select * from Country
where Country.code IN (select City.Country
from City
where City.Population > 7*1000*1000)
and Country.continent=‘Europe’
-
Materialize
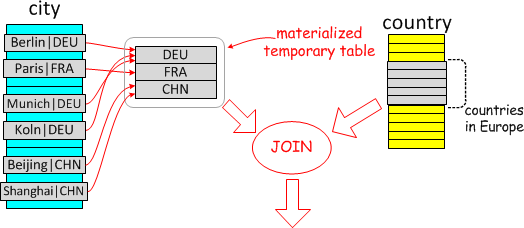
-
DuplicateWeedOut
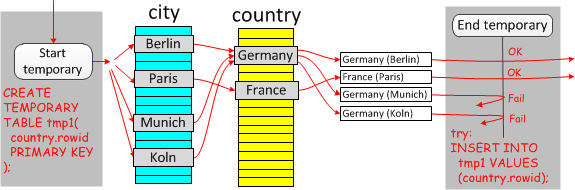
-
FirstMatch
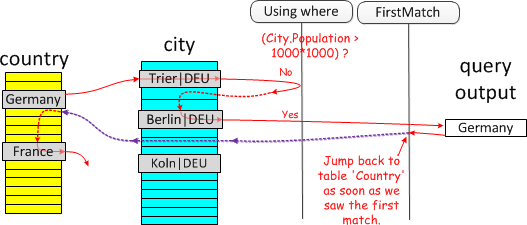
-
LooseScan
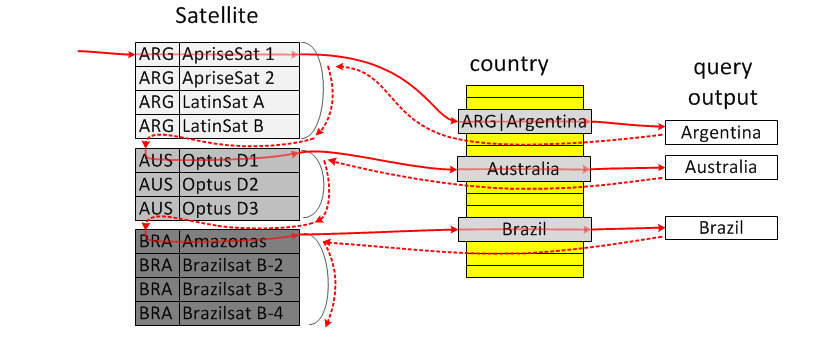
CREATE TABLE t1 (
a INT,
b INT,
KEY(a),
KEY(b)
);
INSERT INTO t1 VALUES (1, 2), (3, 4), (5, 6), (7, 8), (9, 10), (2, 1), (4, 3), (5, 6);
CREATE TABLE ct1 LIKE t1;
INSERT INTO ct1 SELECT * FROM t1;
CREATE TABLE ct2 LIKE t1;
INSERT INTO ct2 SELECT * FROM t1;
CREATE TABLE it1 LIKE t1;
INSERT INTO it1 SELECT * FROM t1;
CREATE TABLE it2 LIKE t1;
INSERT INTO it2 SELECT * FROM t1;
SELECT * FROM ct1, ct2 WHERE ct1.a IN (SELECT it1.a FROM it1, it2 WHERE it2.b = ct2.b);
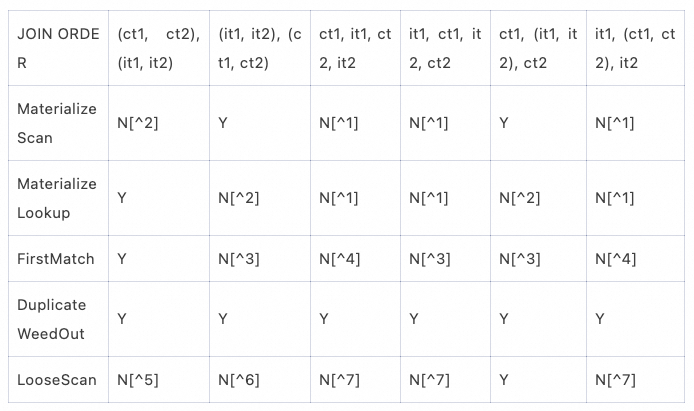
[^1]: Inner tables are not joined together.
