分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。
-
入口级负载均衡
-
网关负载均衡
-
客户端负载均衡
-
-
单应用架构
-
应用服务和数据服务分离
-
应用服务集群
-
应用服务中心化SAAS
-
-
数据库主备读写分离
-
全文搜索引擎加快数据统计
-
缓存集群缓解数据库读压力
-
分布式消息中间件缓解数据库写压力
-
数据库水平拆分适应微服务
-
数据库垂直拆分解决慢查询
-
-
划分上下文拆分微服务
-
服务注册发现(Eureka、Nacos)
-
配置动态更新(Config、Apollo)
-
业务灰度发布(Gateway、Feign)
-
统一安全认证(Gateway、Auth)
-
服务降级限流(Hystrix、Sentinel)
-
接口检查监控(Actuator、Prometheus)
-
服务全链路追踪(Sleuth、Zipkin)
-
-
一致性(2PC、3PC、Paxos、Raft)
-
强一致性:数据库一致性,牺牲了性能
-
-
-
ACID:原子性、一致性、隔离性、持久性
-
-
-
弱一致性:数据库和缓存,延迟双删、重试
-
单调读一致性:缓存一致性,ID或者IP哈希
-
最终一致性:边缘业务,消息队列
-
-
可用性(多级缓存、读写分离)
-
BASE 基本可用:限流导致响应速度慢、降级导致用户体验差
-
-
-
Basically Availabe 基本可用
-
Soft state 软状态
-
Eventual Consistency 最终一致性
-
-
分区容忍性(一致性Hash解决扩缩容问题)
XA方案
-
准备阶段:询问是否可以开始,写Undo、Redo日志,收到响应; -
提交阶段:执行Redo日志进行Commit,执行Undo日志进行Rollback;
Paxos算法
如何在一个发生异常的分布式系统中,快速且正确地在集群内部对某个数据的值达成一致。
-
Client:客户端、例如,对分布式文件服务器中文件的写请求。 -
Proposer:提案发起者,根据Accept返回选择最大N对应的V,发送[N+1,V] -
Acceptor:决策者,Accept以后会拒绝小于N的提案,并把自己的[N,V]返回给Proposer -
