我们知道,大部分的业务场景都是读多写少,为了利用好这个特性,提升Redis集群系统的吞吐能力,通常会采用主从架构、读写分离
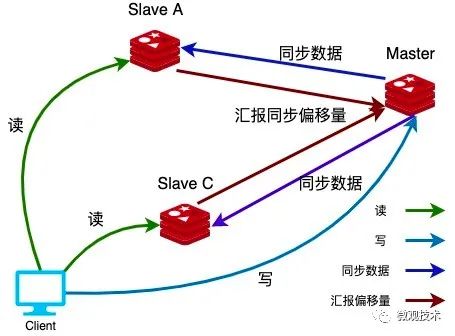
如上图所示:其中
-
Master节点:负责业务的写操作 -
Slave节点:实时同步Master节点的数据,提供读能力
为了提高吞吐量,采用一主多从的架构,将业务的读压力分摊到多台服务器上
上述方案,看似合理,但其实可能存在一定隐患!
一、拉取过期数据
Redis性能高主要得益于纯内存操作,但内存存储介质的成本过高,所以数据的存储有一定的约束。
通常会设置过期时间,对于一些使用不是很频繁的数据,会定期删除,提高资源的利用率。
删除过期数据,Redis提供了两种策略:
1、惰性删除。
也称被动删除,当数据过期后,并不会马上删除。而是等到有请求访问时,对数据检查,如果数据过期,则删除数据。
优点:不需要单独启动额外的扫描线程,减少了CPU资源的损耗。
缺点:大量的过期数据滞留内存中,需要主动触发、检查、删除,否则会一直占用内存资源。
2、定期删除。每隔一段时间,默认100ms,Redis会随机挑选一定数量的Key,检查是否过期,并将过期的数据删除。
你可能会为问了,既然Redis有过期数据删除策略,那为什么还会拉取到已经过期的数据呢?

这要从主从同步讲起了,我们先来看张流程图
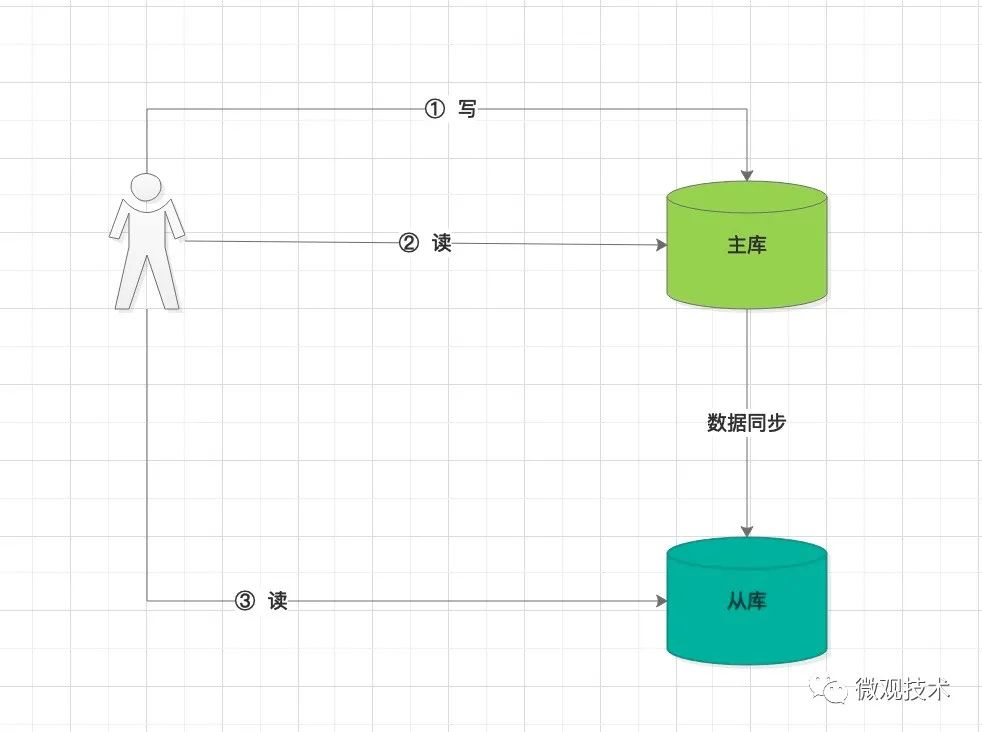
当客户端往主库写入数据后,并设置了过期时间,数据会以异步方式同步给从库。
1、如果此时读主库,数据已经过期,主库的惰性删除会发挥作用,主动触发删除操作,客户端不会拿到已过期数据
2、但是如果读从库,则有可能拿到过期数据。原因有两个
原因一:
