APM 程序性能监控

什么是APM?
Application Performance Monitoring
中文直译:应用程序性能监控,是对企业的应用系统进行实时监控,它是用于实现对应用程序性能管理和故障管理的系统化的解决方案
一般地包括内容有应用控制、链路追踪、故障排查
各大厂商的调用链追踪工具
市面上常见的或者说调用链追踪工具有?
Dapper(Google) : 各 tracer 的基础 未开源
StackDriver Trace (Google)
Zipkin(twitter)
Appdash(golang)
鹰眼(taobao) 未开源
谛听(盘古,阿里云云产品使用的Trace系统)
云图(蚂蚁Trace系统)
sTrace(神马)
X-ray(aws)
CAT(大众点评)
skywalking (华为)开源
ES APM (Elastic)开源
Naver Pinpoint
Uber-jaeger
方案对比
| pinpoint | zipkin | jaeger | skywalking | Elastic APM | |
|---|---|---|---|---|---|
| OpenTracing兼容 | 否 | 是 | 是 | 是 | 是 |
| 客户端支持语言 | java、php | java,c#,go,php等 | java,c#,go,php等 | Java, .NET Core, NodeJS and PHP | Java,.NET,GO,Nodejs,python,ruby,javascript |
| 存储 | hbase | ES,mysql,Cassandra,内存 | ES,kafka,Cassandra,内存 | ES,H2,mysql,TIDB,sharding sphere | ES |
| 传输协议支持 | thrift | http,MQ | udp/http | gRPC | http |
| ui丰富程度 | 高 | 低 | 中 | 中 | 中 |
| 实现方式-代码侵入性 | 字节码注入,无侵入 | 拦截请求,侵入 | 拦截请求,侵入 | 字节码注入,无侵入 | 字节码注入,无侵入 |
| 扩展性 | 低 | 高 | 高 | 中 | 高 |
| trace查询 | 不支持 | 支持 | 支持 | 支持 | 支持 |
| 告警支持 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| jvm监控 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| 性能损失 | 高 | 中 | 中 | 低 | 低 |
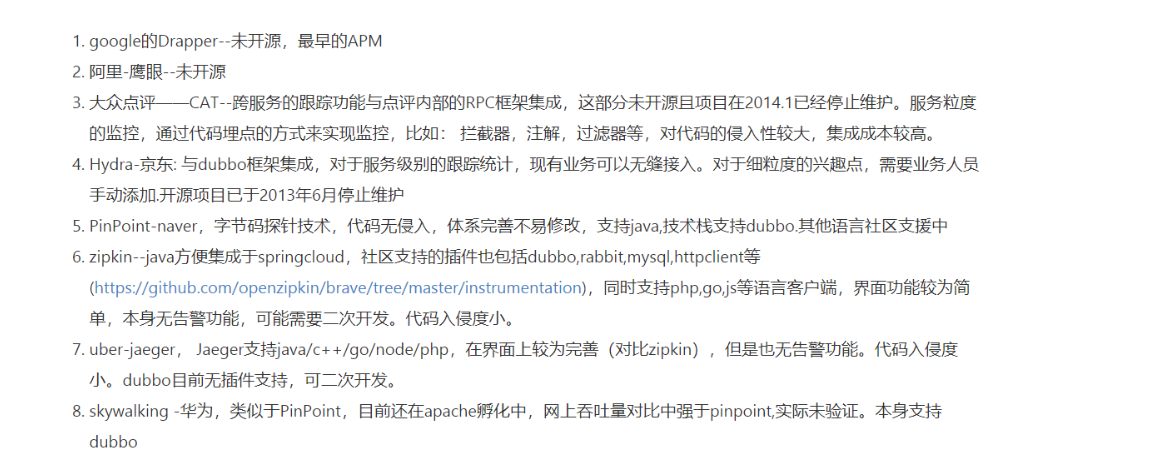
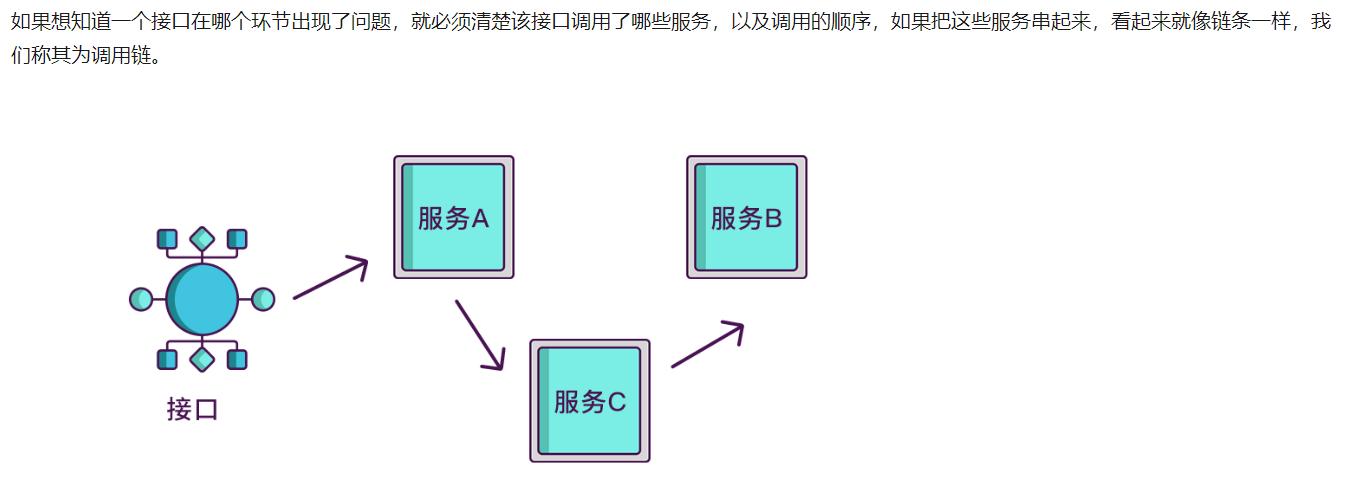
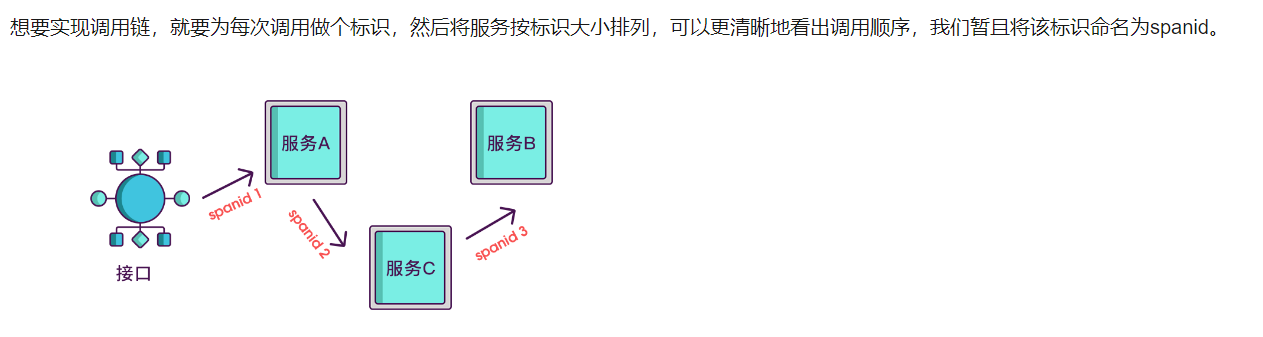
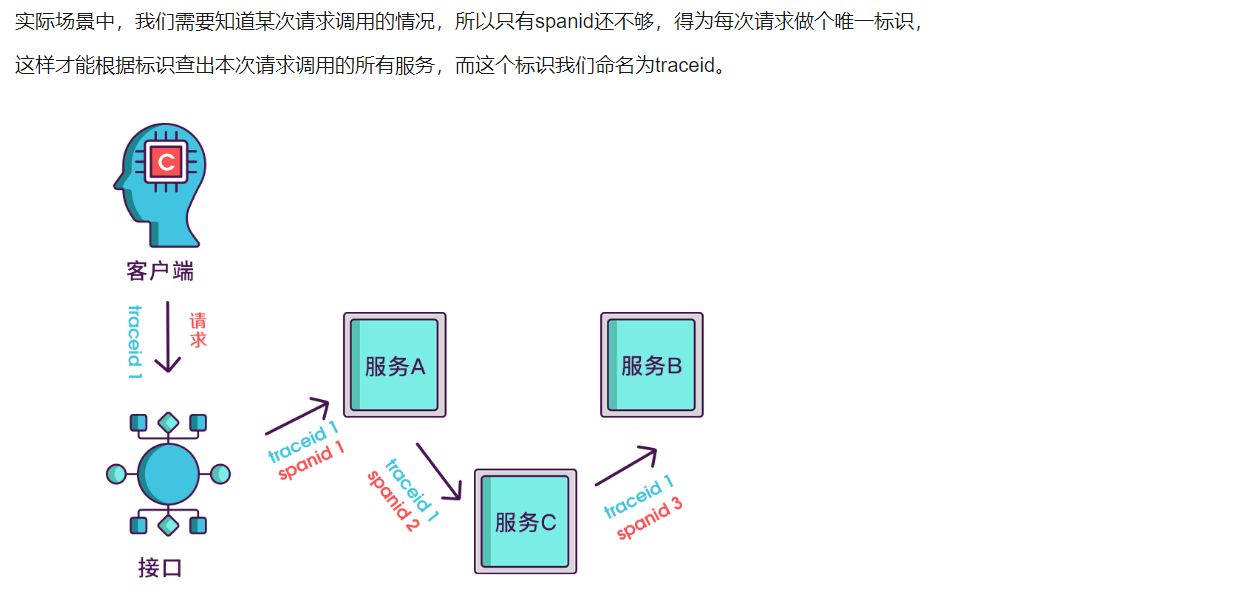
分布式追踪链基本实现原理
1,
2,
3,
4,
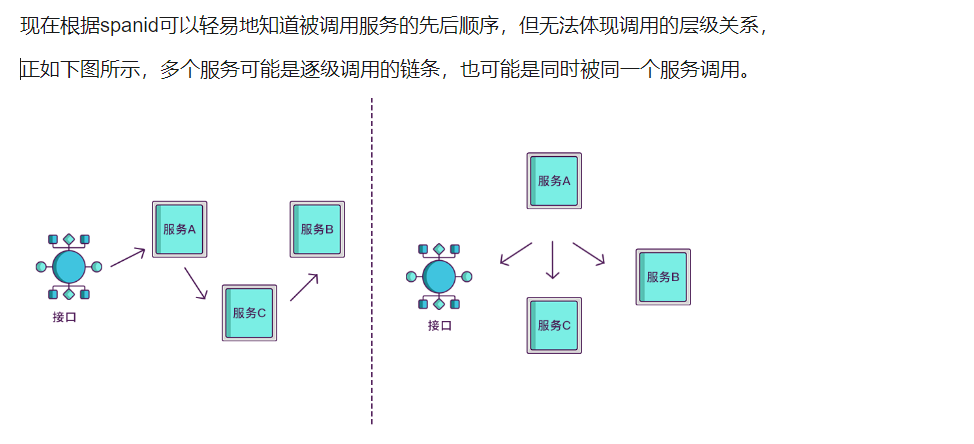
5,
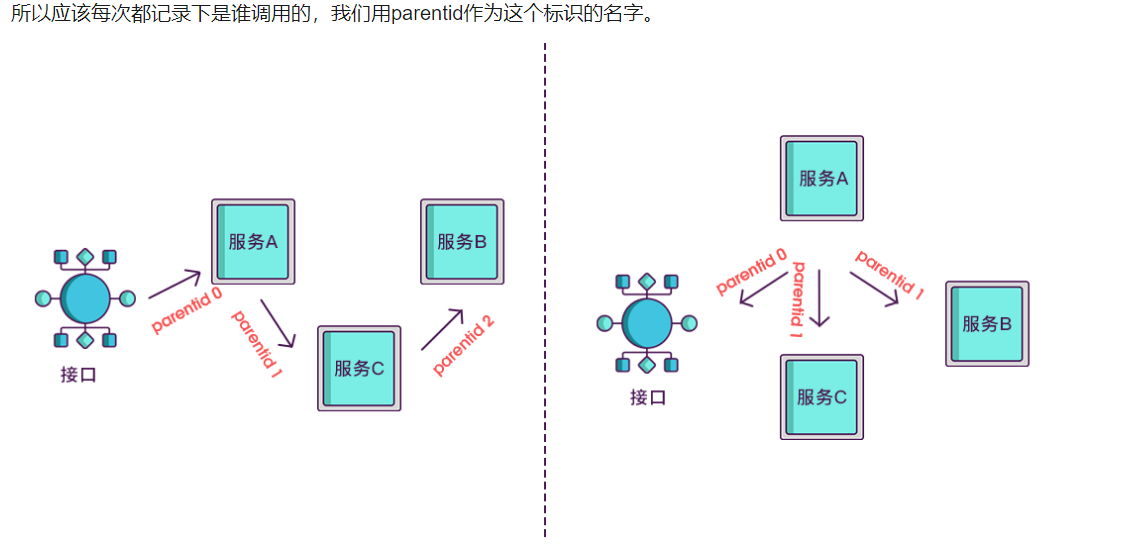
6,
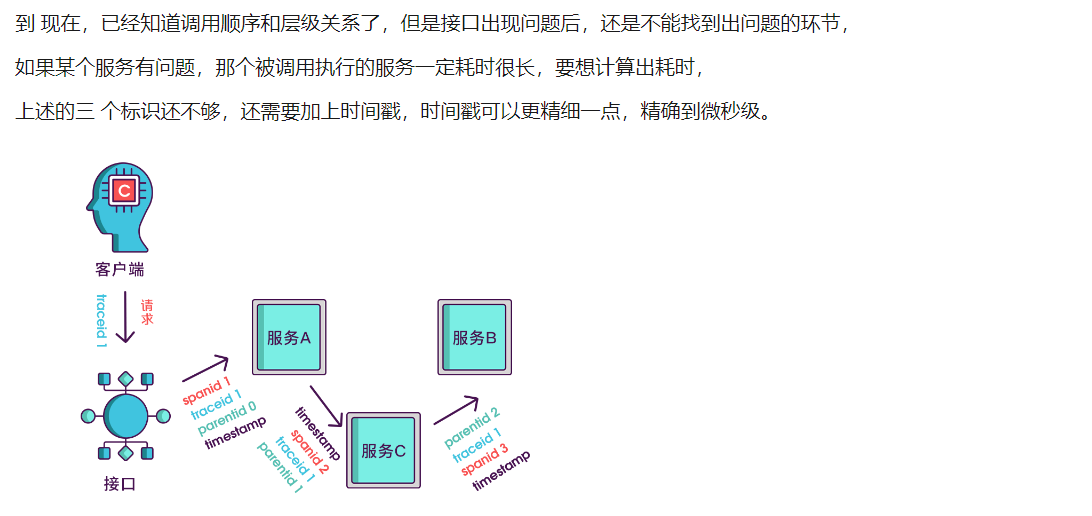
7,
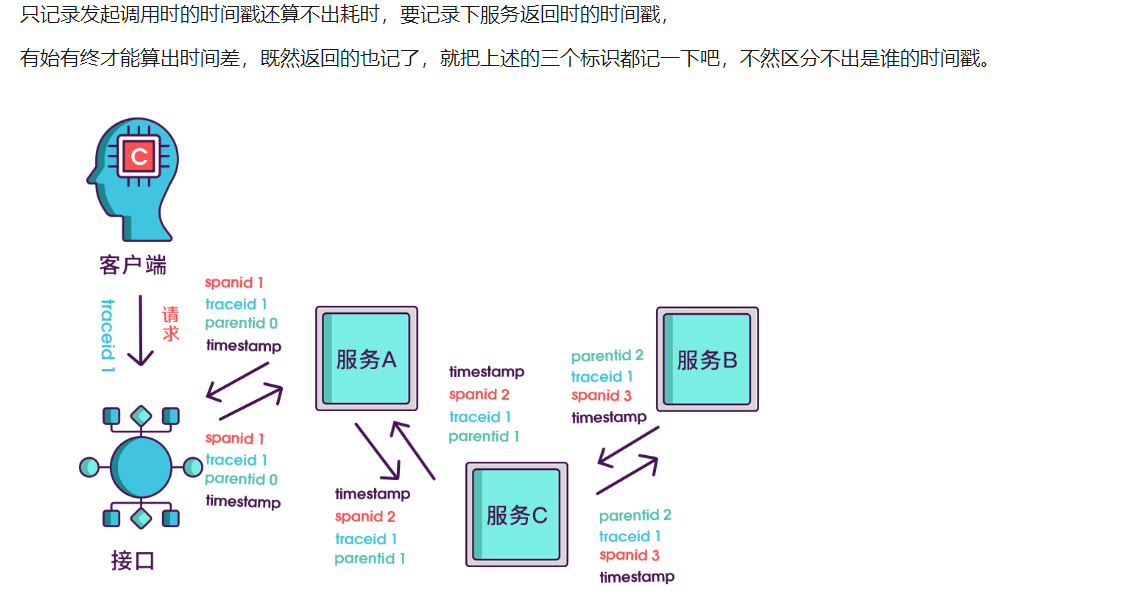
8,

9,

10,
其实span块内除了记录这几个参数之外,还可以记录一些其他信息,
比如发起调用服务名称、被调服务名称、返回结果、IP、调用服务的名称等,
最后,我们再把相同spanid的信息合成一个大的span块,就完成了一个完整的调用链
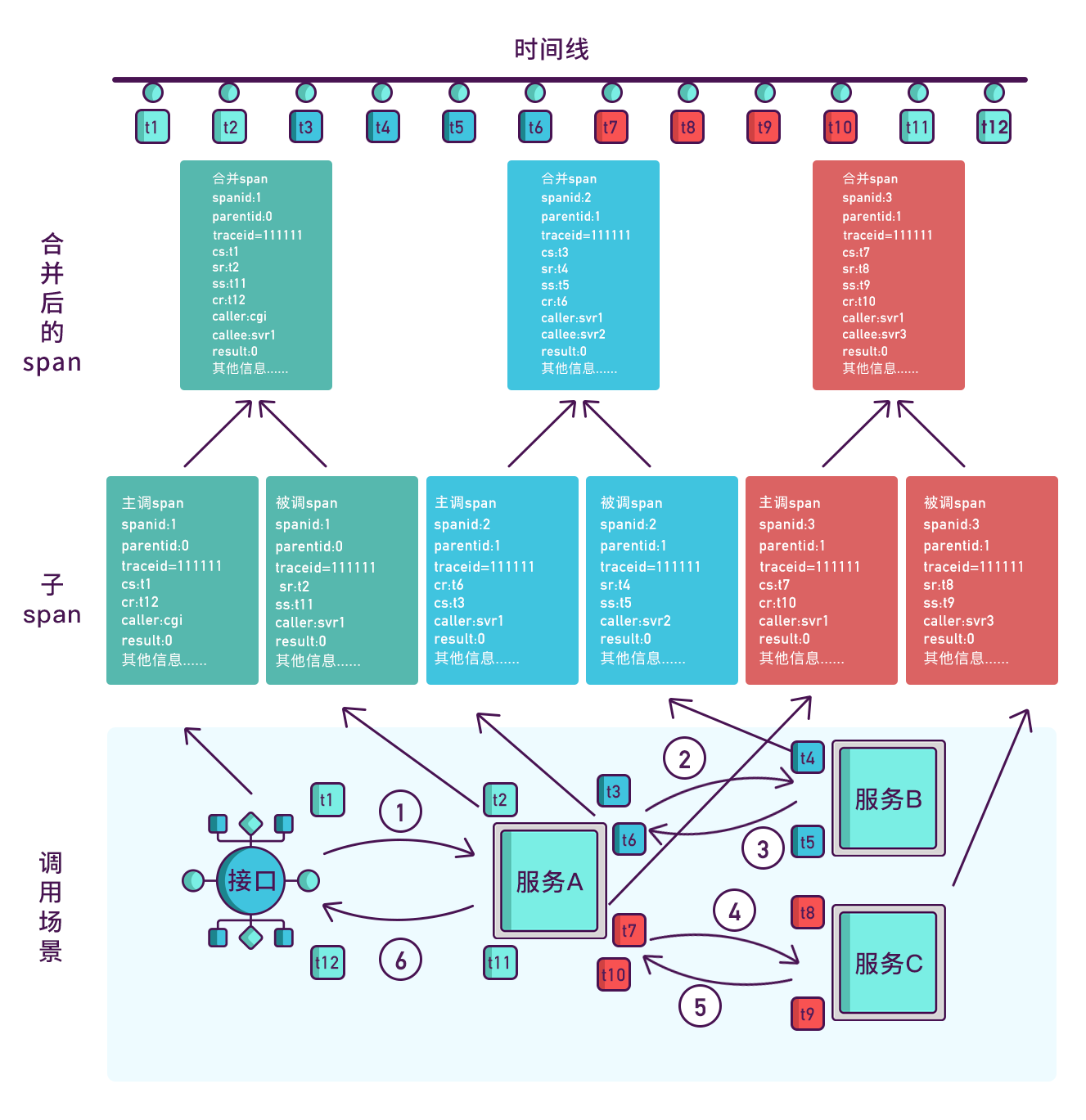
openTrancing数据模型



选用 Skywalking 、Elastic APM
1,基础设施
ElasticSearch (ES) kibana(数据分析展示UI)
目前使用的版本
- elasticsearch-7.5.1
- kibana-7.5.1
elasticsearch安装与使用
https://linpxing.cn/elk-evn-build/
kibana安装与使用
https://linpxing.cn/elk-install-kibana-7-5-1/
Skywalking
文档帮助:skywalking doc
版本:apache-skywalking-apm-es7-6.6.0 (支持集群部署)
安装:
注意 config目录为 agent的配置文件目录

一般要关注的文件为 log4j2.xml (日志) application.yml(skywalking 代理配置)
修改存储使用es7,ip端口号为可更改
xxxxxxxxxxcluster: standalone:core: default: # Mixed: Receive agent data, Level 1 aggregate, Level 2 aggregate # Receiver: Receive agent data, Level 1 aggregate # Aggregator: Level 2 aggregate role: ${SW_CORE_ROLE:Mixed} # Mixed/Receiver/Aggregator restHost: ${SW_CORE_REST_HOST:0.0.0.0} restPort: ${SW_CORE_REST_PORT:12800} restContextPath: ${SW_CORE_REST_CONTEXT_PATH:/} gRPCHost: ${SW_CORE_GRPC_HOST:0.0.0.0} gRPCPort: ${SW_CORE_GRPC_PORT:11800} downsampling: - Hour - Day - Month # Set a timeout on metrics data. After the timeout has expired, the metrics data will automatically be deleted. enableDataKeeperExecutor: ${SW_CORE_ENABLE_DATA_KEEPER_EXECUTOR:true} # Turn it off then automatically metrics data delete will be close. dataKeeperExecutePeriod: ${SW_CORE_DATA_KEEPER_EXECUTE_PERIOD:5} # How often the data keeper executor runs periodically, unit is minute recordDataTTL: ${SW_CORE_RECORD_DATA_TTL:90} # Unit is minute minuteMetricsDataTTL: ${SW_CORE_MINUTE_METRIC_DATA_TTL:90} # Unit is minute hourMetricsDataTTL: ${SW_CORE_HOUR_METRIC_DATA_TTL:36} # Unit is hour dayMetricsDataTTL: ${SW_CORE_DAY_METRIC_DATA_TTL:45} # Unit is day monthMetricsDataTTL: ${SW_CORE_MONTH_METRIC_DATA_TTL:18} # Unit is month # Cache metric data for 1 minute to reduce database queries, and if the OAP cluster changes within that minute, # the metrics may not be accurate within that minute. enableDatabaseSession: ${SW_CORE_ENABLE_DATABASE_SESSION:true} topNReportPeriod: ${SW_CORE_TOPN_REPORT_PERIOD:10} # top_n record worker report cycle, unit is minute storage: elasticsearch7: nameSpace: ${SW_NAMESPACE:"82-test-sw"} clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:192.168.9.93:9200} protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"} trustStorePath: ${SW_SW_STORAGE_ES_SSL_JKS_PATH:"../es_keystore.jks"} trustStorePass: ${SW_SW_STORAGE_ES_SSL_JKS_PASS:""}# user: ${SW_ES_USER:""}# password: ${SW_ES_PASSWORD:""} indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:2} indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:0}# # Those data TTL settings will override the same settings in core module. recordDataTTL: ${SW_STORAGE_ES_RECORD_DATA_TTL:7} # Unit is day otherMetricsDataTTL: ${SW_STORAGE_ES_OTHER_METRIC_DATA_TTL:45} # Unit is day monthMetricsDataTTL: ${SW_STORAGE_ES_MONTH_METRIC_DATA_TTL:18} # Unit is month
