计算机网络的重要程度不言而言,也是非常的复杂。今天我将从输入URL这个简单例子开始,一起探索数据包的心路历程。先看文章的大纲。
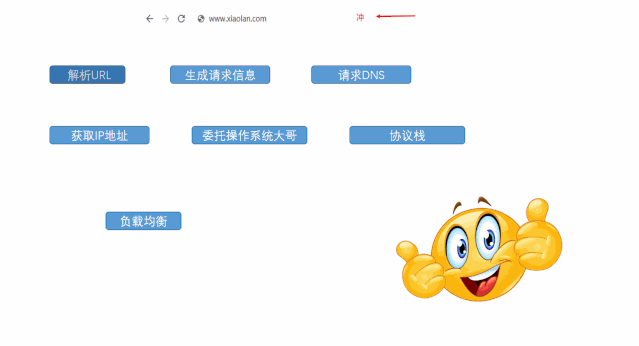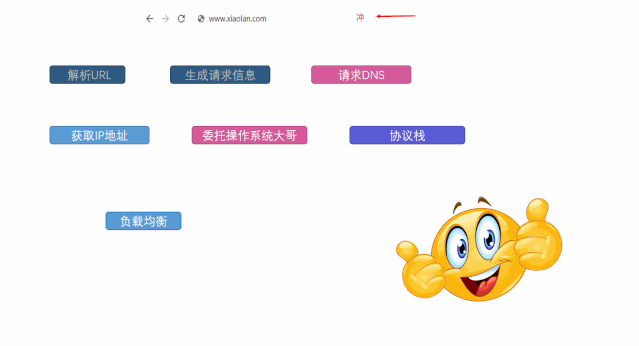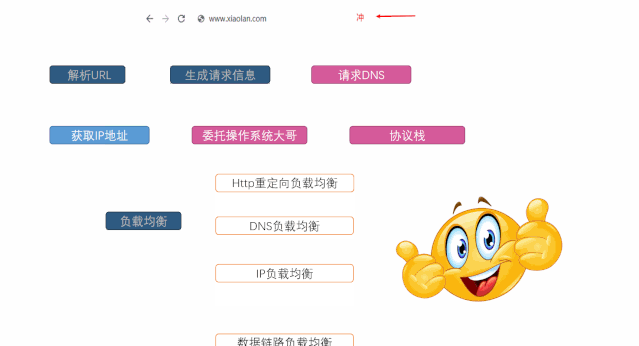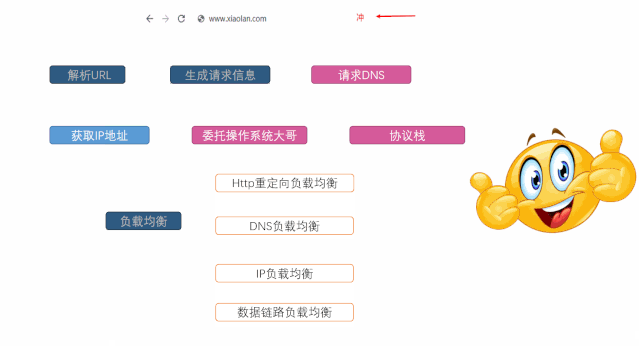
大纲
1 源头——网址
网址即平时所说的URL。就是经常使用的以“Http://”开头的那一串东东,其实常用的还有很多,比如 “FTP” , “FILE”等,我们所访问的目标网站不同,网址开头的写法也就不同,下面列出常见的几种URL。

URL基本格式
从上图可知,URL 中可以包含服务器的域名,文件的路径,收件人邮件地址,用户名,密码等信息。总之URL想表达的是:
-
访问时所使用的协议。”HTTP” , “FTP” , “FILE”等 -
用户名/密码可选 -
所需访问或下载文件的路径
URL的相貌我们已经铭记于心,而且对于 URL 各个子模块也有了基本的认识,可别小看这几个小模块,慢工出细活。我们拆分后仔细看看
-
URL拆分 -
理解URL个元素的含义

这里注意,dir 后面的文件名被省略了,这样的话服务器会使用默认的文件名,就反复咱们定义变量的时候,如果没有赋初值,通常会给默认值。同样的道理,服务器也会给一个默认的文件名,不同的服务器默认的文件会不一样,通常会是 Index.html。
这个就比较狠了,后面的”/”直接没有,那该访问啥呢?如果没有路径名,则代表访问根目录下面设置的默认文件。
这末尾的 whatisthis 是什么呢?在这种情况,如果服务器中存在 whatisthis 的文件,则按照文件处理。如果是 wahtsthis 为目录,则按照目录进行处理。
2 HTTP初探
通过第一步对URL的解析,知道了我们所访问的目标是什么,接下来是不是就要请求数据了呢?在做请求之前,我们一起回忆一下HTTP的基础知识


