对于问题“java中String类型的最大长度”,网上有各种说法,但都没有给出确切的依据。
且看源码。
java.lang.String.java
java String类以char[]数组存储字符元素,因而,String类的最大长度实际上取决于char[]数组能够包含的数组长度。
我们可以简单做下试验,看看char[]数组的最大长度MAX_LENGTH是多少。
当我们将len值调到320339961的时候,系统刚刚好报错,

因此,char[]数组的最大长度可以达到 320339960,约为2^28.255,每个字符占用空间1个字节,也就是2^28.255字节,而一个G等于2^30字节。
因而char[]数组的最大长度约等于(不到)1个G。
String类型的长度为320339960,其最大容量不超过1个G。
死锁的必要条件
- 互斥 至少有一个资源处于非共享状态
- 占有并等待
- 非抢占
- 循环等待
解决死锁,第一个是死锁预防,就是不让上面的四个条件同时成立。二是,合理分配资源。
三是使用银行家算法,如果该进程请求的资源操作系统剩余量可以满足,那么就分配。
进程间的通信方式
- 管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
- 有名管道 (named pipe) : 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
- 信号量( semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
- 共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
- 套接字( socket ) : 套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。
select和epoll的区别
1 select有最大并发数限制,默认最大文件句柄数1024,可修改。
epoll没有最大文件句柄数限制,仅受系统中进程能打开的最大文件句柄限制。
2 select效率低,每次都要线性扫描其维护的fd_set集合。
epoll只在集合不为空才轮训
3select存在内核空间和用户空间的内存拷贝问题。
epoll中减少内存拷贝,mmap将用户空间的一块地址和内核空间的一块地址同时映射到相同的一块物理内存地址
NIO使用的多路复用器是epoll
Epoll导致的selector空轮询
Java NIO Epoll 会导致 Selector 空轮询,最终导致 CPU 100%
官方声称在 JDK 1.6 版本的 update18 修复了该问题,但是直到 JDK 1.7 版本该问题仍旧存在,只不过该 BUG 发生概率降低了一些而已,它并没有得到根本性解决
Netty的解决方案:
对 Selector 的 select 操作周期进行统计,每完成一次空的 select 操作进行一次计数,若在某个周期内连续发生 N 次空轮询,则判断触发了 Epoll 死循环 Bug。
然后,Netty 重建 Selector 来解决。判断是否是其他线程发起的重建请求,若不是则将原 SocketChannel 从旧的 Selector 上取消注册,然后重新注册到新的 Selector 上,最后将原来的 Selector 关闭。
Https的SSL握手过程
Https协议由两部分组成:http+ssl,即在http协议的基础上增加了一层ssl的握手过程.
- 浏览器作为发起方,向网站发送一套浏览器自身支持的加密规则,比如客户端支持的加密算法,Hash算法,ssl版本,以及一个28字节的随机数client_random
- .网站选出一套加密算法和hash算法,生成一个服务端随机数server_random并以证书的形式返回给客户端浏览器,这个证书还包含网站地址、公钥public_key、证书的颁发机构CA以及证书过期时间。
- .浏览器解析证书是否有效,如果无效则浏览器弹出提示框告警。如果证书有效,则根据server_random生成一个preMaster_secret和Master_secret[会话密钥], master_secret 的生成需要 preMaster_key ,并需要 client_random 和 server_random 作为种子。浏览器向服务器发送经过public_key加密的preMaster_secret,以及对握手消息取hash值并使用master_secret进行加密发送给网站.[客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时也是前面发送的所有内容的hash值,用来供服务器校验]
- .服务器使用private_key 解密后得到preMaster_secret,再根据client_random 和 server_random 作为种子得到master_secret.然后使用master_secret解密握手消息并计算hash值,跟浏览器发送的hash值对比是否一致.