[^2]: MaterializeLookup requires all dependent tables are in front of the inner tables. Use MaterializeScan instead.
[^3]: FirstMatch requires all dependent tables are in front of the inner tables.
[^4]: FirstMatch doesn’t allow any outer tables to be interleaved within inner tables.
[^5]: LooseScan requires there exists at least a correlated outer table appears after the LooseScan inner table.
[^6]: LooseScan requires all semijoin conditions after the LooseScan table are only dependent on index columns of LooseScan.
Semijoin 候选子查询的收集
1. 子查询是IN/EXIST类型,=ANY也会是IN子查询;
2. 是一个简单查询块(非UNION/INTERSECT/EXCEPT等集合操作符组成);
3. 不带有显式或隐式的聚集函数、不带有HAVING 和WINDOW函数(Semijoin 是将子查询里的表提出来与外层的表先join后再做后续运算,而这些操作符都是需要先读取完子查询里的表做运算后才能计算外层的谓词);
4. 子查询处于ON/WHERE语法中,且是AND谓词连接的top level;
外层查询将子查询的表上拉
消除原子查询
for SELECT#1 WHERE X IN (SELECT #2 WHERE Y IN (SELECT#3)) :
Query_block::prepare() (select#1)
-> fix_fields() on IN condition
-> Query_block::prepare() on subquery (select#2)
-> fix_fields() on IN condition
-> Query_block::prepare() on subquery (select#3)
<- Query_block::prepare()
<- fix_fields()
-> flatten_subqueries: merge #3 in #2
<- flatten_subqueries
<- Query_block::prepare()
<- fix_fields()
-> flatten_subqueries: merge #2 in #1
1. 将它们在外层查询块的谓词位置(WHERE 条件或者嵌套join的ON条件)用恒True表达式替换;
2. 创建semijoin nested Table_ref结构,加入到嵌套的join nest结构或者outer-most join list中,以下简称 (sj-nest);
3. 将子查询所有的表加入到Table_ref::NESTED_JOIN中,链接进外层查询的 leaf_tables,给这些表按照外层的tableno重新编号;
4. 构建NESTED_JOIN::sj_outer_exprs和NESTED_JOIN::sj_inner_exprs向量,IN 子查询就是左表达式和子查询投影列一一对应起来,EXIST子查询就是WHERE/ON 条件中的关联条件(IN子查询也会收集这些关联条件来方便执行使用),被收集的条件原有位置置空或者True,比如下列谓词:
ot1.a = ANY(SELECT it1.a FROM it1, it2)收集到sj_outer_exprs: ot1.a; sj_inner_exprs: it1.a
ot1.a = ANY(SELECT it1.a FROM it1, it2 WHERE it1.b = ot2.b)收集到 sj_outer_exprs: ot1.a, ot2.b; sj_inner_exprs: it1.a, it1.b。
5. 确定子查询中剩下的WHERE/ON条件所依赖的外层表集合 NESTED_JOIN::sj_corr_tables(非简单关联条件,用于优化过程中判断semijoin条件是否可计算);
6. 用sj_outer_exprs和sj_inner_exprs构建多个Item_func_eq表达式,与子查询剩下的 WHERE 条件结合,放入到外层查询对应JOIN/WHERE条件上;
执行策略的代价选择
-
pull_out_semijoin_tables
-
optimize_semijoin_nests_for_materialization
-
Optimize_table_order::best_extension_by_limited_search -> Optimize_table_order::advance_sj_state
Materialize
-
optimize_semijoin_nests_for_materialization
JOIN::make_join_plan -> optimize_semijoin_nests_for_materialization
|–遍历所有的 (sj–nest)
|–如果 NESTED_JOIN::sj_corr_tables 不为空,意味着子查询存在无法提取的复杂关联条件,这种情况下子查询无法独立物化,跳过
|–semijoin_types_allow_materialization/types_allow_materialization 检查类型能否物化,物化表索引长度是否超过最大值
|–Optimize_table_order::choose_table_order // 对 semijoin 的内表集合选取最优 join order