跟 Redis 的版本有关系,Redis 3.2 之前版本,读从库并不会判断数据是否过期,所以有可能返回过期数据。
解决方案:
升级Redis的版本,至少要3.2 以上版本,读从库,如果数据已经过期,则会过滤并返回空值。
特别注意:
此时同步过来的数据,虽然已经过期,但本着谁生产谁维护的原则,从库并不会主动删除同步的数据,需要依赖于主节点同步过来的key删除命令。
原因二:
跟过期时间的设置方式有关系,我们一般采用 EXPIRE 和 PEXPIRE,表示从执行命令那个时刻开始,往后延长 ttl 时间。严重依赖于 开始时间 从什么时候算起。
-
EXPIRE:单位为秒 -
PEXPIRE:单位为毫秒
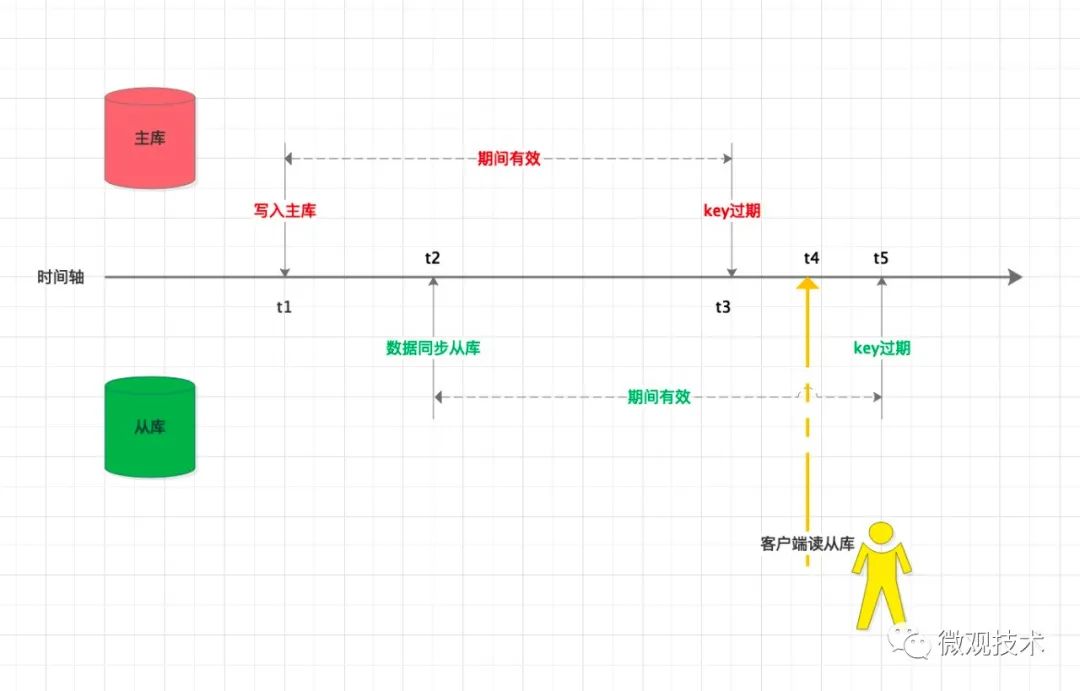
如上图所示,简单描述下过程:
-
主库在 t1 时刻写入一个带过期时间的数据,数据的有效期一直到 t3 -
由于网络原因、或者缓存服务器的执行效率,从库的命令并没有立即执行。一直等到了 t2 才开始执行,
数据的有效期则会延后到 t5 -
如果,此时客户端访问从库,发现数据依然处于有效期内,可以正常使用
解决方案:
可以采用Redis的另外两个命令,EXPIREAT 和 PEXPIREAT,相对简单,表示过期时间为一个具体的时间点。避免了对开始时间从什么时候算起的依赖。
-
EXPIREAT:单位为秒 -
PEXPIREAT:单位为毫秒
特别注意:
EXPIREAT 和 PEXPIREAT 设置的是时间点,所以要求主从节点的时钟保持一致,需要与NTP 时间服务器保持时钟同步。

主从同步,除了读从库可能拉取到过期数据,还可能遇到数据一致性问题。
继续往下看
二、主从数据不一致
解释下,什么是主从数据不一致?指客户端从库中读取到的值与主库中读取的值不一致!