然后把握手消息通过master_secret进行对称加密后返回给浏览器.以及把握手消息进行hash且master_secret加密后发给浏览器.[服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时也是前面发送的所有内容的hash值,用来供客户端校验。] - .客户端同样可以使用master_secret进行解密得到握手消息.校验握手消息的hash值是否跟服务器发送过来的hash值一致,一致则握手结束.通信开始
- .以后的通信都是通过master_secret+对称加密算法的方式进行. 客户端与服务器进入加密通信,就完全是使用普通的HTTP协议,只不过用”会话密钥”加密内容。SSL握手过程中如果有任何错误,都会使加密连接断开,从而阻止了隐私信息的传输

非对称加密算法:RSA,DSA/DSS
对称加密算法:AES,RC4,3DES
HASH算法:MD5,SHA1,SHA256
spring事务的传播行为和隔离级别
spring事务七个事务传播行为
在TransactionDefinition接口中定义了七个事务传播行为:
- PROPAGATION_REQUIRED 如果存在一个事务,则支持当前事务。如果没有事务则开启一个新的事务。
- PROPAGATION_SUPPORTS 如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行。但是对于事务同步的事务管理器,PROPAGATION_SUPPORTS与不使用事务有少许不同。
- PROPAGATION_MANDATORY 如果已经存在一个事务,支持当前事务。如果没有一个活动的事务,则抛出异常。
- PROPAGATION_REQUIRES_NEW 总是开启一个新的事务。如果一个事务已经存在,则将这个存在的事务挂起。
- PROPAGATION_NOT_SUPPORTED 总是非事务地执行,并挂起任何存在的事务。
- PROPAGATION_NEVER 总是非事务地执行,如果存在一个活动事务,则抛出异常
- PROPAGATION_NESTED如果一个活动的事务存在,则运行在一个嵌套的事务中. 如果没有活动事务, 则按TransactionDefinition.PROPAGATION_REQUIRED 属性执行
Spring事务的五种隔离级别
在TransactionDefinition接口中定义了五个不同的事务隔离级别
- ISOLATION_DEFAULT 这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别.
另外四个与JDBC的隔离级别相对应 - ISOLATION_READ_UNCOMMITTED 这是事务最低的隔离级别,它充许别外一个事务可以看到这个事务未提交的数据。这种隔离级别会产生脏读,不可重复读和幻像读
- ISOLATION_READ_COMMITTED 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据。这种事务隔离级别可以避免脏读出现,但是可能会出现不可重复读和幻像读。
- ISOLATION_REPEATABLE_READ 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免下面的情况产生(不可重复读)。
- ISOLATION_SERIALIZABLE 这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。除了防止脏读,不可重复读外,还避免了幻像读。
springmvc如何解决循环依赖的问题
当使用构造器方式初始化一个bean,而且此时多个Bean之间有循环依赖的情况,spring容器就会抛出异常!
解决办法:初始化bean的时候(注意此时的bean必须是单例,否则不能提前暴露一个创建中的bean)使用set方法进行注入属性,此时bean对象会先执行构造器实例化,接着将实例化后的bean放入一个map中,并提供引用。当需要通过set方式设置bean的属性的时候,spring容器就会从map中取出被实例化的bean。比如A对象需要set注入B对象,那么从Map中取出B对象即可。以此类推,不会出现循环依赖的异常。
Btree索引和Hash索引的区别
Btree索引适合范围查找,Hash索引适合精确查找
数据库事务必须具备ACID特性
原子性:Atomic,所有的操作执行成功,才算整个事务成功
一致性:Consistency,不管事务success或fail,不能破坏关系数据的完整性以及业务逻辑上的一致性
隔离性:Isolation,每个事务拥有独立数据空间,多个事务的数据修改相互隔离。事务查看数据更新时,数据要么是另一个事务修改前的状态,要么是修改后状态,不应该查看到中间状态数据。
持久性:Durability,事务执行成功,数据必须永久保存。重启DB,数据需要恢复到事务执行成功后的状态。
原子性、一致性、持久性DBMS通过日志来实现。
隔离性DBMS通过锁来实现
聚簇索引和非聚簇索引的区别
聚簇索引,就是指主索引文件和数据文件为同一份文件,聚簇索引主要用在Innodb存储引擎中。如主键。B+Tree的叶子节点上的data就是数据本身。
非聚簇索引就是指B+Tree的叶子节点上的data,并不是数据本身,而是数据存放的地址
Zookeeper和Eureka的区别
答:ZK保证Cp,即一致性,分区容错性,比如当master节点因为网络故障和其他节点失去联系的时候,剩余节点会重新进行Master选举。问题在于Master选举的时间太长30~210s,选举期间整个zk集群是不可用的,这就导致选举期间的注册服务瘫痪。
Eureka保证Ap,高可用性,它没有所谓主从节点概念,各节点平等。某节点挂掉不影响其他节点功能,其他节点照样提供查询和注册功能。Eureka客户端发现Eureka节点挂掉直接切换到其他正常的节点上去。只不过可能查到的数据不是最新的,也就是Eureka不保证数据的强一致性。