|–calculate_materialization_costs // 计算物化表的 NDV、物化的代价、全表扫物化表的代价、物化表 lookup 的代价,
// 存放在 NESTED_JOIN::Semijoin_mat_optimize 中,方便后续不同执行策略的代价比较
|–根据优化得到的 best_positions 里每个表的 read_cost 和 evaluate cost 计算物化代价和 fanout 行数
|–fanout 行数简单的与每个表的输出行数乘积取较小值作为物化表的输出 NDV
|–Cost_model_server::tmptable_readwrite_cost 计算物化表操作代价
|–将 best_positions 信息存储在 Semijoin_mat_optimize::positions 数组中作为 (sj–nest) 内表的最优计划
MaterializeScan
SET optimizer_switch=‘semijoin=on,materialization=on,loosescan=off,firstmatch=off,duplicateweedout=off’;
EXPLAIN SELECT /*+ JOIN_SUFFIX(ct1, ct2) */ * FROM ct1, ct2 WHERE ct1.a IN (SELECT it1.a FROM it1, it2 WHERE it2.b = ct2.b);
+—-+————–+————-+————+——-+—————+——+———+—————+——+———-+——————————————–+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+—-+————–+————-+————+——-+—————+——+———+—————+——+———-+——————————————–+
| 1 | SIMPLE | <subquery2> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | 100.00 | Using where |
| 1 | SIMPLE | ct1 | NULL | ref | a | a | 5 | <subquery2>.a | 1 | 100.00 | NULL |
| 1 | SIMPLE | ct2 | NULL | ref | b | b | 5 | <subquery2>.b | 1 | 100.00 | NULL |
| 2 | MATERIALIZED | it1 | NULL | index | a | a | 5 | NULL | 16 | 100.00 | Using index |
| 2 | MATERIALIZED | it2 | NULL | index | b | b | 5 | NULL | 16 | 100.00 | Using index; Using join buffer (hash join) |
+—-+————–+————-+————+——-+—————+——+———+—————+——+———-+——————————————–+
| -> Nested loop inner join (cost=259 rows=334)
-> Nested loop inner join (cost=142 rows=293)
-> Filter: ((`<subquery2>`.a is not null) and (`<subquery2>`.b is not null)) (cost=53.2..39.2 rows=256)
-> Table scan on <subquery2> (cost=53.3..59 rows=256)
-> Materialize with deduplication (cost=53.3..53.3 rows=256)
-> Filter: ((it1.a is not null) and (it2.b is not null)) (cost=27.7 rows=256)
-> Inner hash join (no condition) (cost=27.7 rows=256)
-> Index scan on it2 using b (cost=0.116 rows=16)
-> Hash
-> Index scan on it1 using a (cost=1.85 rows=16)
-> Index lookup on ct1 using a (a=`<subquery2>`.a) (cost=0.286 rows=1.14)
-> Index lookup on ct2 using b (b=`<subquery2>`.b) (cost=73.2 rows=1.14)
-
Optimize_table_order::advance_sj_state
-
如果当前 JOIN 前缀下,MaterializeScan已经是代价最低的策略,那么会标记当前外表的:
POSITION::sj_strategy
为SJ_OPT_MATERIALIZE_SCAN同时加入下一个外表时,不再重新考虑MaterializeScan的访问方式代价,因为此时已经将之前选择SJ_OPT_MATERIALIZE_SCAN的POSITION::prefix_cost/prefix_rowcount设置为MaterializeScan的结果值,所以后续表的访问方式评估时已经是基于MaterializeScan计划的cardinality和代价,不需要重新评估。
-
否则,如果MaterializeScan并不是当前最优的semijoin策略,那么会在greedy search搜索到下一个新表时重复进行考虑,因为 MaterializeScan下前序的 cardinality不同,对于后续表的访问方式都可能产生影响。
MaterializeLookup
SET optimizer_switch=‘semijoin=on,materialization=on,loosescan=off,firstmatch=off,duplicateweedout=off’;