Learners:最终决策的学习者、学习者充当该协议的复制因素
//算法约束P1:一个Acceptor必须接受它收到的第一个提案。//考虑到半数以上才作数,一个Accpter得接受多个相同v的提案P2a:如果某个v的提案被accept,那么被Acceptor接受编号更高的提案必须也是vP2b:如果某个v的提案被accept,那么从Proposal提出编号更高的提案必须也是v//如何确保v的提案Accpter被选定后,Proposal都能提出编号更高的提案呢针对任意的[Mid,Vid],有半数以上的Accepter集合S,满足以下二选一:S中接受的提案都大于Mid S中接受的提案若小于Mid,编号最大的那个值为Vid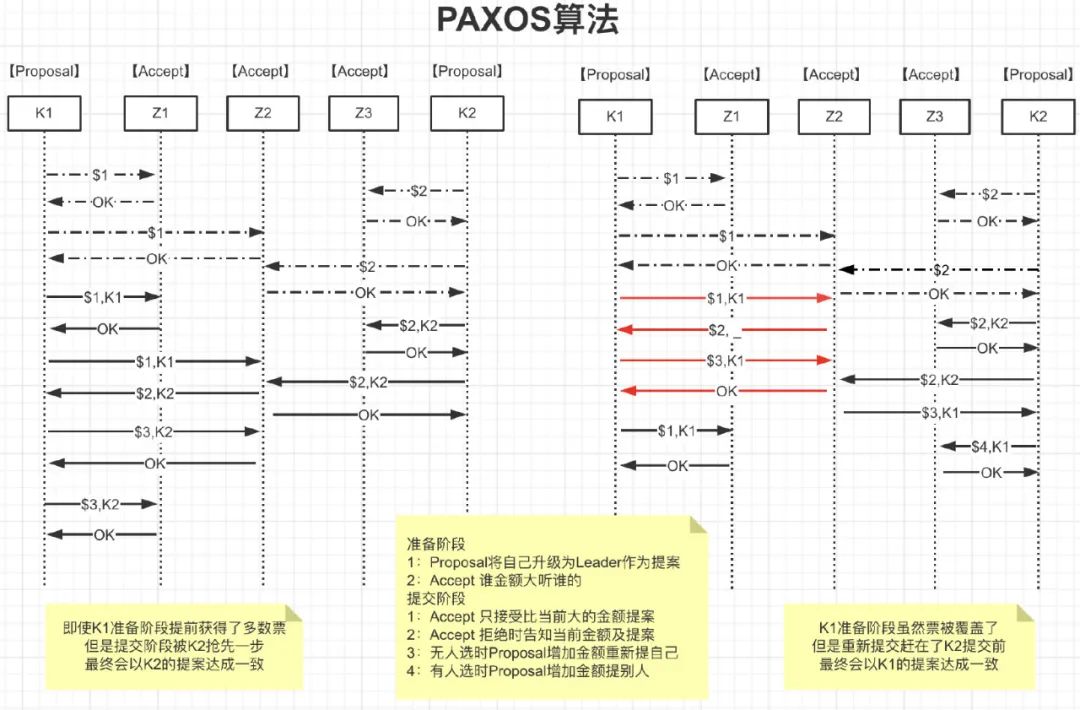
-
通过选取主Proposer,规定只有主Proposer才能提出议案。只要主Proposer和过半的Acceptor能够正常网络通信,主Proposer提出一个编号更高的提案,该提案终将会被批准;
-
每个Proposer发送提交提案的时间设置为一段时间内随机,保证不会一直死循环;
Raft算法
Raft 是一种为了管理复制日志的一致性算法
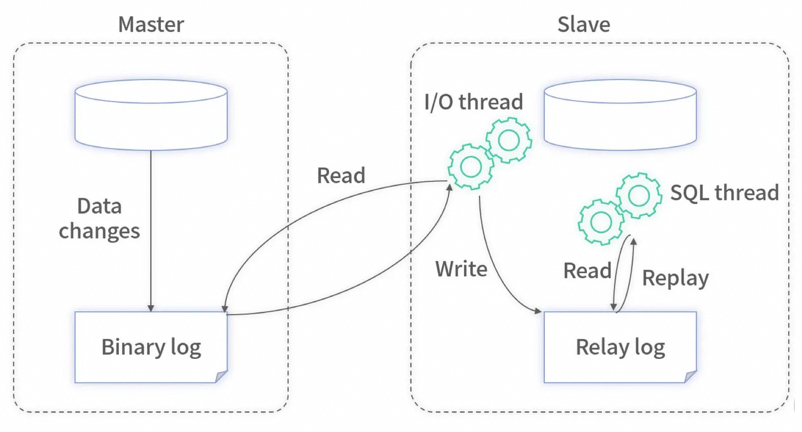
数据库和Redis的一致性


-
大幅提升了读取的速度,降低了延迟;
-
Binlog 的主从复制是基于 ACK 机制, 解决了分布式事务的问题; 如果同步缓存失败了,被消费的 Binlog 不会被确认,下一次会重复消费,数据最终会写入缓存中;
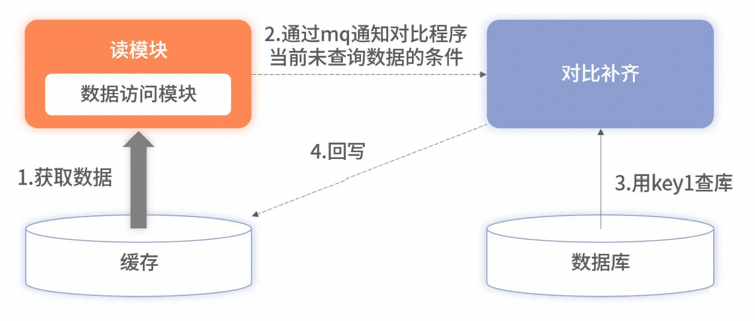
心跳检测
以固定的频率向其他节点汇报当前节点状态的方式。收到心跳,说明网络和节点的状态是健康的。心跳汇报时,一般会携带一些附加的状态、元数据,以便管理。
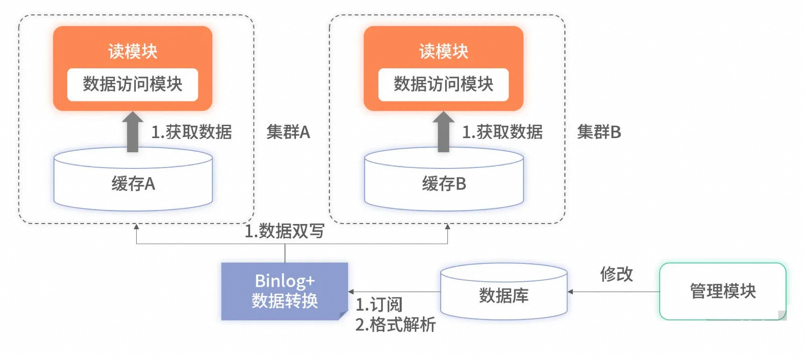
多机房实时热备
-
提升了性能。读服务不要分层,读服务要尽可能地和缓存数据源靠近。
-
增加了可用。当单机房出现故障时,可以秒级将所有流量都切换至存活的机房或分区。
分布式系统对于错误包容的能力
