeine.newBuilder()//cache的初始容量.initialCapacity(5)//cache最大缓存数.maximumSize(10)//设置写缓存后n秒钟过期.expireAfterWrite(17, TimeUnit.SECONDS)//设置读写缓存后n秒钟过期,实际很少用到,类似于expireAfterWrite//.expireAfterAccess(17, TimeUnit.SECONDS).build();String key = "key";// 往缓存写数据loadingCache.put(key, "v");// 获取value的值,如果key不存在,获取value后再返回String value = loadingCache.get(key, CaffeineCacheTest::getValueFromDB);// 删除keyloadingCache.invalidate(key);}private static String getValueFromDB(String key) {return "v";}}
1.4 Encache
-
优点:支持多种缓存淘汰算法,包括LFU,LRU和FIFO;缓存支持堆内缓存,堆外缓存和磁盘缓存;支持多种集群方案,解决数据共享问题。
-
缺点:性能比Caffeine差
public class EncacheTest {public static void main(String[] args) throws Exception {// 声明一个cacheBuilderCacheManager cacheManager = CacheManagerBuilder.newCacheManagerBuilder().withCache("encacheInstance", CacheConfigurationBuilder//声明一个容量为20的堆内缓存.newCacheConfigurationBuilder(String.class,String.class, ResourcePoolsBuilder.heap(20))).build(true);// 获取Cache实例CacheString,String> myCache = cacheManager.getCache("encacheInstance", String.class, String.class);// 写缓存myCache.put("key","v");// 读缓存String value = myCache.get("key");// 移除换粗cacheManager.removeCache("myCache");cacheManager.close();}}
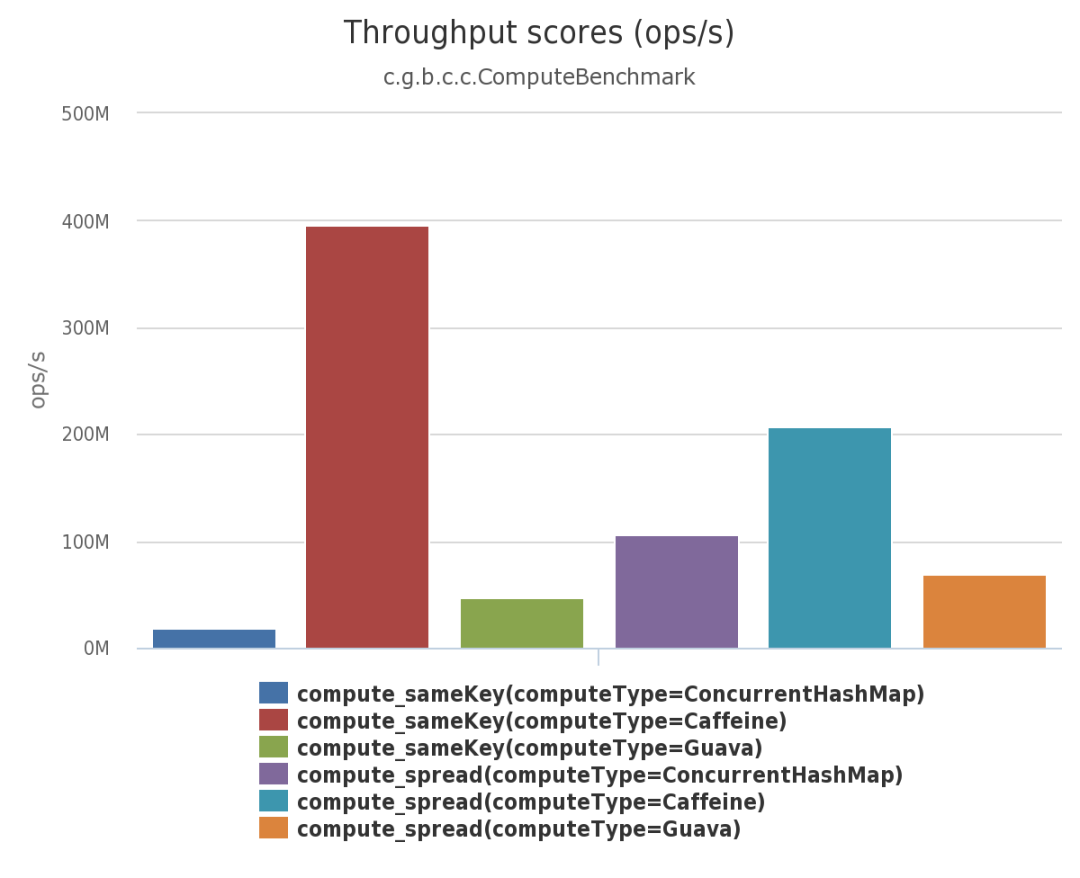
二、高性能缓存Caffeine
2.1 缓存类型
2.1.1 Cache
CacheKey, Graph> cache = Caffeine.newBuilder().expireAfterWrite(10, TimeUnit.MINUTES).maximumSize(10_000).build();// 查找一个缓存元素, 没有查找到的时候返回nullGraph graph = cache.getIfPresent(key);// 查找缓存,如果缓存不存在则生成缓存元素, 如果无法生成则返回nullgraph = cache.get(key, k -> createExpensiveGraph(key));// 添加或者更新一个缓存元素cache.put(key, graph);// 移除一个缓存元素cache.invalidate(key);
2.1.2 Loading Cache
LoadingCachecache = Caffeine.newBuilder() .maximumSize(10_000).expireAfterWrite(10, TimeUnit.MINUTES).build(key -> createExpensiveGraph(key));// 查找缓存,如果缓存不存在则生成缓存元素, 如果无法生成则返回nullGraph graph = cache.get(key);// 批量查找缓存,如果缓存不存在则生成缓存元素Mapgraphs = cache.getAll(keys);
如果缓存不错在,则会通过CacheLoader.load来生成对应的缓存元素。
2.1.3 Async Cache
AsyncCachecache = Caffeine.newBuilder() .expireAfterWrite(10, TimeUnit.MINUTES).maximumSize(10_000).buildAsync();// 查找一个缓存元素, 没有查找到的时候返回nullCompletableFuturegraph = cache.getIfPresent(key); // 查找缓存元素,如果不存在,则异步生成graph = cache.get(key, k -> createExpensiveGraph(key));// 添加或者更新一个缓存元素cache.put(key, graph);// 移除一个缓存元素cache.synchronous().invalidate(key);
2.1.4 Async Loading Cache