EXPLAIN SELECT * FROM ct1, ct2 WHERE ct1.a IN (SELECT it1.a FROM it1, it2 WHERE it2.b = ct2.b);
+—-+————–+————-+————+——–+———————+———————+———+———————–+——+———-+——————————————————+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+—-+————–+————-+————+——–+———————+———————+———+———————–+——+———-+——————————————————+
| 1 | SIMPLE | ct1 | NULL | ALL | a | NULL | NULL | NULL | 8 | 100.00 | Using where |
| 1 | SIMPLE | ct2 | NULL | range | b | b | 5 | NULL | 8 | 100.00 | Using index condition; Using join buffer (hash join) |
| 1 | SIMPLE | <subquery2> | NULL | eq_ref | <auto_distinct_key> | <auto_distinct_key> | 10 | test.ct1.a,test.ct2.b | 1 | 100.00 | NULL |
| 2 | MATERIALIZED | it1 | NULL | index | a | a | 5 | NULL | 16 | 100.00 | Using index |
| 2 | MATERIALIZED | it2 | NULL | index | b | b | 5 | NULL | 16 | 100.00 | Using index; Using join buffer (hash join) |
+—-+————–+————-+————+——–+———————+———————+———+———————–+——+———-+——————————————————+
| -> Nested loop inner join (cost=1653 rows=16384)
-> Inner hash join (no condition) (cost=7.7 rows=64)
-> Index range scan on ct2 using b over (NULL < b), with index condition: (ct2.b is not null) (cost=0.131 rows=8)
-> Hash
-> Filter: (ct1.a is not null) (cost=1.05 rows=8)
-> Table scan on ct1 (cost=1.05 rows=8)
-> Single–row index lookup on <subquery2> using <auto_distinct_key> (a=ct1.a, b=ct2.b) (cost=53.3..53.3 rows=1)
-> Materialize with deduplication (cost=53.3..53.3 rows=256)
-> Filter: ((it1.a is not null) and (it2.b is not null)) (cost=27.7 rows=256)
-> Inner hash join (no condition) (cost=27.7 rows=256)
-> Index scan on it2 using b (cost=0.116 rows=16)
-> Hash
-> Index scan on it1 using a (cost=1.85 rows=16)
-
Optimize_table_order::advance_sj_state
DuplicateWeedOut
SET optimizer_switch=‘semijoin=on,materialization=off,loosescan=off,firstmatch=off,duplicateweedout=on’;
# 传统格式的 EXPLAIN 中比较明显的标识是 Start temporary/End temporary。
EXPLAIN SELECT * FROM ct1, ct2 WHERE ct1.a IN (SELECT it1.a FROM it1, it2 WHERE it2.b = ct2.b);
+—-+————-+——-+————+——-+—————+——+———+————+——+———-+——————————————————+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+—-+————-+——-+————+——-+—————+——+———+————+——+———-+——————————————————+
| 1 | SIMPLE | ct1 | NULL | ALL | a | NULL | NULL | NULL | 8 | 100.00 | Using where; Start temporary |
| 1 | SIMPLE | it1 | NULL | ref | a | a | 5 | test.ct1.a | 2 | 100.00 | Using index |
| 1 | SIMPLE | ct2 | NULL | range | b | b | 5 | NULL | 8 | 100.00 | Using index condition; Using join buffer (hash join) |
| 1 | SIMPLE | it2 | NULL | ref | b | b | 5 | test.ct2.b | 2 | 100.00 | Using index; End temporary |