-
GET
-
POST
3 HTTP请求头——保命天子
看到这里,我相信大家应该了解了 HTTP 的大概样貌。万事儿都是有原则的,那么请求的也是有格式的,不听话就要被打屁屁。
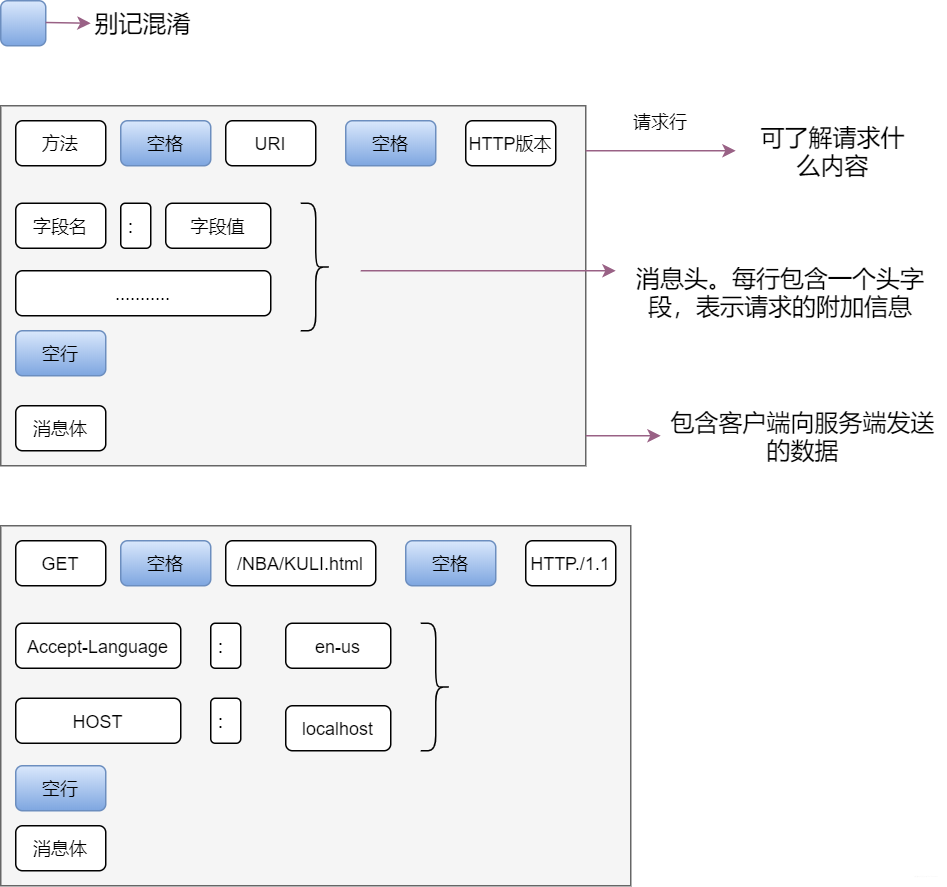

4 HTTP响应—–我行我素
响应的内容和请求信息的内容类似。只是响应中的第一行内容为状态码,表示执行结果是否成功。常见的HTTP状态码如下图所示
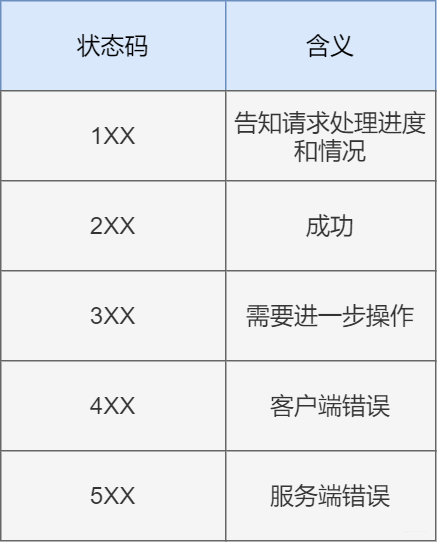
-
Get和Post哪些区别 -
请求头和响应头哪些位置是需要空格或者空行 -
常用响应状态码和请求方法
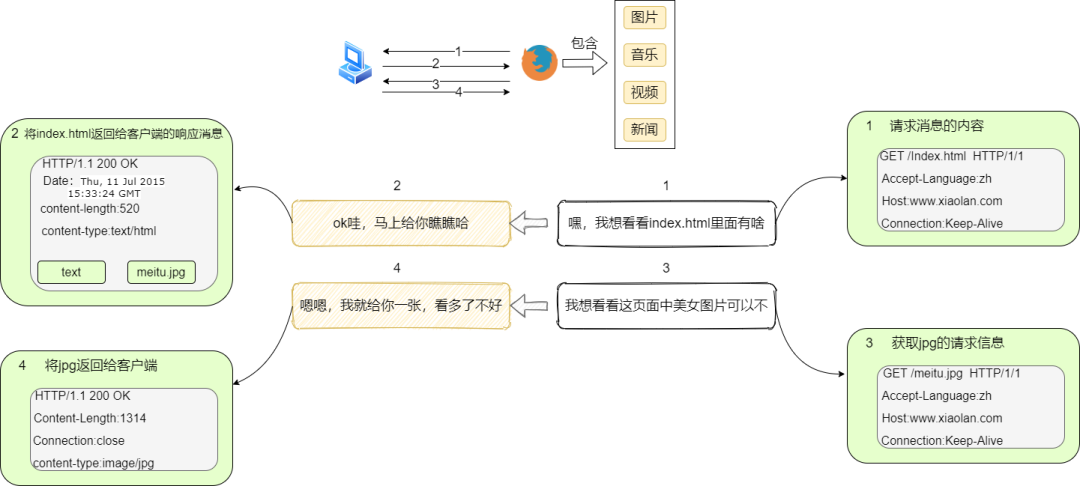
到此,我们从表面上知道,从敲入网址,构造请求消息,收到响应,并能将美女图片给呈现在眼前,这样就完事了?不好意思,我们时刻都有一颗的去大厂的心,意味着我们不能只知道表面现象还要适当去了解更多的细节。
5 刨根
虽然浏览器能够解析我们的网址,但是它并不具备将消息发送到网络中的能力,那是谁打的辅助?当然是操作系统大哥,为了让操作系统大哥帮忙,我们得先拜访下操作系统大哥,问问需要我们提供哪些资源,需要什么,我们就全力配合它。
-
IP地址
我们在浏览器输入的是网址,但是操作系统需要的是IP地址,所以我们需要想办法进行转换。转换的方法就需要请教 DNS 了。很简单,我们告诉DNS,”我的域名是www.xiaolan.com,请告诉我的 IP 地址”,OK,DNS服务器很爽快,回复”你的IP地址是xxx.xxx.xxx.xxx”。那么问题来了,我们是如何向 DNS 发送的这个查询呢?我们先来复习DNS