AsyncLoadingCachecache = Caffeine.newBuilder() .maximumSize(10_000).expireAfterWrite(10, TimeUnit.MINUTES)// 你可以选择: 去异步的封装一段同步操作来生成缓存元素.buildAsync(key -> createExpensiveGraph(key));// 你也可以选择: 构建一个异步缓存元素操作并返回一个future.buildAsync((key, executor) -> createExpensiveGraphAsync(key, executor));// 查找缓存元素,如果其不存在,将会异步进行生成CompletableFuturegraph = cache.get(key); // 批量查找缓存元素,如果其不存在,将会异步进行生成CompletableFutureMap> graphs = cache.getAll(keys);
2.2 驱逐策略
-
基于容量
// 基于缓存内的元素个数进行驱逐LoadingCachegraphs = Caffeine.newBuilder() .maximumSize(10_000).build(key -> createExpensiveGraph(key));// 基于缓存内元素权重进行驱逐LoadingCachegraphs = Caffeine.newBuilder() .maximumWeight(10_000).weigher((Key key, Graph graph) -> graph.vertices().size()).build(key -> createExpensiveGraph(key));
-
基于时间
// 基于固定的过期时间驱逐策略LoadingCachegraphs = Caffeine.newBuilder() .expireAfterAccess(5, TimeUnit.MINUTES).build(key -> createExpensiveGraph(key));LoadingCachegraphs = Caffeine.newBuilder() .expireAfterWrite(10, TimeUnit.MINUTES).build(key -> createExpensiveGraph(key));// 基于不同的过期驱逐策略LoadingCachegraphs = Caffeine.newBuilder() .expireAfter(new Expiry() { public long expireAfterCreate(Key key, Graph graph, long currentTime) {// Use wall clock time, rather than nanotime, if from an external resourcelong seconds = graph.creationDate().plusHours(5).minus(System.currentTimeMillis(), MILLIS).toEpochSecond();return TimeUnit.SECONDS.toNanos(seconds);}public long expireAfterUpdate(Key key, Graph graph,long currentTime, long currentDuration) {return currentDuration;}public long expireAfterRead(Key key, Graph graph,long currentTime, long currentDuration) {return currentDuration;}}).build(key -> createExpensiveGraph(key));
-
基于引用
// 当key和缓存元素都不再存在其他强引用的时候驱逐LoadingCachegraphs = Caffeine.newBuilder() .weakKeys().weakValues().build(key -> createExpensiveGraph(key));// 当进行GC的时候进行驱逐LoadingCachegraphs = Caffeine.newBuilder() .softValues().build(key -> createExpensiveGraph(key));
2.3 刷新机制
LoadingCacheKey, Graph> graphs = Caffeine.newBuilder().maximumSize(10_000).refreshAfterWrite(1, TimeUnit.MINUTES).build(key -> createExpensiveGraph(key));
2.4 统计
CacheKey, Graph> graphs = Caffeine.newBuilder().maximumSize(10_000).recordStats().build();
-
hitRate(): 查询缓存的命中率
-
evictionCount(): 被驱逐的缓存数量
-
averageLoadPenalty(): 新值被载入的平均耗时
三、Caffeine在SpringBoot的实战