日志复制
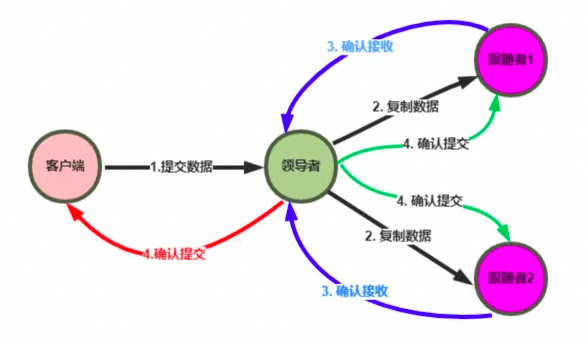
-
Leader把指令添加到日志中,发起 RPC 给其他的服务器,让他们复制这条信息;
-
Leader会不断的重试,直到所有的 Follower响应了ACK并复制了所有的日志条目;
-
通知所有的Follower提交,同时Leader该表这条日志的状态,并返回给客户端;
主备(Master-Slave)
互备(Active-Active)
集群(Cluster)模式
XA方案
-
准备阶段的资源锁定,存在性能问题,严重时会造成死锁问题;
-
提交事务请求后,出现网络异常,部分数据收到并执行,会造成一致性问;
TCC方案
-
Try 阶段:这个阶段说的是对各个服务的资源做检测以及对资源进行锁定或者预留;
-
Confirm 阶段:这个阶段说的是在各个服务中执行实际的操作;
-
Cancel 阶段:如果任何一个服务的业务方法执行出错,那么就需要进行补偿/回滚;
Saga方案
-
流程长、流程多、调用第三方业务
本地消息表(eBay)
MQ最终一致性

-
A(订单) 系统先发送一个 prepared 消息到 mq,prepared 消息发送失败则取消操作不执行了;
-
发送成功后,那么执行本地事务,执行成功和和失败发送确认和回滚消息到mq;
-
如果发送了确认消息,那么此时 B**(仓储)** 系统会接收到确认消息,然后执行本地的事务;
-
mq 会自动定时轮询所有 prepared 消息回调的接口,确认事务执行状态;
-
B 的事务失败后自动不断重试直到成功,达到一定次数后发送报警由人工来手工回滚和补偿;
最大努力通知方案(订单 -> 积分)
-
系统 A 本地事务执行完之后,发送个消息到 MQ;
-
这里会有个专门消费 MQ 的最大努力通知服务,接着调用系统 B 的接口;
-
要是系统 B 执行失败了,就定时尝试重新调用系统 B,反复 N 次,最后还是不行就放弃;
分布式Session实现方案
-
基于JWT的Token,数据从cache或者数据库中获取;
-
基于Tomcat的Redis,简单配置conf文件;
-
基于Spring的Redis,支持SpringCloud和Springboot;
0 条评论