今天,我们来聊一道常见的考题,具体的题目如下:
文件中有40亿个QQ号码,请设计算法对QQ号码去重,相同的QQ号码仅保留一个,内存限制1G.
这个题目的意思应该很清楚了,比较直白。为了便于大家理解,我来画个动图玩玩,希望大家喜欢。

能否做对这道题目,很大程度上就决定了能否拿下腾讯的offer,有一定的技巧性,一起来看下吧。
在原题中,实际有40亿个QQ号码,为了方便起见,在图解和叙述时,仅以4个QQ为例来说明。
方法一:排序
很自然地,最简单的方式是对所有的QQ号码进行排序,重复的QQ号码必然相邻,保留第一个,去掉后面重复的就行。
原始的QQ号为:

排序后的QQ号为:

去重就简单了:

可是,面试官要问你,去重一定要排序吗?显然,排序的时间复杂度太高了,无法通过腾讯面试。
方法二:hashmap
既然直接排序的时间复杂度太高,那就用hashmap吧,具体思路是把QQ号码记录到hashmap中:
mapFlag[123] = truemapFlag[567] = truemapFlag[123] = truemapFlag[890] = true
mapFlag[123] = truemapFlag[567] = truemapFlag[890] = true
可是,面试官又要问你了:实际要存40亿QQ号码,1G的内存够分配这么多空间吗?显然不行,无法通过腾讯面试。
方法三:文件切割
显然,这是海量数据问题。看过很多面经的求职者,自然想到文件切割的方式,避免内存过大。
可是,绞尽脑汁思考,要么使用文件间的归并排序,要么使用桶排序,反正最终是能排序的。
既然排序好了,那就能实现去重了,貌似就万事大吉了。我只能坦白地说,高兴得有点早哦。
接着,面试官又要问你:这么多的文件操作,效率自然不高啊。显然,无法通过腾讯面试。
方法四:bitmap
来看绝招!我们可以对hashmap进行优化,采用bitmap这种数据结构,可以顺利地同时解决时间问题和空间问题。
在很多实际项目中,bitmap经常用到。我看了不少组件的源码,发现很多地方都有bitmap实现,bitmap图解如下:

这是一个unsigned char类型,可以看到,共有8位,取值范围是[0, 255],如上这个unsigned char的值是255,它能标识0~7这些数字都存在。
同理,如下这个unsigned char类型的值是254,它对应的含义是:1~7这些数字存在,而数字0不存在:
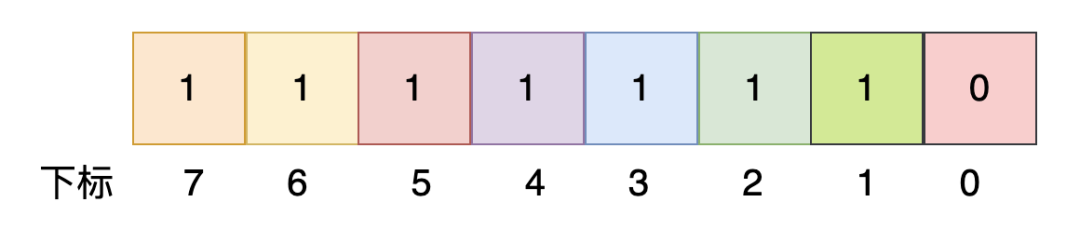
由此可见,一个unsigned char类型的数据,可以标识0~7这8个整数的存在与否。以此类推:
-
一个unsigned int类型数据可以标识0~31这32个整数的存在与否。
-
两个unsigned int类型数据可以标识0~63这64个整数的存在与否。
显然,可以推导出来:512MB大小足够标识所有QQ号码的存在与否,请注意:QQ号码的理论最大值为2^32 – 1,大概是43亿左右。
接下来的问题就很简单了:用512MB的unsigned int数组来记录文件中QQ号码的存在与否,形成一个bitmap,比如:
bitmapFlag[123] = 1bitmapFlag[567] = 1bitmapFlag[123] = 1bitmapFlag[890] = 1
bitmapFlag[123] = 1bitmapFlag[567] = 1bitmapFlag[890] = 1
扩展练习一
文件中有40亿个互不相同的QQ号码,请设计算法对QQ号码进行排序,内存限制1G.
很显然,直接用bitmap, 标记这40亿个QQ号码的存在性,然后从小到大遍历正整数,当bitmapFlag的值为1时,就输出该值,输出后的正整数序列就是排序后的结果。
请注意,这里必须限制40亿个QQ号码互不相同。通过bitmap记录,客观上就自动完成了排序功能。
扩展练习二
文件中有40亿个互不相同的QQ号码,求这些QQ号码的中位数,内存限制1G.
我知道,一些刷题经验丰富的人,最开始想到的肯定是用堆或者文件切割,这明显是犯了本本主义错误。直接用bitmap排序,当场搞定中位数。
扩展练习三
文件中有40亿个互不相同的QQ号码,求这些QQ号码的top-K,内存限制1G.
我知道,很多人背诵过top-K问题,信心满满,想到用小顶堆或者文件切割,这明显又是犯了本本主义错误。直接用bitmap排序,当场搞定top-K问题。
扩展练习四
文件中有80亿个QQ号码,试判断其中是否存在相同的QQ号码,内存限制1G.
我知道,一些吸取了经验教训的人肯定说,直接bitmap啊。然而,又一次错了。根据容斥原理可知:
因为QQ号码的个数是43亿左右(理论值2^32 – 1),所以80亿个QQ号码必然存在相同的QQ号码。
海量数据的问题,要具体问题具体分析,不要眉毛胡子一把抓。
0 条评论