代理配置
1,准备代码的jar
下载skywalking安装包的时候,安装包里会带着agent部分
解压后的文件目录如下
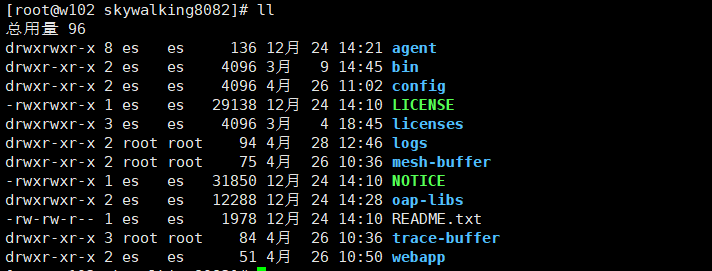
cd agent #目录如下
以下为支持的插件
集成的钩子

config/agent.conf
xxxxxxxxxx# The agent namespaceagent.namespace=${SW_AGENT_NAMESPACE:bee-8001-namespace}# The service name in UIagent.service_name=${SW_AGENT_NAME:8001-bee-82}# Backend service addresses.collector.backend_service=${SW_AGENT_COLLECTOR_BACKEND_SERVICES:192.168.9.93:11800}# Logging file_namelogging.file_name=${SW_LOGGING_FILE_NAME:skywalking-api.log}# Logging levellogging.level=${SW_LOGGING_LEVEL:DEBUG}# Logging dir# logging.dir=${SW_LOGGING_DIR:""}# Logging max_file_size, default: 300 * 1024 * 1024 = 314572800# logging.max_file_size=${SW_LOGGING_MAX_FILE_SIZE:314572800}# The max history log files. When rollover happened, if log files exceed this number,# then the oldest file will be delete. Negative or zero means off, by default.# logging.max_history_files=${SW_LOGGING_MAX_HISTORY_FILES:-1}# mysql plugin configuration# plugin.mysql.trace_sql_parameters=${SW_MYSQL_TRACE_SQL_PARAMETERS:false}
skywalking-agent.jar 为tomcat或者要监控的应用要使用的jar包 如果是监控别的平台,则会对应的语言的类库
logs: 为日志存放目录
一般会将agent copy到要用的服务器的目录直接进行引用
2,修改 tomcat-x/bin/catalina.sh
xxxxxxxxxx## 增加一行 CATALINA_OPTS="$CATALINA_OPTS -javaagent:/app/soft/skywalking8001/agent/skywalking-agent.jar"; export CATALINA_OPTS
3,启动应用
4,查看数据是否正常流通
5,可能会遇到的问题
xxxxxxxxxxValidation Failed: 1: this action would add [2] total shards, but this cluster currently has [1001]/[1000] maximum shards open因为单机的es的索引个数为 1000,超过了不允许再创建索引,所以修改索引个数,同时也说明 skywalking要创建的索引个数超多,简单估计超过 500个!解决方法PUT /_cluster/settings{ "transient": { "cluster": { "max_shards_per_node":10000 } }
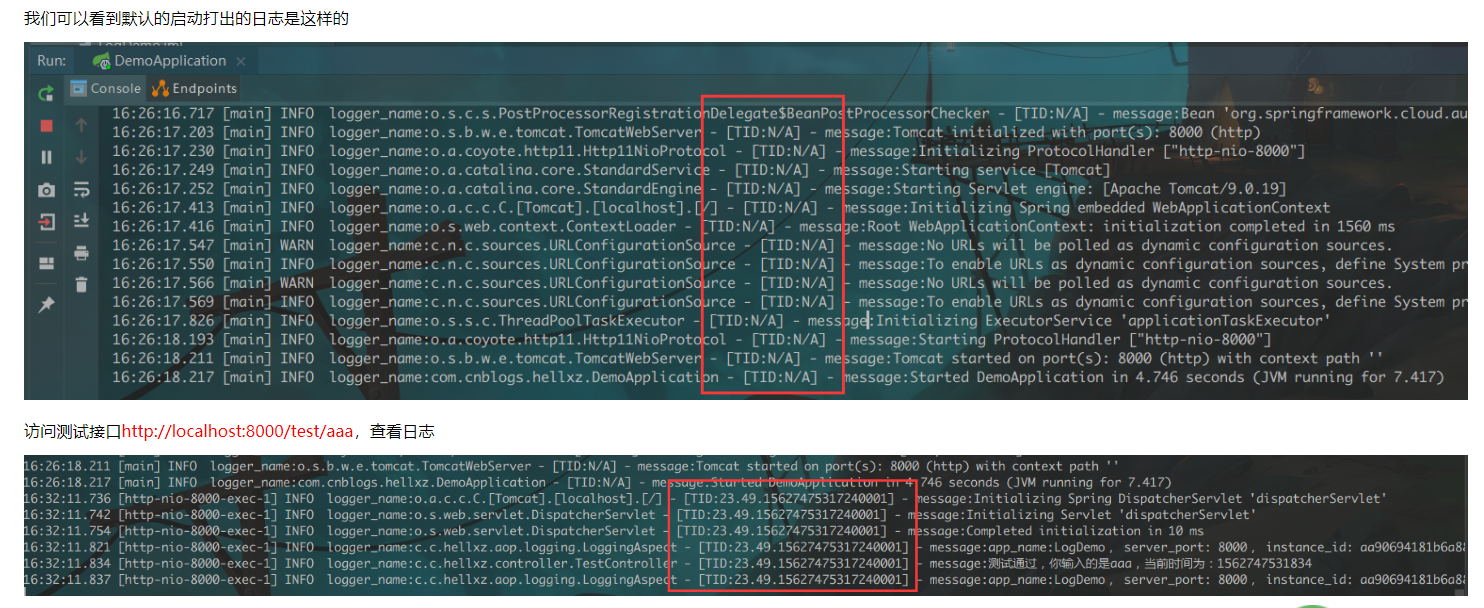
Skywalking UI相关页面的截图


skywalking log4j plugin:
ES APM
版本:apm-server-7.6.1
安装使用:
get start doc: https://www.elastic.co/guide/en/apm/get-started/7.5/index.html
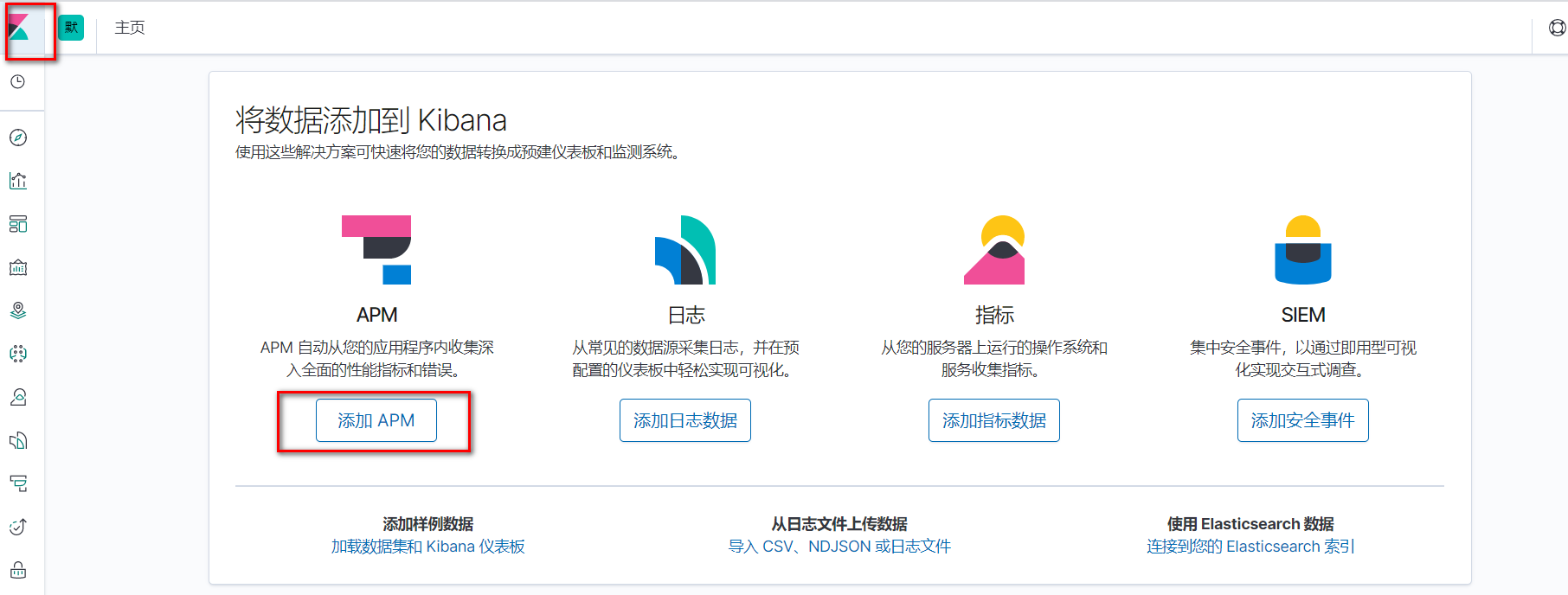
安装好kibana后,kibana的管理后台有安装指引的入口
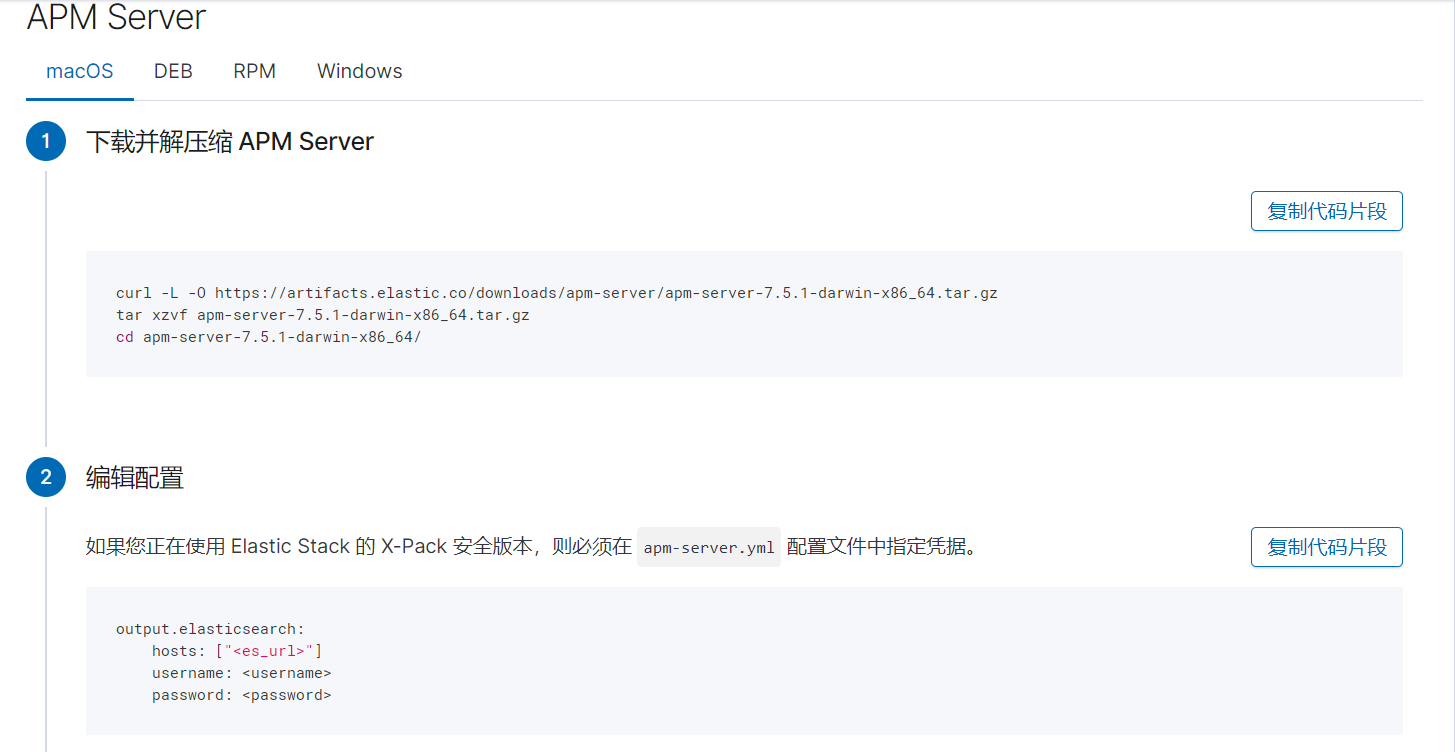
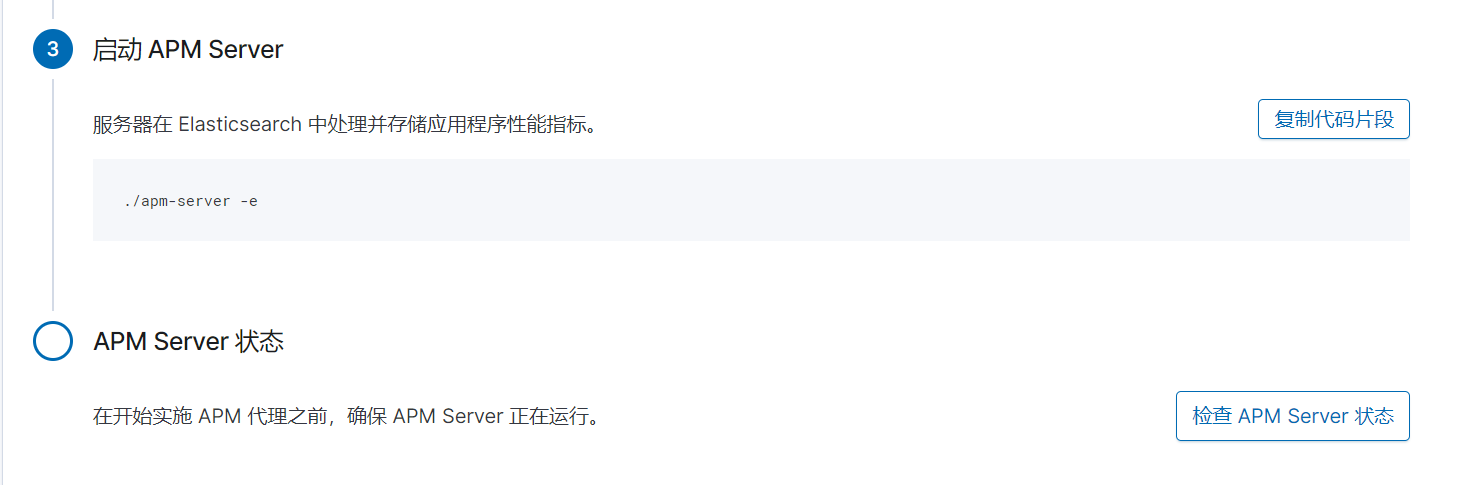
apm-server的配置 文件:
apm-server.yml
xxxxxxxxxx######################### APM Server Configuration ######################################################### APM Server ################################apm-server # Defines the host and port the server is listening on. Use "unix:/path/to.sock" to listen on a unix domain socket. host"192.168.9.93:8200" # Maximum permitted size in bytes of a request's header accepted by the server to be processed. #max_header_size: 1048576 # Maximum amount of time to wait for the next incoming request before underlying connection is closed. #idle_timeout: 45s # Maximum permitted duration for reading an entire request. #read_timeout: 30s # Maximum permitted duration for writing a response. #write_timeout: 30s # Maximum duration before releasing resources when shutting down the server. #shutdown_timeout: 5s # Maximum permitted size in bytes of an event accepted by the server to be processed. #max_event_size: 307200 # Maximum number of new connections to accept simultaneously (0 means unlimited). #max_connections: 0 # If true (default), APM Server captures the IP of the instrumented service # or the IP and User Agent of the real user (RUM requests). #capture_personal_data: true # Enable APM Server Golang expvar support (https://golang.org/pkg/expvar/). #expvar: #enabled: false # Url to expose expvar. #url: "/debug/vars" # Instrumentation support for the server's HTTP endpoints and event