*)、count(字段) 等。*) 效率最差?*) 是效率最差的,因为认知上 selete * from t 会读取所有表中的字段,所以凡是带有 * 字符的就觉得会读取表中所有的字段,当时网上有很多博客也这么说。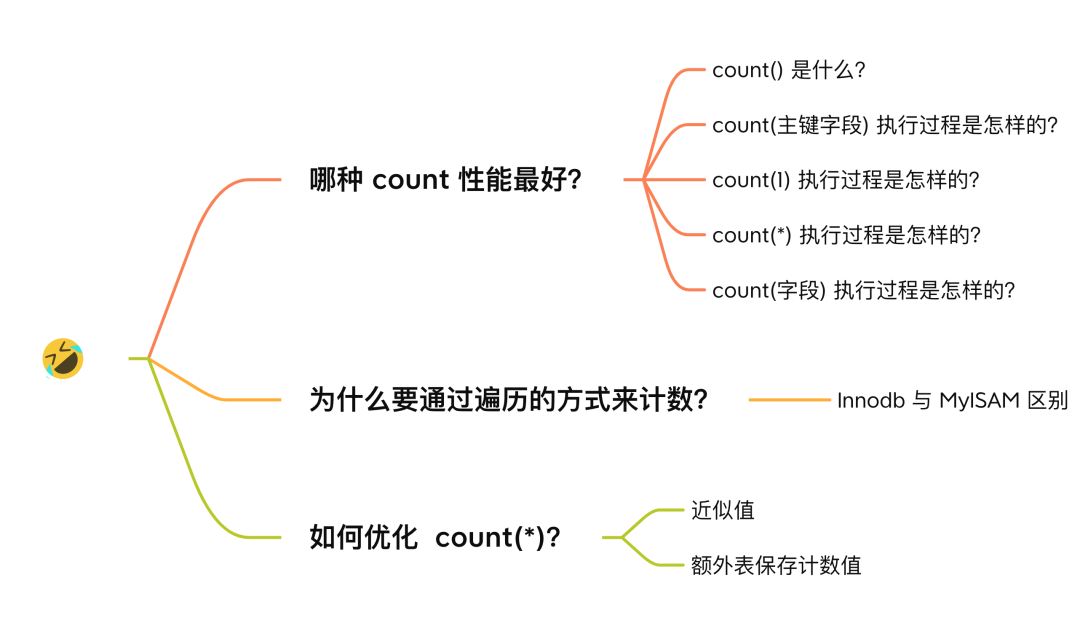
哪种 count 性能最好?
哪种 count 性能最好?

count() 是什么?
count(主键字段) 执行过程是怎样的?
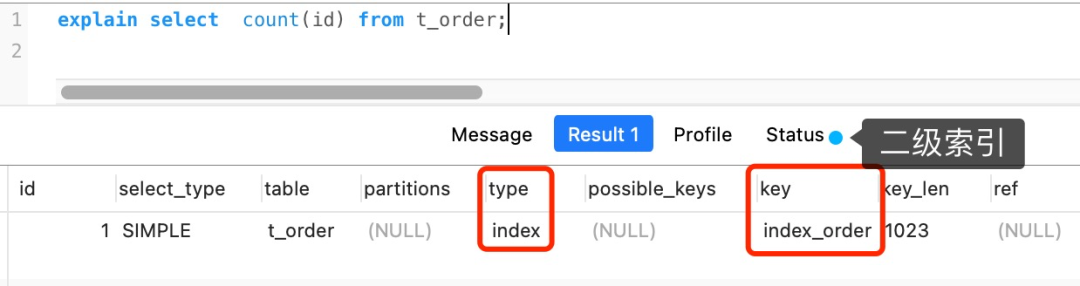
select count(id) from t_order;

count(1) 执行过程是怎样的?


count(*) 执行过程是怎样的?
* 这个字符的时候,是不是大家觉得是读取记录中的所有字段值?selete * 这条语句来说是这个意思,但是在 count(*) 中并不是这个意思。*) 其实等于 count(0),也就是说,当你使用 count(*) 时,MySQL 会将 * 参数转化为参数 0 来处理。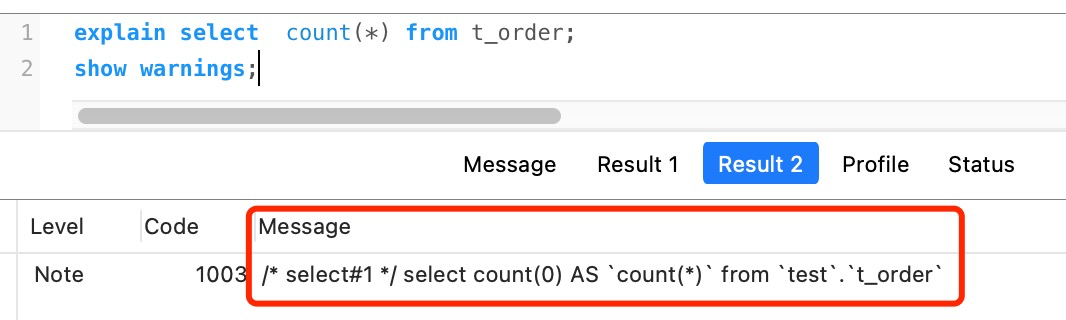
*) and SELECT COUNT(1) operations in the same way. There is no performance difference.*)和 SELECT COUNT(1)操作,没有性能差异。count(字段) 执行过程是怎样的?
select count(name) from t_order;