-
方式一:直接引入Caffeine依赖,然后使用Caffeine的函数实现缓存
-
方式二:引入Caffeine和Spring Cache依赖,使用SpringCache注解方法实现缓存
下面分别介绍两种使用方式。
方式一:使用Caffeine依赖
dependency>groupId>com.github.ben-manes.caffeinegroupId>artifactId>caffeineartifactId>dependency>
public class CacheConfig {public CacheString, Object> caffeineCache() {return Caffeine.newBuilder()// 设置最后一次写入或访问后经过固定时间过期.expireAfterWrite(60, TimeUnit.SECONDS)// 初始的缓存空间大小.initialCapacity(100)// 缓存的最大条数.maximumSize(1000).build();}}
最后给服务添加缓存功能
public class UserInfoServiceImpl {/*** 模拟数据库存储数据*/private HashMapuserInfoMap = new HashMap(); CacheString, Object> caffeineCache;public void addUserInfo(UserInfo userInfo) {userInfoMap.put(userInfo.getId(), userInfo);// 加入缓存caffeineCache.put(String.valueOf(userInfo.getId()),userInfo);}public UserInfo getByName(Integer id) {// 先从缓存读取caffeineCache.getIfPresent(id);UserInfo userInfo = (UserInfo) caffeineCache.asMap().get(String.valueOf(id));if (userInfo != null){return userInfo;}// 如果缓存中不存在,则从库中查找userInfo = userInfoMap.get(id);// 如果用户信息不为空,则加入缓存if (userInfo != null){caffeineCache.put(String.valueOf(userInfo.getId()),userInfo);}return userInfo;}public UserInfo updateUserInfo(UserInfo userInfo) {if (!userInfoMap.containsKey(userInfo.getId())) {return null;}// 取旧的值UserInfo oldUserInfo = userInfoMap.get(userInfo.getId());// 替换内容if (!StringUtils.isEmpty(oldUserInfo.getAge())) {oldUserInfo.setAge(userInfo.getAge());}if (!StringUtils.isEmpty(oldUserInfo.getName())) {oldUserInfo.setName(userInfo.getName());}if (!StringUtils.isEmpty(oldUserInfo.getSex())) {oldUserInfo.setSex(userInfo.getSex());}// 将新的对象存储,更新旧对象信息userInfoMap.put(oldUserInfo.getId(), oldUserInfo);// 替换缓存中的值caffeineCache.put(String.valueOf(oldUserInfo.getId()),oldUserInfo);return oldUserInfo;}public void deleteById(Integer id) {userInfoMap.remove(id);// 从缓存中删除caffeineCache.asMap().remove(String.valueOf(id));}}
方式二:使用Spring Cache注解
dependency>groupId>org.springframework.bootgroupId>artifactId>spring-boot-starter-cacheartifactId>dependency>dependency>groupId>com.github.ben-manes.caffeinegroupId>artifactId>caffeineartifactId>dependency>
public class CacheConfig {/*** 配置缓存管理器** @return 缓存管理器*/("caffeineCacheManager")public CacheManager cacheManager() {CaffeineCacheManager cacheManager = new CaffeineCacheManager();cacheManager.setCaffeine(Caffeine.newBuilder()// 设置最后一次写入或访问后经过固定时间过期.expireAfterAccess(60, TimeUnit.SECONDS)// 初始的缓存空间大小.initialCapacity(100)// 缓存的最大条数.maximumSize(1000));return cacheManager;}}