publisher. #instrumentation: # Set to true to enable instrumentation of the APM Server itself. #enabled: false # Environment in which the APM Server is running on (eg: staging, production, etc.) #environment: "" # Remote hosts to report instrumentation results to. #hosts: # - http://remote-apm-server:8200 # API Key for the remote APM Server(s). # If api_key is set then secret_token will be ignored. #api_key: # Secret token for the remote APM Server(s). #secret_token: # Enable profiling of the server, recording profile samples as events. # # This feature is experimental. #profiling: #cpu: # Set to true to enable CPU profiling. #enabled: false #interval: 60s #duration: 10s #heap: # Set to true to enable heap profiling. #enabled: false #interval: 60s # A pipeline is a definition of processors applied to documents when ingesting them to Elasticsearch. # Using pipelines involves two steps: # (1) registering a pipeline # (2) applying a pipeline during data ingestion (see `output.elasticsearch.pipeline`) # # You can manually register a pipeline, or use this configuration option to ensure # the pipeline is loaded and registered at the configured Elasticsearch instances. # Find the default pipeline configuration at `ingest/pipeline/definition.json`. # Automatic pipeline registration requires the `output.elasticsearch` to be enabled and configured. #register.ingest.pipeline: # Registers APM pipeline definition in Elasticsearch on APM Server startup. Defaults to true. #enabled: true # Overwrites existing APM pipeline definition in Elasticsearch. Defaults to false. #overwrite: false #---------------------------- APM Server - Secure Communication with Agents ----------------------------## 安全相关配置 # Enable secure communication between APM agents and the server. By default ssl is disabled. #ssl: #enabled: false # Configure a list of root certificate authorities for verifying client certificates. #certificate_authorities: [] # Path to file containing the certificate for server authentication. # Needs to be configured when ssl is enabled. #certificate: '' # Path to file containing server certificate key. # Needs to be configured when ssl is enabled. #key: '' # Optional configuration options for ssl communication. # Passphrase for decrypting the Certificate Key. # It is recommended to use the provided keystore instead of entering the passphrase in plain text. #key_passphrase: '' # List of supported/valid protocol versions. By default TLS versions 1.1 up to 1.2 are enabled. #supported_protocols: [TLSv1.1, TLSv1.2] # Configure cipher suites to be used for SSL connections. #cipher_suites: [] # Configure curve types for ECDHE based cipher suites. #curve_types: [] # Configure which type of client authentication is supported. # Options are `none`, `optional`, and `required`. Default is `optional`. #client_authentication: "optional" # Configure SSL verification mode. If `none` is configured, all hosts and # certificates will be accepted. In this mode, SSL-based connections are # susceptible to man-in-the-middle attacks. Use only for testing. Default is `full`. #ssl.verification_mode: full # The APM Server endpoints can be secured by configuring a secret token or enabling the usage of API keys. Both # options can be enabled in parallel, allowing Elastic APM agents to chose whichever mechanism they support. # As soon as one of the options is enabled, requests without a valid token are denied by the server. An exception # to this are requests to any enabled RUM endpoint. RUM endpoints are generally not secured by any token. # # Configure authorization via a common `secret_token`. By default it is disabled. # Agents include the token in the following format: Authorization: Bearer <secret-token>. # It is recommended to use an authorization token in combination with SSL enabled, # and save the token in the apm-server keystore. #secret_token: # Enable API key authorization by setting enabled to true. By default API key support