+—-+————-+——-+————+——-+—————+——+———+————+——+———-+——————————————————+
| -> Remove duplicate (ct1, ct2) rows using temporary table (weedout) (cost=89.8 rows=334)
-> Nested loop inner join (cost=89.8 rows=334)
-> Inner hash join (no condition) (cost=19.8 rows=146)
-> Index range scan on ct2 using b over (NULL < b), with index condition: (ct2.b is not null) (cost=0.0574 rows=8)
-> Hash
-> Nested loop inner join (cost=4.88 rows=18.3)
-> Filter: (ct1.a is not null) (cost=1.05 rows=8)
-> Table scan on ct1 (cost=1.05 rows=8)
-> Covering index lookup on it1 using a (a=ct1.a) (cost=0.279 rows=2.29)
-> Covering index lookup on it2 using b (b=ct2.b) (cost=1.32 rows=2.29)
|
-
Optimize_table_order::advance_sj_state
-
执行过程
WeedoutIterator::Read
|–m_source -> RowIterator::Read // 调用子算子完成前序 JOIN 过程
|–do_sj_dups_weedout
|–对涉及到的外表主键使用 memcpy 进行紧密填充
|–handler::ha_write_row // 向临时表中写入 rowids 字段进行去重
FirstMatch
SET optimizer_switch=‘semijoin=on,materialization=off,loosescan=off,firstmatch=on,duplicateweedout=off’;
EXPLAIN SELECT * FROM ct1, ct2 WHERE ct1.a IN (SELECT it1.a FROM it1, it2 WHERE it2.b = ct2.b);
+—-+————-+——-+————+——-+—————+——+———+————+——+———-+——————————————————+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+—-+————-+——-+————+——-+—————+——+———+————+——+———-+——————————————————+
| 1 | SIMPLE | ct1 | NULL | ALL | a | NULL | NULL | NULL | 8 | 100.00 | Using where |
| 1 | SIMPLE | ct2 | NULL | range | b | b | 5 | NULL | 8 | 100.00 | Using index condition; Using join buffer (hash join) |
| 1 | SIMPLE | it1 | NULL | ref | a | a | 5 | test.ct1.a | 2 | 100.00 | Using index |
| 1 | SIMPLE | it2 | NULL | ref | b | b | 5 | test.ct2.b | 2 | 100.00 | Using index; FirstMatch(ct2) |
+—-+————-+——-+————+——-+—————+——+———+————+——+———-+——————————————————+
| -> Nested loop semijoin (cost=57.2 rows=334)
-> Inner hash join (no condition) (cost=7.7 rows=64)
-> Index range scan on ct2 using b over (NULL < b), with index condition: (ct2.b is not null) (cost=0.131 rows=8)
-> Hash
-> Filter: (ct1.a is not null) (cost=1.05 rows=8)
-> Table scan on ct1 (cost=1.05 rows=8)
-> Nested loop inner join (cost=37.4 rows=5.22)
-> Covering index lookup on it1 using a (a=ct1.a) (cost=0.254 rows=2.29)
-> Covering index lookup on it2 using b (b=ct2.b) (cost=1.32 rows=2.29)
|
Optimize_table_order::advance_sj_state-
执行过程
NestedLoopIterator::Read
|–m_source_outer -> RowIterator::Read // 调用子算子读取外表的一行数据
|–m_source_inner -> RowIterator::Read // 读取内表的一行数据
|–一般情况下 INNER JOIN 状态会设置为 READING_INNER_ROWS 持续访问内表数据
|–当类型为 JoinType::SEMI 时,直接设置状态为 NEEDS_OUTER_ROW,下次迭代调用时便会读外表的下一行数据
LooseScan
SET optimizer_switch=‘semijoin=on,materialization=off,loosescan=on,firstmatch=off,duplicateweedout=off’;