public class UserInfoServiceImpl {/*** 模拟数据库存储数据*/private HashMapuserInfoMap = new HashMap(); public void addUserInfo(UserInfo userInfo) {userInfoMap.put(userInfo.getId(), userInfo);}public UserInfo getByName(Integer id) {return userInfoMap.get(id);}public UserInfo updateUserInfo(UserInfo userInfo) {if (!userInfoMap.containsKey(userInfo.getId())) {return null;}// 取旧的值UserInfo oldUserInfo = userInfoMap.get(userInfo.getId());// 替换内容if (!StringUtils.isEmpty(oldUserInfo.getAge())) {oldUserInfo.setAge(userInfo.getAge());}if (!StringUtils.isEmpty(oldUserInfo.getName())) {oldUserInfo.setName(userInfo.getName());}if (!StringUtils.isEmpty(oldUserInfo.getSex())) {oldUserInfo.setSex(userInfo.getSex());}// 将新的对象存储,更新旧对象信息userInfoMap.put(oldUserInfo.getId(), oldUserInfo);// 返回新对象信息return oldUserInfo;}public void deleteById(Integer id) {userInfoMap.remove(id);}}
四、Caffeine在Reactor的实战
final CacheString, String> caffeineCache = Caffeine.newBuilder().expireAfterWrite(Duration.ofSeconds(30)).recordStats().build();
CacheMono
final MonocachedMonoCaffeine = CacheMono .lookup(k -> Mono.justOrEmpty(caffeineCache.getIfPresent(k)).map(Signal::next),key).onCacheMissResume(this.handleCacheMiss(key)).andWriteWith((k, sig) -> Mono.fromRunnable(() ->caffeineCache.put(k, Objects.requireNonNull(sig.get()))));
CacheFlux
final FluxcachedFluxCaffeine = CacheFlux .lookup(k -> {final Listcached = caffeineCache.getIfPresent(k); if (cached == null) {return Mono.empty();}return Mono.just(cached).flatMapMany(Flux::fromIterable).map(Signal::next).collectList();},key).onCacheMissResume(this.handleCacheMiss(key)).andWriteWith((k, sig) -> Mono.fromRunnable(() ->caffeineCache.put(k,sig.stream().filter(signal -> signal.getType() == SignalType.ON_NEXT).map(Signal::get).collect(Collectors.toList()))));
参考:
-
https://www.javadevjournal.com/spring-boot/spring-boot-with-caffeine-cache/ -
https://sunitc.dev/2020/08/27/springboot-implement-caffeine-cache/ -
https://github.com/ben-manes/caffeine/wiki/Population-zh-CN -
Guava Cache主页:https://github.com/google/guava/wiki/CachesExplained -
Caffeine的官网:https://github.com/ben-manes/caffeine/wiki/Benchmarks
0 条评论