is disabled. # Agents include a valid API key in the following format: Authorization: ApiKey <token>. # The key must be the base64 encoded representation of the API key's "id:key". # This is an experimental feature, use with care. #api_key: #enabled: false # Restrict how many unique API keys are allowed per minute. Should be set to at least the amount of different # API keys configured in your monitored services. Every unique API key triggers one request to Elasticsearch. #limit: 100 # API keys need to be fetched from Elasticsearch. If nothing is configured, configuration settings from the # output section will be reused. # Note that configuration needs to point to a secured Elasticsearch cluster that is able to serve API key requests. #elasticsearch: #hosts: ["localhost:9200"] #protocol: "http" # Username and password are only needed for the apm-server apikey sub-command, and they are ignored otherwise # See `apm-server apikey --help` for details. #username: "elastic" #password: "changeme" # Optional HTTP Path. #path: "" # Proxy server url. #proxy_url: "" #proxy_disable: false # Configure http request timeout before failing an request to Elasticsearch. #timeout: 10s # Enable custom SSL settings. Set to false to ignore custom SSL settings for secure communication. #ssl.enabled: true # Optional SSL configuration options. SSL is off by default, change the `protocol` option if you want to enable `https`. # Configure SSL verification mode. If `none` is configured, all server hosts # and certificates will be accepted. In this mode, SSL based connections are # susceptible to man-in-the-middle attacks. Use only for testing. Default is # `full`. #ssl.verification_mode: full # List of supported/valid TLS versions. By default all TLS versions 1.0 up to # 1.2 are enabled. #ssl.supported_protocols: [TLSv1.0, TLSv1.1, TLSv1.2] # List of root certificates for HTTPS server verifications. #ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] # Certificate for SSL client authentication. #ssl.certificate: "/etc/pki/client/cert.pem" # Client Certificate Key #ssl.key: "/etc/pki/client/cert.key" # Optional passphrase for decrypting the Certificate Key. # It is recommended to use the provided keystore instead of entering the passphrase in plain text. #ssl.key_passphrase: '' # Configure cipher suites to be used for SSL connections. #ssl.cipher_suites: [] # Configure curve types for ECDHE based cipher suites. #ssl.curve_types: [] # Configure what types of renegotiation are supported. Valid options are # never, once, and freely. Default is never. #ssl.renegotiation: never #---------------------------- APM Server - RUM Real User Monitoring ----------------------------## javascript-RUM 配置 # Enable Real User Monitoring (RUM) Support. By default RUM is disabled. # RUM does not support token based authorization. Enabled RUM endpoints will not require any authorization # token configured for other endpoints. #rum: #enabled: false #event_rate: # Defines the maximum amount of events allowed to be sent to the APM Server RUM # endpoint per IP per second. Defaults to 300. #limit: 300 # An LRU cache is used to keep a rate limit per IP for the most recently seen IPs. # This setting defines the number of unique IPs that can be tracked in the cache. # Sites with many concurrent clients should consider increasing this limit. Defaults to 1000. #lru_size: 1000 #-- General RUM settings # A list of permitted origins for real user monitoring. # User-agents will send an origin header that will be validated against this list. # An origin is made of a protocol scheme, host and port, without the url path. # Allowed origins in this setting can have * to match anything (eg.: http://*.example.com) # If an item in the list is a single '*', everything will be allowed. #allow_origins : ['*'] # Regexp to be matched against a stacktrace frame's `file_name` and `abs_path` attributes. # If the regexp matches, the stacktrace frame is