说了这么多,协议头部,到底有哪些字段,其含义是什么都还不知道,那怎么去分析报文,下面我们一起再看看报文什么样子
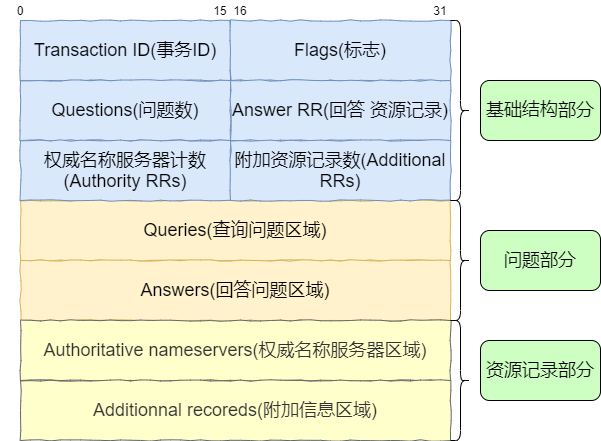
DNS报文基础部分为DNS首部。其中包含了事务ID,标志,问题计数,回答资源计数,回答计数,权威名称服务器计数和附加资源记录数。
-
事务ID:报文标识,用来区分 DNS 应答报文是对哪个请求进行响应 -
标志:DNS 报文中标志字段 -
问题计数:DNS 查询请求了多少次 -
回答资源记录数:DNS 响应了多少次 -
权威名称服务器计数: 权威名称服务器数目 -
附加资源记录数: 权威名称服务器对应 IP 地址的数目

-
QR(Response):查询请求,值为0;响应为1 -
Opcode:操作码。0表示标准查询;1表示反向查询;2服务器状态请求 -
AA(Authoritative):授权应答,该字段在响应报文中有效。通过0,1区分是否为权威服务器。如果值为 1 时,表示名称服务器是权威服务器;值为 0 时,表示不是权威服务器。 -
TC(Truncated):表示是否被截断。当值为1的时候时,说明响应超过了 512字节并已被截断,此时只返回前512个字节。 -
RD(Recursion Desired):期望递归。该字段能在一个查询中设置,并在响应中返回。该标志告诉名称服务器必须处理这个查询,这种方式被称为一个递归查询。如果该位为 0,且被请求的名称服务器没有一个授权回答,它将返回一个能解答该查询的其他名称服务器列表。这种方式被称为迭代查询。 -
RA(Recursion Available):可用递归。该字段只出现在响应报文中。当值为 1 时,表示服务器支持递归查询。 -
Z:保留字段,在所有的请求和应答报文中,它的值必须为 0。 -
rcode(Reply code):通过返回只判断相应的状态。
当值为0时,表示没有错误;当值为1时,表示报文格式错误(Format error),服务器不能理解请求的报文;当值为 2 时,表示域名服务器失败(Server failure),因为服务器的原因导致没办法处理这个请求;当值为 3 时,表示名字错误(Name Error),只有对授权域名解析服务器有意义,指出解析的域名不存在;当值为 4 时,表示查询类型不支持(Not Implemented),即域名服务器不支持查询类型;当值为 5 时,表示拒绝(Refused),一般是服务器由于设置的策略拒绝给出应答,如服务器不希望对某些请求者给出应答。
-
查询名:一般为查询的域名,也可能是通过IP地址进行反向查询 -
查询类型:查询请求的资源类型。常见的如果为A类型,表示通过域名获取IP。具体如下图所示

-
查询类:地址类型,通常为互联网地址为1
资源记录部分包含回答问题区域,权威名称服务器区域字段、附加信息区域字段,格式如下
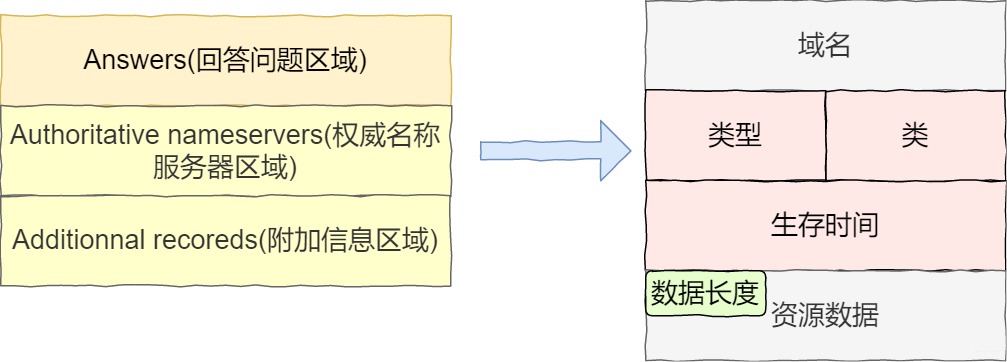
-
域名:所请求的域名 -
类型:与问题部分查询类型值一直 -
类:地址类型,和问题部分查询类值一样 -
生存时间:以秒为单位,表示资源记录的生命周期 -
资源数据长度:资源数据的长度 -
资源数据:按照查询要求返回的相关资源数据
知道了DNS大概是什么,它的域名结构和报文结构,是时候看看到底怎么解析的以及如何保证域名的解析比较稳定和可靠
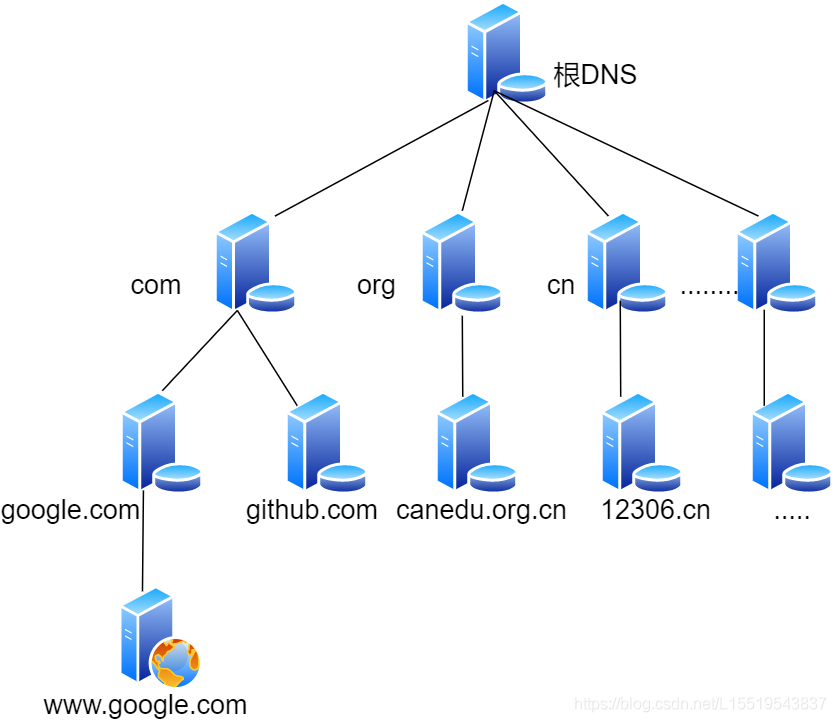
-
访问根域名服务器,这样我们就会知道”com”顶级域名的地址 -
访问”com”顶级域名服务器,可知道”google.com”域名服务器的地址 -
最后方位”google.com”域名服务器,就可知道”www.google.com”的IP地址