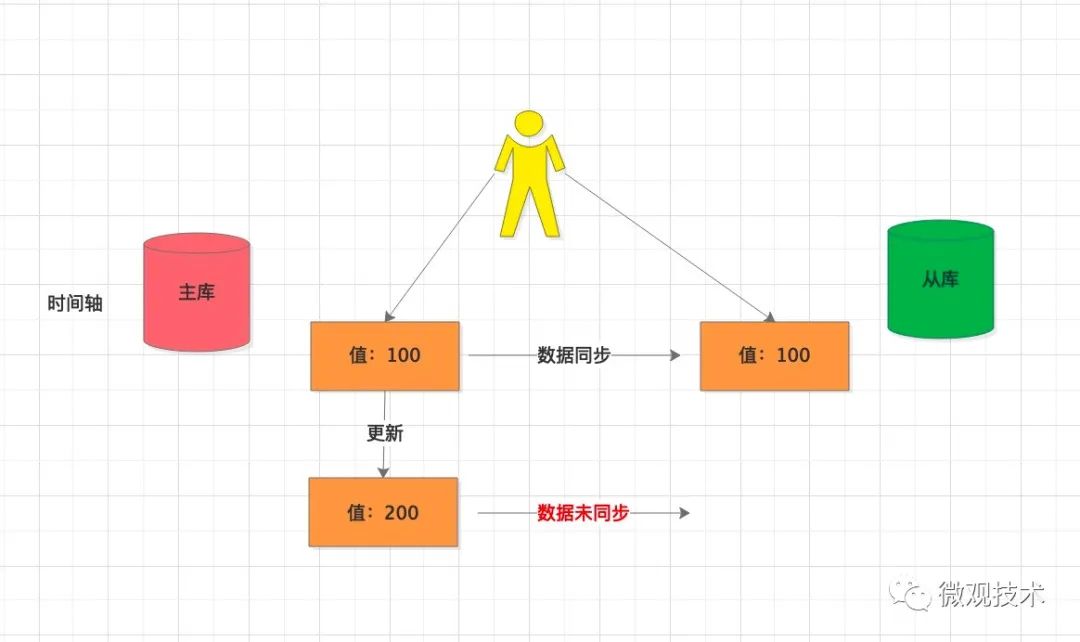
如图所示:
-
客户端写入主库,值为100 -
然后,主库将值100 同步给 从库 -
接着,客户端又访问主库,将值更新为 200 -
由于主从同步是异步进行的,有一定延迟,假如最新数据还没有同步到从库,那么从库读取的就不是最新值。
从库同步落后的原因主要有两个:
1、主从服务器间的网络传输可能有延迟
2、从库已经收到主库的命令,由于是单线程执行,前面正在处理一些耗时的命令(如:pipeline批处理),无法及时同步执行。
解决方案:
1、主从服务器尽量部署在同一个机房,并保持服务器间的网络良好通畅
2、监控主从库间的同步进度,通过info replication命令 ,查看主库接收写命令的进度信息(master_repl_offset),从库的复制写命令的进度信息(slave_repl_offset)
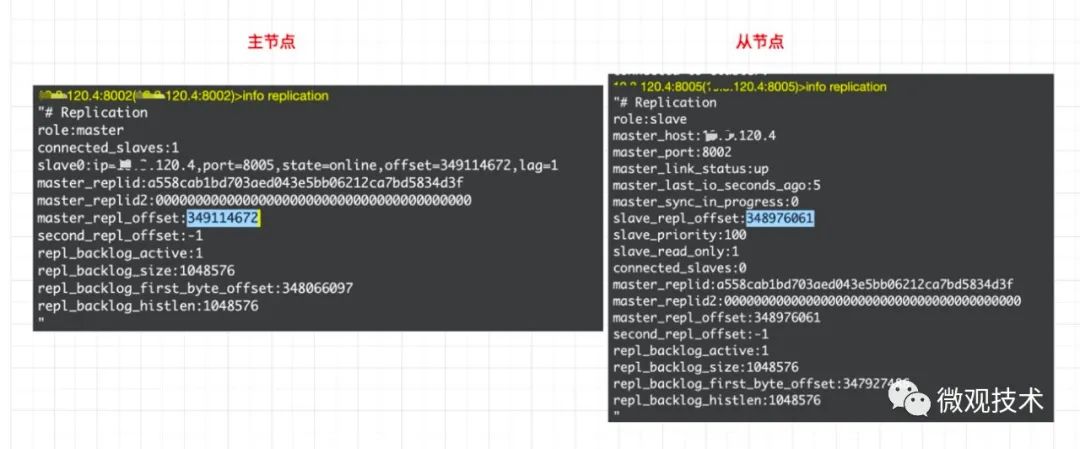
master_repl_offset – slave_repl_offset
得到从库与主库间的复制进度差
我们可以开发一个监控程序,定时拉取主从服务器的进度信息,计算进度差值。如果超过我们设置的阈值,则通知客户端断开从库的连接,全部访问主库,一定程度上减少数据不一致情况。
待同步进度跟上后,我们再恢复客户端与从节点的读操作。
— end —
0 条评论