considered to be a library frame. #library_pattern: "node_modules|bower_components|~" # Regexp to be matched against a stacktrace frame's `file_name`. # If the regexp matches, the stacktrace frame is not used for calculating error groups. # The default pattern excludes stacktrace frames that have a filename starting with '/webpack' #exclude_from_grouping: "^/webpack" # If a source map has previously been uploaded, source mapping is automatically applied. # to all error and transaction documents sent to the RUM endpoint. #source_mapping: # Sourcemapping is enabled by default. #enabled: true # Source maps are always fetched from Elasticsearch, by default using the output.elasticsearch configuration. # A different instance must be configured when using any other output. # This setting only affects sourcemap reads - the output determines where sourcemaps are written. #elasticsearch: # Array of hosts to connect to. # Scheme and port can be left out and will be set to the default (`http` and `9200`). # In case you specify and additional path, the scheme is required: `http://localhost:9200/path`. # IPv6 addresses should always be defined as: `https://[2001:db8::1]:9200`. # hosts: ["localhost:9200"] # Protocol - either `http` (default) or `https`. #protocol: "https" # Authentication credentials - either API key or username/password. #api_key: "id:api_key" #username: "elastic" #password: "changeme" # The `cache.expiration` determines how long a source map should be cached before fetching it again from Elasticsearch. # Note that values configured without a time unit will be interpreted as seconds. #cache: #expiration: 5m # Source maps are stored in a separate index. # If the default index pattern for source maps at 'outputs.elasticsearch.indices' # is changed, a matching index pattern needs to be specified here. #index_pattern: "apm-*-sourcemap*" #---------------------------- APM Server - Agent Configuration ---------------------------- # When using APM agent configuration, information fetched from Kibana will be cached in memory for some time. # Specify cache key expiration via this setting. Default is 30 seconds. #agent.config.cache.expiration: 30s## 使用kinbana远程代理 配置项 kibana # For APM Agent configuration in Kibana, enabled must be true. enabledtrue # Scheme and port can be left out and will be set to the default (`http` and `5601`). # In case you specify an additional path, the scheme is required: `http://localhost:5601/path`. # IPv6 addresses should always be defined as: `https://[2001:db8::1]:5601`. host"192.168.9.93:5601" # Optional protocol and basic auth credentials. #protocol: "https" #username: "elastic" #password: "changeme" # Optional HTTP path. #path: "" # Enable custom SSL settings. Set to false to ignore custom SSL settings for secure communication. #ssl.enabled: true # Optional SSL configuration options. SSL is off by default, change the `protocol` option if you want to enable `https`. # Configure SSL verification mode. If `none` is configured, all server hosts # and certificates will be accepted. In this mode, SSL based connections are # susceptible to man-in-the-middle attacks. Use only for testing. Default is # `full`. #ssl.verification_mode: full # List of supported/valid TLS versions. By default all TLS versions 1.0 up to # 1.2 are enabled. #ssl.supported_protocols: [TLSv1.0, TLSv1.1, TLSv1.2] # List of root certificates for HTTPS server verifications. #ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] # Certificate for SSL client authentication. #ssl.certificate: "/etc/pki/client/cert.pem" # Client Certificate Key #ssl.key: "/etc/pki/client/cert.key" # Optional passphrase for decrypting the Certificate Key. # It is recommended to use the provided keystore instead of entering the passphrase in plain text. #ssl.key_passphrase: '' # Configure cipher suites to be used for SSL connections. #ssl.cipher_suites: [] # Configure curve types for ECDHE based cipher suites. #ssl.curve_types: [] #---------------------------- APM Server - ILM Index Lifecycle Management ----------------------------## APM日志索引的生命周期配置 #ilm: # Supported values are `auto`, `true` and `false`. # `true`: Make use of Elasticsearch's Index Lifecycle Management (ILM) for APM indices. If no Elasticsearch output is # configured or the configured instance does not support ILM, APM Server cannot apply ILM and must create # unmanaged indices instead. # `false`: APM Server does not make use of ILM in Elasticsearch. # `auto`: If an Elasticsearch output is configured with default index and indices settings, and the configured # Elasticsearch instance supports ILM, `auto` will resolve to `true`. Otherwise `auto` will resolve to `false`. # Default value is `auto`. #enabled: "auto" #setup: # Only disable setup if you want to set up everything related to ILM on your own. # When setup is enabled, the APM Server creates: # - aliases and ILM policies if `apm-server.ilm.enabled` resolves to `true`. # - An ILM specific template per event type. This is required to map ILM aliases and policies to indices. In case # ILM is disabled, the templates will be created without any ILM settings. # Be aware that if you turn off setup, you need to manually manage event type specific templates on your own. # If you simply want to disable ILM, use the above setting, `apm-server.ilm.enabled`, instead. # Defaults to true. #enabled: true # Configure whether or not existing policies and ILM related templates should be updated. This needs to be # set to true when customizing your policies. # Defaults to false. #overwrite: false # Set `require_policy` to `false` when policies are set up outside of APM Server but referenced here. # Default value is `true`. #require_policy: true # The configured event types and policies will be merged with the default setup. You only need to configure # the mappings that you want to customize. #mapping: #- event_type: "error" # policy_name: "apm-rollover-30-days" #- event_type: "span" # policy_name: "apm-rollover-30-days" #- event_type: "transaction" # policy_name: "apm-rollover-30-days" #- event_type: "metric" # policy_name: "apm-rollover-30-days" # Configured policies are added to pre-defined default policies. # If a policy with the same name as a default policy is configured, the configured policy overwrites the default policy. #policies: #- name: "apm-rollover-30-days" #policy: #phases: #hot: #actions: #rollover: #max_size: "50gb" #max_age: "30d" #set_priority: #priority: 100 #warm: #min_age: "30d" #actions: #set_priority: #priority: 50 #readonly: {} #---------------------------- APM Server - Experimental Jaeger integration ----------------------------### Jaeger 集成 # When enabling Jaeger integration, APM Server acts as Jaeger collector. It supports jaeger.thrift over HTTP # and gRPC. This is an experimental feature, use with care. #jaeger: #grpc: # Set to true to enable the Jaeger gRPC collector service. #enabled: false # Defines the gRPC host and port the server is listening on. # Defaults to the standard Jaeger gRPC collector port 14250. #host: "localhost:14250" #http: # Set to true to enable the Jaeger HTTP collector endpoint. #enabled: false # Defines the HTTP host and port the server is listening on. # Defaults to the standard Jaeger HTTP collector port 14268. #host: "localhost:14268"#================================= General =================================## 内存队列大小配置# Data is buffered in a memory queue before it is published to the configured output.# The memory queue will present all available events (up to the outputs# bulk_max_size) to the output, the moment the output is ready to serve# another batch of events.