-
客户端发送一个 DNS 请求,请问 qq 你的IP的什么啊,同时会在本地域名服务器(一般是网络服务是临近机房)打声招呼 -
本地收到请求以后,服务器会有个域名与IP的映射表。如果存在,则会告诉你,如果想访问qq,那么你就访问XX地址。不存在则会去问上级(根域服务器):”老铁,你能告诉我 www.qq.com”的IP么 -
根 DNS 收到本地 DNS 请求后,发现是.com,”www.qq.com哟,这个由.com大哥管理,我马上给你它的顶级域名地址,你去问问它就好了” -
这个时候,本地 DNS 跑去问顶级域名服务器,”老哥,能告诉下www.qq.com”的ip地址码”,这些顶级域名负责二级域名比如qq.com -
顶级域名回复:”小本本记好,我给你 www.qq.com 区域的权威 DNS 服务器地址”,它会告诉你 -
本地DNS问权威DNS服务器:”兄弟,能不能告诉我 www.qq.com 对应IP是啥” -
权威DNS服务器查询后将响应的IP地址告诉了本地 DNS,本地服务器将 IP 地址返回给客户端,从而建立连接。
那如果我们写段cs程序都得这么麻烦的?不不,上面的是大佬们做好,我们只需要使用相关库就好了,这里就得说说Socket库了。


-
创建套接字阶段 -
管子连接到服务端套接字 -
收发数据 -
断开并删除套接字
那么再具体的实现中是怎样的呢?

