无论多么复杂的业务场景,一条数据的一生都体现在CRUD操作上,正是创建、查询、修改、删除。正如人的生死轮回,数据亦是如此,一条数据随着时间的流逝,其价值也是在逐渐变小。
数据存在的价值则是在于它被使用的程度,在不同的系统中,人们对于不同时期的数据有着不同的需求。
比如12306、携程上的火车、机票订单,人们往往只关注30天之内的订单,而携程正是默认只保留30天的订单信息,超过30天的订单需要通过手机号查找。

携程为什么要这么做?
其实仔细想想不难明白,作为全国购票平台,每年数以亿计的订单,如果全部能够开放操作(CRUD),那么系统将会瞬间崩溃。
一个订单走到终态的标志则是这笔订单的完成,也就意味着这笔订单除了查询的需求,不再任由用户修改、删除。
其实携程所用的架构方法正是:冷热分离。
什么是冷热分离?
冷热分离则是在处理数据时将数据库分为热库和冷库两个库。冷库存放的是走到终态的数据,热库存放的是还需要修改的数据。
比如30天之内的机票、火车票订单,用户可能需要对这期间的订单做出退票、开发票的操作,但是30天之前订单却只有查询的需求,因此可以将30天之内的订单放到热库中,之前的订单存放到冷库中。
那么这里又引出了两个概念,分别是:
-
热数据:被频繁更新;响应时间有要求
-
冷数据:不允许更新(具体业务系统具体分析),偶尔被查询;响应时间无要求。
什么情况下需要使用冷热分离?
在大型的互联网系统中,如果出现了以下场景则应该考虑冷热分离:
-
主业务响应延迟太大,比如12306下订单太慢了。 -
数据走到终态后,没有更新需求,只有读的需求,比如订单的完成状态。 -
用户能够接受新旧数据分开查询,比如携程的订单查询30天之前的需要用手机号查询。
“
补充:当然现在有些系统不像携程那样将往期订单分开查询,但是其实内部也是做了冷热分离,只不过是在你无感知的情况下完成的。
”
如何判断一个数据是冷数据还是热数据?
这个就要根据自己业务系统来区分了,一般而言是根据主表中的一个或者多个字段进行标识区分,比如订单的时间,这个是时间维度,可以将3个月之前的数据定义为冷数据,最近3个月的数据定义为热数据。
当然也可以是状态维度,比如订单的状态,已完结的订单定义为冷数据,未完结的订单定义为热数据。
同样的也可以将时间维度和状态维度组合起来,比如下单时间大于3个月且订单状态为已完结的定义为冷数据,反则为热数据。
“
总之:根据自己业务需求,具体问题具体分析。
”
但是需要注意以下两点:
-
如果一个数据被标识为冷数据,业务代码不会再对它进行写操作 -
不会同时存在读冷/热数据的需求。
如何实现冷热数据分离?
一切的理论知识都要经过实战的检验,基础知识了解了,那么如何实现冷热数据的分离呢?下面介绍三种常见的方法。
1、业务代码修改
这种方案是直接修改业务代码,对代码的侵入性比较高,无法按照时间进行区分,在数据修改时触发冷热分离。
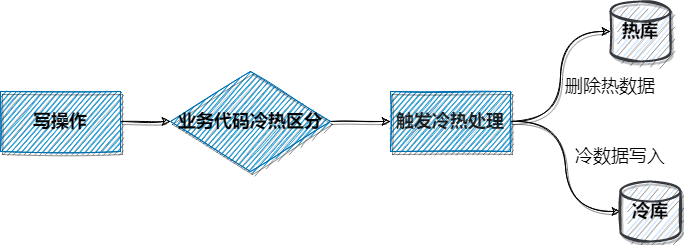
该种方案需要在业务代码层面判断是否需要冷热分离,比如订单的状态修改,一旦状态为终态则将这条数据标记为冷数据,然后触发冷热处理,将其写入冷库,同时删除热库中的这笔数据。
2、监听数据库日志
该种方案需要监听binlog日志的方式进行触发,比如订单状态修改了,则触发冷热分离。
同样的这里无法按照时间区分,但是对代码无侵入。
监听binlog日志的工具有很多,前面介绍过,比如阿里的canal,还有其他的开源中间件可供选择,如下:
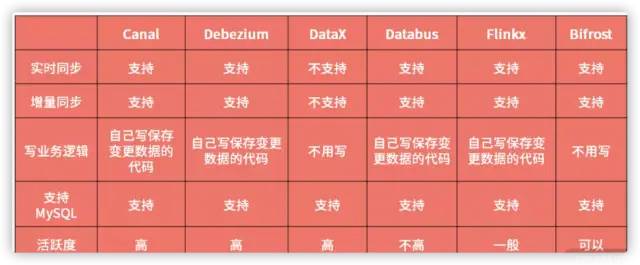
对于MySQL数据库建议选择canal,使用方式看:实战!Spring Boot 整合 阿里开源中间件 Canal 实现数据增量同步!
整个流程如下图:

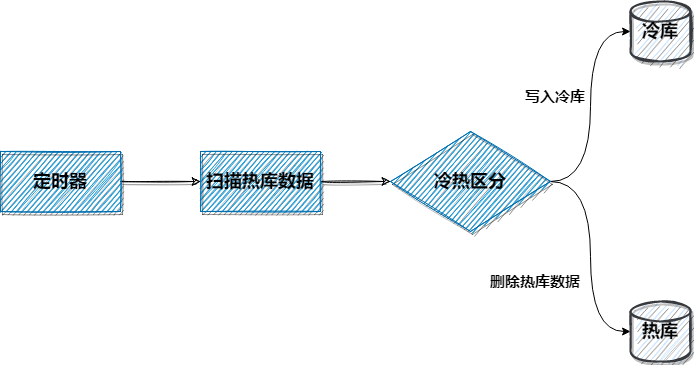
3、定时任务扫描
该种方案可以按照时间区分,与业务代码解耦,是个不错的选择。
流程如下:
总结
解决读写缓慢的问题冷热分离是个不错的选择,上述介绍了三种方案实现冷热分离,虽说都能实现,但是仍然要考虑诸多问题,最棘手的问题就是数据一致性的问题。
在冷热分离的处理逻辑中一定要保证热库、冷库中的数据一致性问题,手段很多,这里就不再过多介绍了。
0 条评论