#queue: # Queue type by name (default 'mem'). #mem: # Max number of events the queue can buffer. #events: 4096 # Hints the minimum number of events stored in the queue, # before providing a batch of events to the outputs. # The default value is set to 2048. # A value of 0 ensures events are immediately available # to be sent to the outputs. #flush.min_events: 2048 # Maximum duration after which events are available to the outputs, # if the number of events stored in the queue is < `flush.min_events`. #flush.timeout: 1s# Sets the maximum number of CPUs that can be executing simultaneously. The# default is the number of logical CPUs available in the system.#max_procs:#================================= Template =================================## ES模板配置 什么是ES模板? template >> index# A template is used to set the mapping in Elasticsearch.# By default template loading is enabled and the template is loaded.# These settings can be adjusted to load your own template or overwrite existing ones.# Set to false to disable template loading.#setup.template.enabled: true# Template name. By default the template name is "apm-%{[observer.version]}"# The template name and pattern has to be set in case the elasticsearch index pattern is modified.#setup.template.name: "apm-%{[observer.version]}"# Template pattern. By default the template pattern is "apm-%{[observer.version]}-*" to apply to the default index settings.# The first part is the version of apm-server and then -* is used to match all daily indices.# The template name and pattern has to be set in case the elasticsearch index pattern is modified.#setup.template.pattern: "apm-%{[observer.version]}-*"# Path to fields.yml file to generate the template.#setup.template.fields: "${path.config}/fields.yml"# Overwrite existing template.#setup.template.overwrite: false# Elasticsearch template settings.#setup.template.settings: # A dictionary of settings to place into the settings.index dictionary # of the Elasticsearch template. For more details, please check # https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html #index: #number_of_shards: 1 #codec: best_compression #number_of_routing_shards: 30 #mapping.total_fields.limit: 2000#============================= Elastic Cloud =============================# These settings simplify using APM Server with the Elastic Cloud (https://cloud.elastic.co/).# The cloud.id setting overwrites the `output.elasticsearch.hosts` option.# You can find the `cloud.id` in the Elastic Cloud web UI.#cloud.id:# The cloud.auth setting overwrites the `output.elasticsearch.username` and# `output.elasticsearch.password` settings. The format is `<user>:<pass>`.#cloud.auth:#================================ Outputs =================================# Configure the output to use when sending the data collected by apm-server.#-------------------------- Elasticsearch output --------------------------output.elasticsearch # Array of hosts to connect to. # Scheme and port can be left out and will be set to the default (`http` and `9200`). # In case you specify and additional path, the scheme is required: `http://localhost:9200/path`. # IPv6 addresses should always be defined as: `https://[2001:db8::1]:9200`. hosts"192.168.9.93:9200" # Boolean flag to enable or disable the output module. #enabled: true # Set gzip compression level. #compression_level: 0 # Protocol - either `http` (default) or `https`. #protocol: "https" # Authentication credentials - either API key or username/password. #api_key: "id:api_key" #username: "elastic" #password: "changeme" # Dictionary of HTTP parameters to pass within the url with index operations. #parameters: #param1: value1 #param2: value2 # Number of workers per Elasticsearch host. #worker: 1 # By using the configuration below, APM documents are stored to separate indices, # depending on their `processor.event`: # - error # - transaction # - span # - sourcemap # # The indices are all prefixed with `apm-%{[observer.version]}`. # To allow managing indices based on their age, all indices (except for sourcemaps) # end with the information of the day they got indexed. # e.g. "apm-7.3.0-transaction-2019.07.20" # # Be aware that you can only specify one Elasticsearch template. # If you