-
最上面是网络应用程序,其中包含了浏览器,邮件客户端等,紧接着是Socket库,其中一个功能就是向 DNS服务器发出请求获取IP。 -
往下是操作系统大哥内脏,其中包含了协议栈。上面是传输层常见的TCP和UDP,分别负责 TCP 协议的收发数据和 UD P的首发数据。 -
往下是IP,控制网络数据包的收发操作。主要负责将网络数据包发送给通信对象。其中包含ICMP,ARP等协议。其中ICMP主要负责告知网络数据包在发送的过程中产生的错误信息,ARP负责根据IP地质查询MAC地质 -
再往下就是网卡驱动负责的硬件网卡了。直白点说是对网线的信号执行发送接收操作
-
描述符
connnet会将描述符告诉协议栈,协议栈知道描述符后就来判断到底使用哪个套接字去连接服务端
-
地址
这个IP地址即使刚才我们通过DNS获取的IP地址,并将IP地址告知协议栈
-
端口
IP地址是用来区分网络中各个计算机而分配的数值。可以理解为公安局的公用电话,我们打电话过去找某人还需要知道名字吧,不然打过去找谁?这个某某人就类似端口号,根据这个端口号我们能找到具体的联系人。所以通过IP+端口的方式确定具体的套接字。端口号那么多,到底指定多少端口?不慌,其实服务器上面使用的大部分端口都事先定义好了,比如HTTP多为80,SMPT通常为35端口。这样子就可以正儿八经的通信了
-
应用程序准备好需要发送的数据 -
构造HTTP请求信息 -
调用write委托协议栈发送数据
那连接的真正含义是什么?
-
连接意义之一是告知协议栈IP和端口
当创建完套接字以后,并没有存放任何的数据,自然也就不知道和谁说话。这个时候,如果应用程序要求发送数据,对于协议栈而言还是一脸懵逼。只有将IP和端口告知协议栈,他才会开始干活
-
连接意义二:
服务端创建套接字,但是不知道和谁通信。所以等待客户端告知”我是XX,我的IP是xxx,端口号是XXX”
-
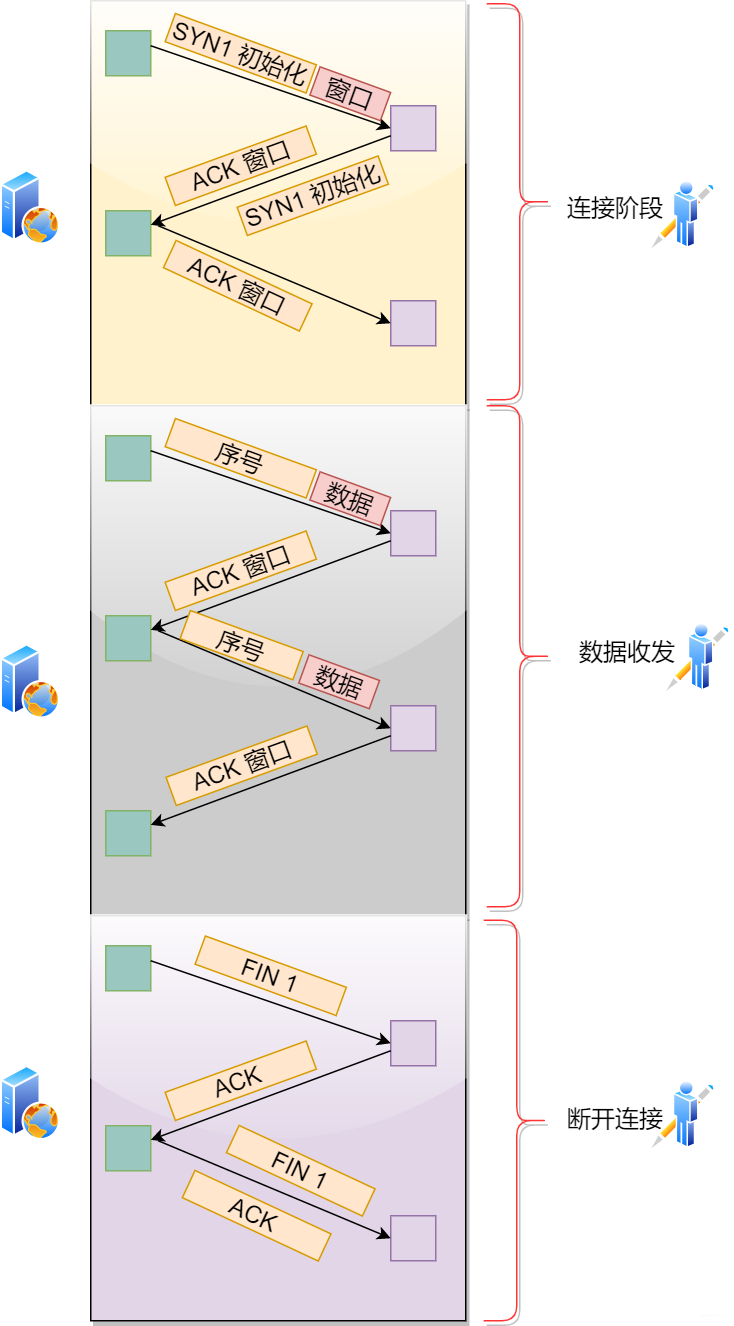