作为注册中心,推荐Eureka,因为注册服务更重要的是可用性
可以作为GC Roots的对象包括哪些
虚拟机栈(栈帧中的局部变量表)中引用的变量
方法区中类静态属性引用的对象
方法区中常量引用的对象
本地方法栈中JNI引用的变量
JVM运行时内存模型
方法区、堆、虚拟机栈、本地方法栈、程序计数器
Netty的ByteBuffer的引用计数器机制
从netty的4.x版本开始,netty使用引用计数机制进行部分对象的管理,通过该机制netty可以很好的实现自己的共享资源池。
如果应用需要一个资源,可以从netty自己的共享资源池中获取,新获取的资源对象的引用计数被初始化为1,可以通过资源对象的retain方法增加引用计数,当引用计数为0的时候该资源对象拥有的资源将会被回收。
判断对象是否存活的两种方法
1 引用计数法:缺点是对循环引用的对象无法回收
2 可达性分析
Java对象的初始化过程
类加载双亲委派模型
从上到下分三个类加载器:
BootStrap classloader:启动类加载器,负责将Java_HOME/lib下的类库加载到虚拟机内存中,比如rt.jar
Extension classloader:扩展类加载器,负责将JAVA_HOME/lib/ext下的类库加载到虚拟机内存中。
Application classloader:应用程序类加载器,负责加载classpath环境变量下指定的类库。如果程序中没有自定义过类加载器,那么这个就是程序中默认的类加载器。
双亲委派模型:
如果一个类加载器收到类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器完成。每个类加载器都是如此,只有当父加载器在自己的搜索范围内找不到指定的类时(即ClassNotFoundException),子加载器才会尝试自己去加载。
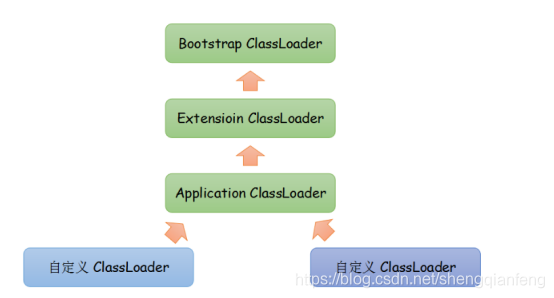
防止自定义的一些跟jdk标准库中冲突的全限定名的类被加载,导致标准库函数不可用。
Executors框架的四种线程池及拒绝策略
四种线程池
ExecutorService executorService =
固定大小线程池
Executors.newFixedThreadPool(60);
设置固定值会造成高并发线程排队等待空闲线程,尤其是当读取大数据量时线程处理时间长而不释放线程,导致无法创建新线程。
可缓存线程池
Executors.newCachedThreadPool();
线程池无限大,而系统资源(内存等)有限,会导致机器内存溢出OOM。
定长且可定时、周期线程池
Executors.newScheduledThreadPool(5);
单线程线程池
Executors.newSingledThreadPool();
1 /* 自定义线程池。
2 * 构造参数:
3 * public ThreadPoolExecutor(
4 * int corePoolSize,--当前线程池核心线程数
5 * int maximumPoolSize,--当前线程池最大线程数
6 * long keepAliveTime,--保持活着的空间时间
7 * TimeUnit unit,--时间单位
8 * BlockingQueue<Runnable> workQueue,--排队等待的自定义队列
9 * ThreadFactoty threadFactory,
10 * RejectedExecutionHandler handler--队列满以后,其他任务被拒绝执行的方法
11 * ){.........}
在使用有界队列时,若有新的任务需要执行,
- 若线程池实际线程数小于corePoolSize,则优先创建线程,
- 若大于corePoolSize,则会将任务加入队列,
- 若队列已满,则在总线程数不大于maximumPoolSize的前提下,创建新的线程,
- 若线程数大于maximumPoolSize,则执行拒绝策略。或其他自定义方式。
JDK拒绝策略
- AbortPolicy:默认,直接抛出异常,系统正常工作。
- DiscardOldestPolicy:丢弃最老的一个请求,尝试再次提交当前任务。
- CallerRunsPolicy:只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务。用线程池中的线程执行,而是交给调用方来执行, 如果添加到线程池失败,那么主线程会自己去执行该任务,不会等待线程池中的线程去执行
new ThreadPoolExecutor(
2, 3, 30, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
new RecorderThreadFactory("CookieRecorderPool"),
new ThreadPoolExecutor.CallerRunsPolicy());
- DiscardPolicy:丢弃无法处理的任务,不给予任何处理。
- 自定义拒绝策略
如果需要自定义策略,可以实现RejectedExecutionHandler接口。
参考:https://www.cnblogs.com/duanxz/p/3696849.html
Reactor单线程模型
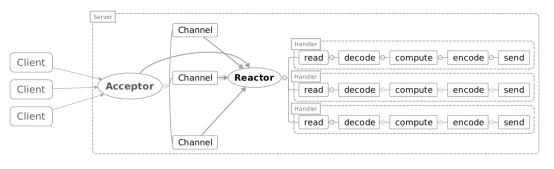
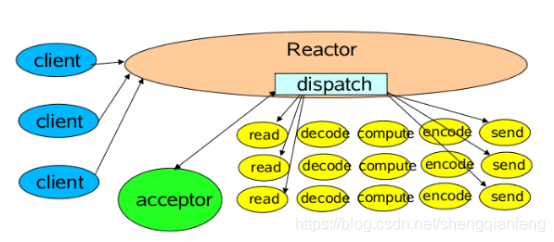
一个Acceptor线程,监听Accept事件,负责接收客户端的连接SocketChannel,SocketChannel注册到Selector上并关心可读可写事件。
一个Reactor线程,负责轮训selector,将selector注册的就绪事件的key读取出来,拿出attach任务Handler根据事件类型分别去执行读写等。
单线程模型的瓶颈:
比如:拿一个客户端来说,进行多次请求,如果Handler中数据读出来后处理的速度比较慢(非IO操作:解码-计算-编码-返回)会造成客户端的请求被积压,导致响应变慢!