EXPLAIN SELECT * FROM ct1, ct2 WHERE ct1.a IN (SELECT it1.a FROM it1, it2 WHERE it2.b = ct2.b);
+—-+————-+——-+————+——-+—————+——+———+————+——+———-+————————————-+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+—-+————-+——-+————+——-+—————+——+———+————+——+———-+————————————-+
| 1 | SIMPLE | ct1 | NULL | ALL | a | NULL | NULL | NULL | 8 | 100.00 | Using where |
| 1 | SIMPLE | it2 | NULL | index | b | b | 5 | NULL | 16 | 43.75 | Using where; Using index; LooseScan |
| 1 | SIMPLE | it1 | NULL | ref | a | a | 5 | test.ct1.a | 2 | 100.00 | Using index; FirstMatch(it2) |
| 1 | SIMPLE | ct2 | NULL | ref | b | b | 5 | test.it2.b | 1 | 100.00 | NULL |
+—-+————-+——-+————+——-+—————+——+———+————+——+———-+————————————-+
| -> Nested loop inner join (cost=129 rows=146)
-> Nested loop inner join (cost=30.6 rows=128)
-> Filter: (ct1.a is not null) (cost=1.05 rows=8)
-> Table scan on ct1 (cost=1.05 rows=8)
-> Nested loop semijoin with duplicate removal on b (cost=33.8 rows=16)
-> Filter: (it2.b is not null) (cost=0.119 rows=7)
-> Index scan on it2 using b (cost=0.119 rows=16)
-> Covering index lookup on it1 using a (a=ct1.a) (cost=0.252 rows=2.29)
-> Index lookup on ct2 using b (b=it2.b) (cost=10.5 rows=1.14)
|
-
Optimize_table_order::advance_sj_state
1. 新加入的表为第一个出现的 (sj-nest) 内表;
2. Keyuse不为空(带有索引选择信息);
3. 无法提取为sj-cond的关联条件依赖的表(sj_corr_tables)都已经在JOIN前缀里(因为即使LooseScan扫描的结果是去重的,但是在复杂条件上仍然可能和外表JOIN出多条记录);
1. 完成所有inner_tables JOIN之后,已经满足的sj-cond集合(依赖的外表全在 JOIN 前缀),用bound_sj_equalities表示(由于FirstMatch的实现,存在唯一的一行值满足这部分sj-cond);
2. Keyuse的信息(ref 前序表和LooseScan的产出列)组成了索引前缀,这样才能做 LooseScan去重;
-
执行过程
NestedLoopSemiJoinWithDuplicateRemovalIterator::Init
|–IndexScanIterator<false>::Init -> ha_innobase::index_init
NestedLoopSemiJoinWithDuplicateRemovalIterator::Read
|–m_source_outer->Read() // 读取 LooseScan 表一行
|–如果 m_deduplicate_against_previous_row 为 True,且比较索引 key 相同,那么继续读取下一行记录
|–m_source_inner->Init() & m_source_inner->Read() // 内表读取一行 JOIN,由于对于每一行 LooseScan 记录,都重新 Init 和读取内表一行,不存在循环读取内表,通过这种方式实现 FirstMatch
|–标记 m_deduplicate_against_previous_row 为 True 表示需要比较 Key 是否相同,并存储当前的 Key
根据确定的策略做执行前准备
-
Optimize_table_order::fix_semijoin_strategies
[ot1 it1 it2 ot2 ot3]sjX sjY -- sjX and sjY are different strategies
在得到最优的JOIN ORDER后,需要从后往前遍历每个POSITION位置上的sj-strategy,因为靠后位置上记录的是更大JOIN前缀范围内最优的策略。优化过程中对范围内表的访问方式的考虑是没有记录到POSITION中的(只是算了总代价),在这里应该根据确定的执行策略,将这些访问方式进行持久化。
-
make_join_readinfo -> setup_semijoin_dups_elimination
参考:
[1] Source code mysql / mysql-server 8.0.33:https://github.com/mysql/mysql-server/tree/mysql-8.0.33
[2] MySQL·源码分析·Semi-join优化执行代码分析:https://zhuanlan.zhihu.com/p/382416772
0 条评论