通过connect将IP地址和端口信息传递给协议栈的TCP模块,它会和服务端的TCP模块交换信息。具体交换哪些信息呢。客户端准确找到服务端以后,会将头部控制位中的SYN置为1。TCP 模块将信息传递给IP模块并委托它进行发送,服务端将接收到的IP模块传送给TCP模块 ,TCP模块根据控制信息找到端口号相同的套接字并将状态修改为正在连接。此时将会进行响应,响应的过程中将ACK控制位设置为1表示已经收到对应的网络包。TCP属于全双工通信,为了尽全力保证网络传输信息的不丢失,会进行双方确认机制。 -
此时网络包到达客户端,通过IP模块到达TCP模块,TCP模块通过头部信息确认连接服务器的这个操作是否成果。如果此时SYN为1则表示连接成功。然后将响应中的ACK设置1告诉服务器你的响应我收到了。这样连接操作完成。控制流程交给应用程序
6 应用阶段
当连接后到达应用程序后,此时将决定我们需要发送什么数据 ,怎么发数据,是按照流的方式还是逐字节发送,以及发什么内容,这样的多样性对于协议栈而言是不怎么关心的。对于协议栈,它不会是收到什么数据就马上发送,它会将数据先暂存缓冲区,如果收到数据就发送,难免会出现大量的小包,这样会让网络效率下降。那对于协议栈而言,到底一次满足多少才进行发送呢?
-
根据MTU判断
MTU是一个网络的最大长度,以太网中为1500字节,减去MTU的头部长度,所能容纳的最大数据长度为1460即MSS。这样就可避免出现大量的小包问题
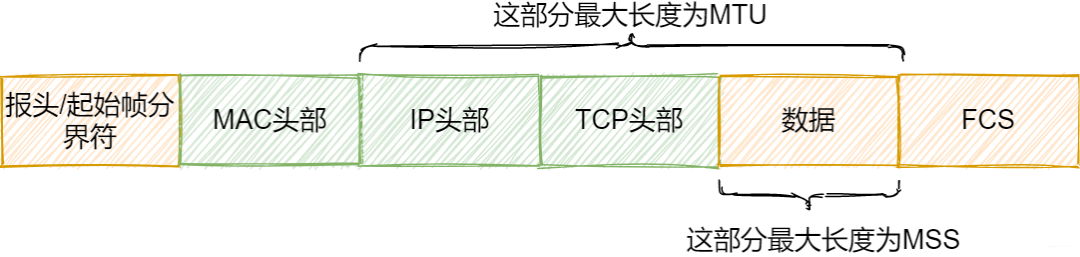
-
根据时间。
协议栈内部有个计时器,到达时间就将网络包发送出去。
如果HTTP请求消息太长了怎么办呢?
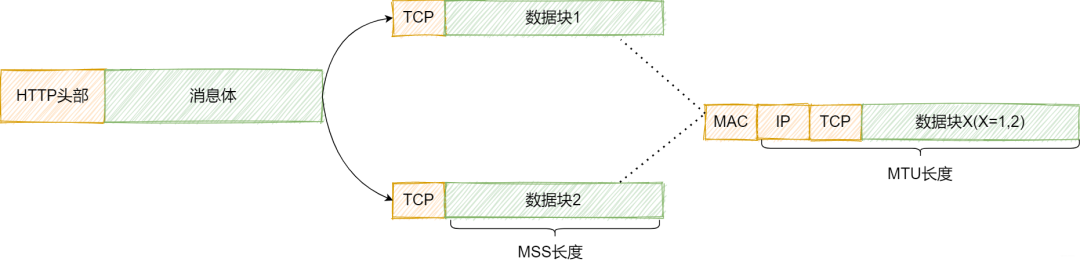
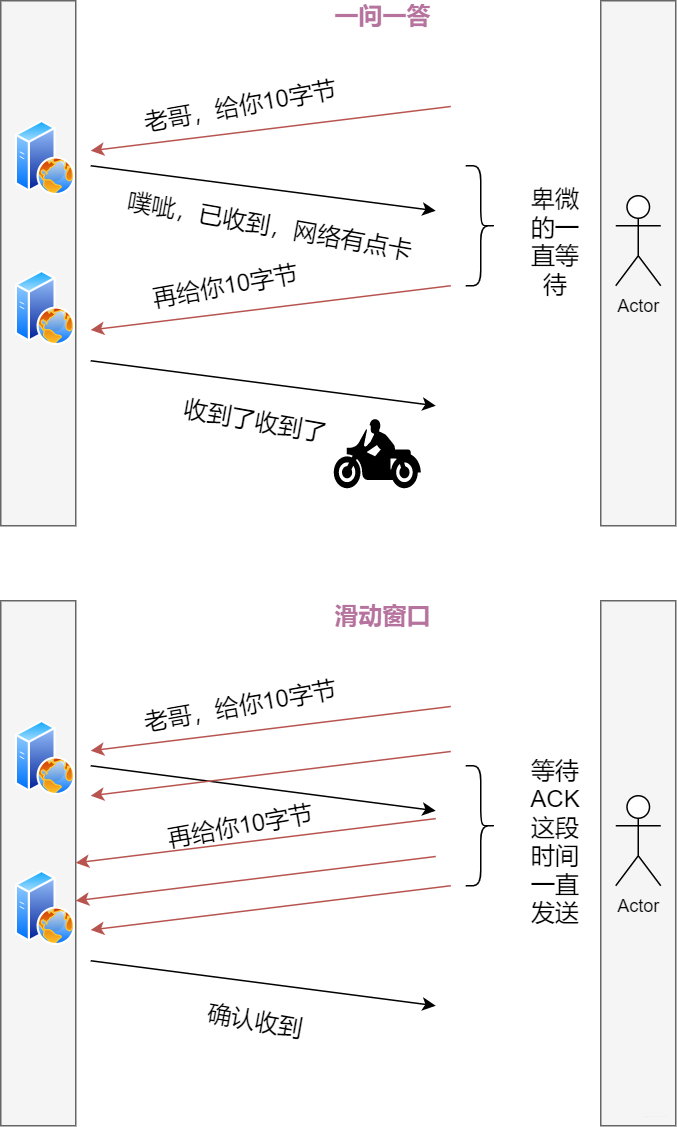
如果能发出数据,但是我们发了数据却不知道是否已经收到,或者中途有没有出现损失数据却不知情。所以,引入ACK的确认机制进行可靠的传输。
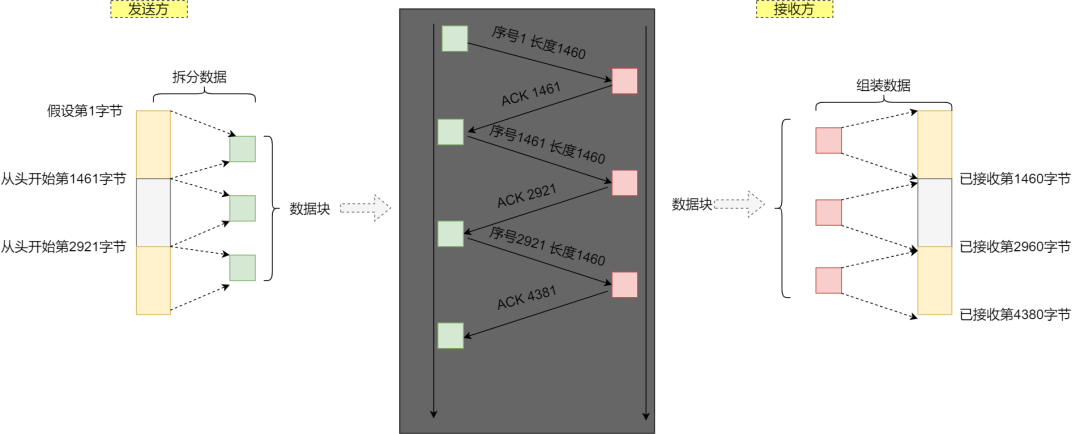
发送一个包后,不傻等ACK的返回,而是继续发送后续的包,这样就充分的利用这段空闲时间。但是这样也出现了一个问题,可能出现发送包的频率太快以致于接收方处理不过来出现堆积。
7 IP
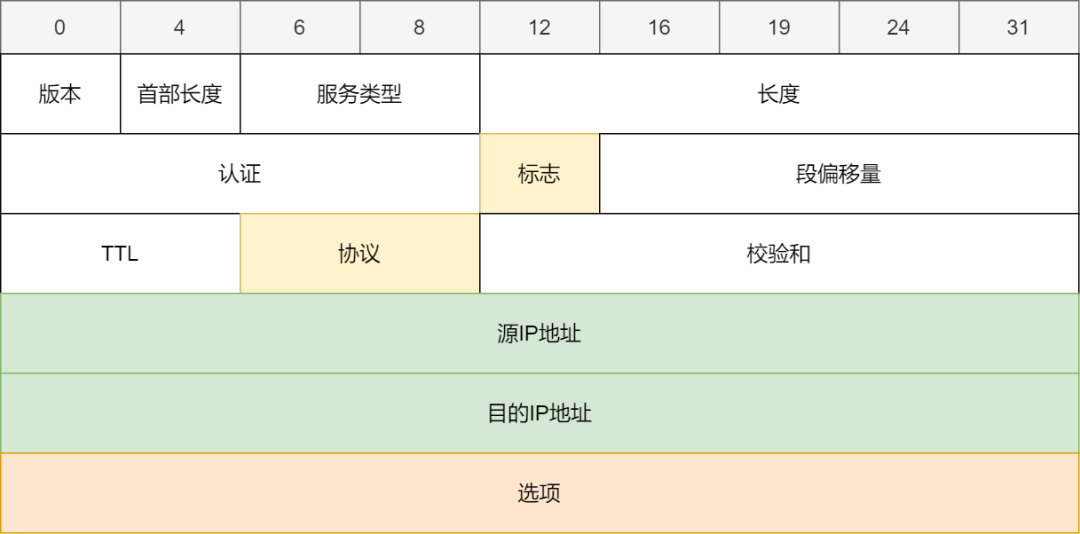
-
协议号:代表包从哪个模块来。如果是TCP模块则填写06,如果是UDP模块填写17。