所以引入Reactor多线程模型!
Reactor多线程模型
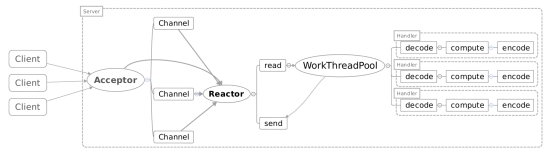
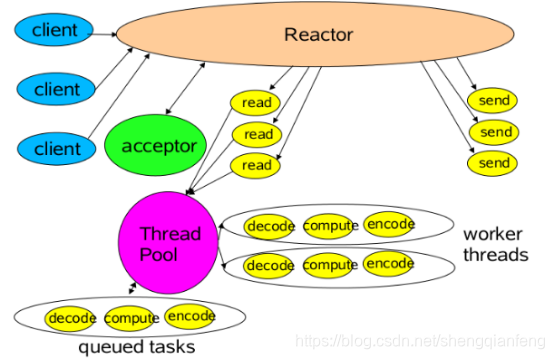
Reactor多线程就是把Handler中的IO操作,非IO操作分开。
操作IO的线程称为IO线程,操作非IO的线程叫做工作线程。
客户端的请求(IO操作:读取出来的数据)可以直接放进工作线程池(非IO操作:解码-计算-编码-返回)中,这样异步处理,客户端发送的请求就得到返回了不会一直阻塞在Handler中。
但是当用户进一步增加的时候,Reactor线程又会出现瓶颈,因为Reactor中既有IO操作,又要响应连接请求。为了分担Reactor的负担,所以引入了主从Reactor模型!
主从Reactor模型
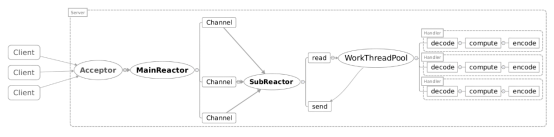
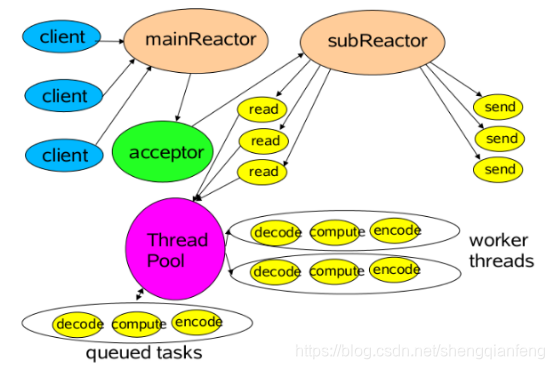
主Reactor用于响应连接请求,从Reactor用于处理IO操作请求!
特点是:服务端用于接收客户端连接的不再是1个单独的NIO线程(Acceptor线程),而是一个独立的NIO线程池。
Acceptor线程池接收到客户端TCP连接请求处理完成后(可能包含接入认证等),将新创建的SocketChannel注册到I/O线程池(sub reactor线程池)的某个I/O线程上,由它负责SocketChannel的读写和编解码工作。
Acceptor线程池只用于客户端的登录、握手和安全认证,一旦链路建立成功,就将链路注册到后端subReactor线程池的I/O线程上,有I/O线程负责后续的I/O操作。
第三种模型比起第二种模型,是将Reactor分成两部分,mainReactor负责监听server socket,accept新连接,并将建立的socket分派给subReactor。subReactor负责多路分离已连接的socket,读写网 络数据,对业务处理功能,其扔给worker线程池完成。通常,subReactor个数上可与CPU个数等同。
0 条评论