小结
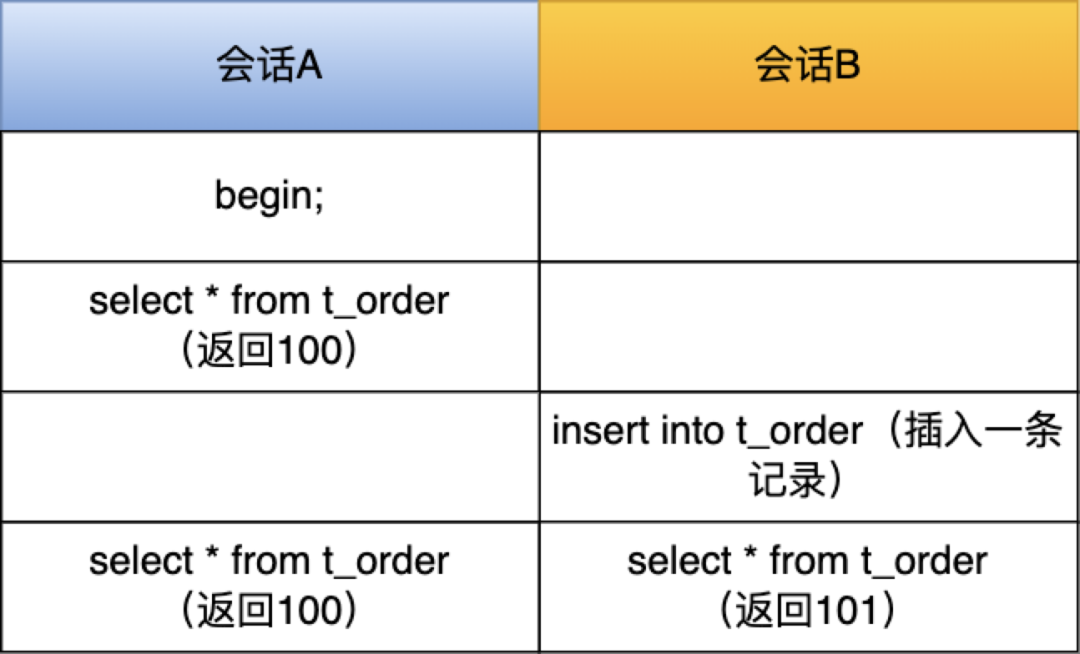
为什么要通过遍历的方式来计数?
如何优化 count(*)?
select count(*) from t_order 要花费差不多 5 秒!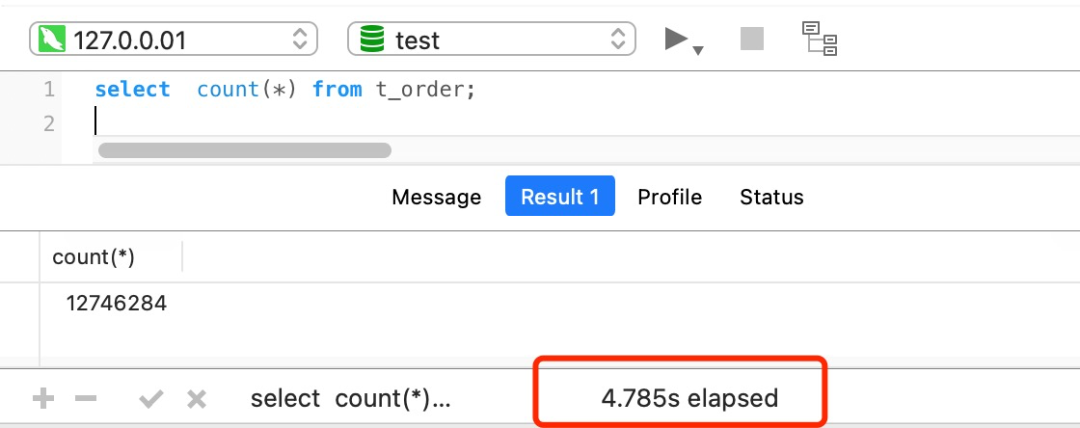

0 条评论