-
以太网类型
以太网类型代表后面内容的类型,比如如果是IP地址相关则为0800
-
发送方MAC地址
MAC地址在网卡生产时就放入ROM中,取出存放于MAC头部即可。
-
接收方MAC地址
要知道接收方的MAC地址,又需要找帮手了(ARP),在局域网中大喊一声“xx这个IP地址是哪个?麻烦把你的MAC地址告诉我”,此时就有人给予回应”这是我的IP地址,我的MAC地址是XX”,但是我们不可能每次都一顿喊,所以就有杀手锏”ARP缓存”,一次询问后就会保存于缓存表中,下次再来如果能匹配到表就可直接获取MAC地址。
8 网卡
-
检查IP头部,保证格式正确 -
查看接收方IP,如果接收的IP地址与客户端发送过来IP一致则接受这个包,否则就很可能除了问题,此时IP模块会通过ICMP将错误告知发送方,ICMP包含了哪些错误提示呢,总结如下
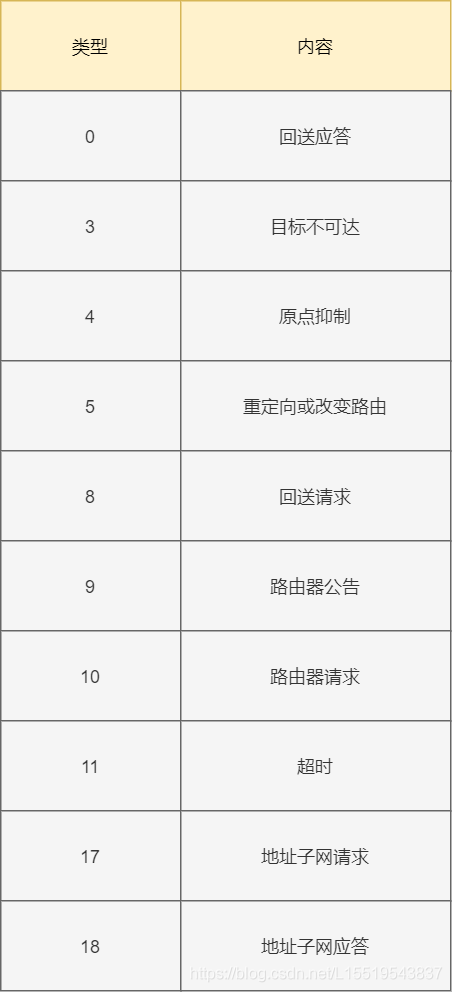
9 防火墙
看似一切到达服务器还比较顺利,顺利归顺利,但是我们的大部分项目中不得不考虑安全因素,不是什么数据包都可以随便进来,所以必须使用某种手段过滤掉一部分数据包,这就是防火墙
比如常见明文协议HTTP使用的80端口,我们可以通过设置IP+端口的方式限制其他数据包的通行。
比如在TCP三次握手的时候会交换或者更新ack syn等信息,我们则可以通过设置相应位置来达到我们过滤的目的
随着用户访问量的剧增,单台服务器明显感觉到了压力,再这样下去用户可能直接要干我,同事小A牛逼啊,上来就是:”上性能高一点的服务器啊”,小B也不赖:“多买几台服务器不就完事了?” 好,我们就听听小B的方案
砸钱
最初实现负载均衡采取的方案很直接,直接上硬件,当然也就比较贵,互联网的普及,和各位科学家的无私奉献,各个企业开始部署自己的方案,从而出现负载均衡服务器

-
简单,如果是java开发工程师,只需要servlet中几句代码即可
-
加大请求的工作量。第一次请求给负载均衡服务器,第二次请求给应用服务器 -
因为要先计算到应用服务器的IP地址,所以IP地址可能暴露在公网,既然暴露在了公网还有什么安全可言
了解计算机网络的你应该很清楚如何获取IP地址,其中比较常见的就是DNS解析获取IP地址。用户通过浏览器发起HTTP请求的时候,DNS通过对域名进行即系得到IP地址,用户委托协议栈的IP地址简历HTTP连接访问真正的服务器。这样不同的用户进行域名解析将会获取不同的IP地址从而实现负载均衡

乍一看,和HTTP重定向的方案不是很相似吗而且还有DNS解析这一步骤,也会解析出IP地址,不一样的暴露?每次都需要解析吗,当然不,通常本机就会有缓存,在实际的工程项目中通常是怎么样的呢
-
通过DNS解析获取负载均衡集群某台服务器的地址 -
负载均衡服务器再一次获取某台应用服务器,这样子就不会将应用服务器的IP地址暴露在官网了
这里典型的就是Nginx提供的反向代理和负载均衡功能。用户的请求直接叨叨反向代理服务器,服务器先看本地是缓存过,有直接返回,没有则发送给后台的应用服务器处理。
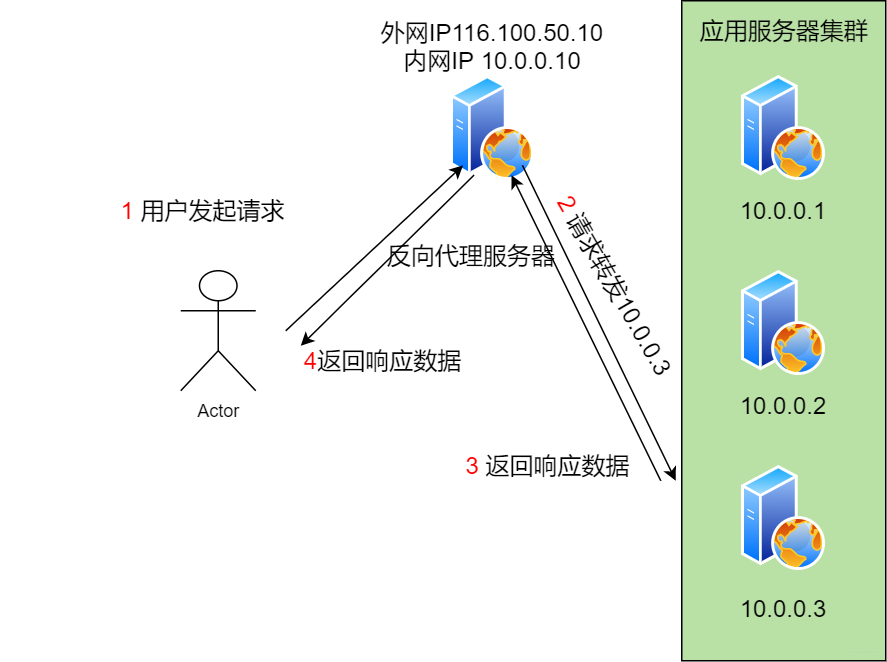
上面一种方案是基于应用层的,IP很明显是从网络层进行负载均衡。TCP./IP协议栈是需要上下层结合的方式达到目标,当请求到达网络层的时候。负载均衡服务器对数据包中的IP地址进行转换,从而发送给应用服务器

它可以解决因为数据量他打而导致负载均衡服务器带宽不足这个问题。怎么实现的呢。它不修改数据包的IP地址,而是更改mac地址。应用服务器和负载均衡服务器使用相同的虚拟IP

轮询是Nginx中默认的处理负载的方式,从方式名称应该可以猜出轮询即轮流的分配到后端的服务上。举个例子来说,假设目前后端有4台服务器,此时过来6个连接,如果采用轮询的方式,他就是这样工作A->1,B->2,C->3,D->4,A->5,B->6
server localhost:8081;
server localhost:8082;
server localhost:8083;
}server {
listen 80;
server_name www.xiaolan.com;
location /{
proxy_pass http://xxx;
}
}
因为客户端的ip地址是唯一不变的,所以,通过hash算法计算出ip地址对应的哈希码值,通过哈希码值对服务器的数量进行一个求模运算。这样就可以保证每个客户端访问的服务器都是保持不变的,因为hash算法的散列特点,也可以近似的当作平均分配。
ip_hash;
server localhost:8081;
server localhost:8082;
server localhost:8083;
}
server {
listen 80;
server_name www.xiaolan.com;
location /{
proxy_pass http://H_xx;
}
Hash算法中的散列特点,会导致某台服务器请求量过高,其他服务器请求却很少的情况。比如A服务器处理请求1000,而B服务器请求只有80,C服务器请求为20。我们希望后面的请求尽量来C服务器,所以出现了下面的方案
采用这种方式,Nginx会将请求发送给当前处理请求数量最少的服务器从而缓解集群的压力
leash_conn;
server localhost:8081;
server localhost:8082;
server localhost:8083;
}server {
listen 80;
server_name www.xiaolan.com;
location /{
proxy_pass http://XXX;
}
}
既然是将请求分给目前连接数最少的服务器,那好,我们看看这种情况。A服务器买的比较早,承受的并发数为200,B服务器稍微能承受的服务器并发数高一点500,C服务器能承受的并发数为1000。目前各个服务器情况如何呢?此时A服务器已经处理了199个连接,B服务器处理了499个连接,C服务器处理了500个连接,我们当然希望接下来的请求交给C服务器处理,不然对于AB而言岂不是压死了最后一根稻草,所以出现下面这种方式
通过设置权重的方式合理分配请求连接数
server localhost:8081 weight=6;
server localhost:8082 weight=2;
server localhost:8083 down;
}
server {
listen 80;
server_name www.xiaolan.com;
location /{
proxy_pass http://xxx;
}
}


0 条评论