modify the index patterns you must also update these configurations accordingly, # as they need to be aligned: # * `setup.template.name` # * `setup.template.pattern` #index: "apm-%{[observer.version]}-%{+yyyy.MM.dd}" #indices: # - index: "apm-%{[observer.version]}-sourcemap" # when.contains: # processor.event: "sourcemap" # # - index: "apm-%{[observer.version]}-error-%{+yyyy.MM.dd}" # when.contains: # processor.event: "error" # # - index: "apm-%{[observer.version]}-transaction-%{+yyyy.MM.dd}" # when.contains: # processor.event: "transaction" # # - index: "apm-%{[observer.version]}-span-%{+yyyy.MM.dd}" # when.contains: # processor.event: "span" # # - index: "apm-%{[observer.version]}-metric-%{+yyyy.MM.dd}" # when.contains: # processor.event: "metric" # # - index: "apm-%{[observer.version]}-onboarding-%{+yyyy.MM.dd}" # when.contains: # processor.event: "onboarding" # A pipeline is a definition of processors applied to documents when ingesting them to Elasticsearch. # APM Server comes with a default pipeline definition, located at `ingest/pipeline/definition.json`, which is # loaded to Elasticsearch by default (see `apm-server.register.ingest.pipeline`). # APM pipeline is enabled by default. To disable it, set `pipeline: _none`. #pipeline: "apm" # Optional HTTP Path. #path: "/elasticsearch" # Custom HTTP headers to add to each request. #headers: # X-My-Header: Contents of the header # Proxy server url. #proxy_url: http://proxy:3128 # The number of times a particular Elasticsearch index operation is attempted. If # the indexing operation doesn't succeed after this many retries, the events are # dropped. The default is 3. #max_retries: 3 # The maximum number of events to bulk in a single Elasticsearch bulk API index request. # The default is 50. #bulk_max_size: 50 # The number of seconds to wait before trying to reconnect to Elasticsearch # after a network error. After waiting backoff.init seconds, apm-server # tries to reconnect. If the attempt fails, the backoff timer is increased # exponentially up to backoff.max. After a successful connection, the backoff # timer is reset. The default is 1s. #backoff.init: 1s # The maximum number of seconds to wait before attempting to connect to # Elasticsearch after a network error. The default is 60s. #backoff.max: 60s # Configure http request timeout before failing an request to Elasticsearch. #timeout: 90 # Enable custom SSL settings. Set to false to ignore custom SSL settings for secure communication. #ssl.enabled: true # Optional SSL configuration options. SSL is off by default, change the `protocol` option if you want to enable `https`. # Configure SSL verification mode. If `none` is configured, all server hosts # and certificates will be accepted. In this mode, SSL based connections are # susceptible to man-in-the-middle attacks. Use only for testing. Default is # `full`. #ssl.verification_mode: full # List of supported/valid TLS versions. By default all TLS versions 1.0 up to # 1.2 are enabled. #ssl.supported_protocols: [TLSv1.0, TLSv1.1, TLSv1.2] # List of root certificates for HTTPS server verifications. #ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] # Certificate for SSL client authentication. #ssl.certificate: "/etc/pki/client/cert.pem" # Client Certificate Key #ssl.key: "/etc/pki/client/cert.key" # Optional passphrase for decrypting the Certificate Key. # It is recommended to use the provided keystore instead of entering the passphrase in plain text. #ssl.key_passphrase: '' # Configure cipher suites to be used for SSL connections. #ssl.cipher_suites: [] # Configure curve types for ECDHE based cipher suites. #ssl.curve_types: [] # Configure what types of renegotiation are supported. Valid options are # never, once, and freely. Default is never. #ssl.renegotiation: never#----------------------------- Console output -----------------------------#output.console: # Boolean flag to enable or disable the output module. #enabled: false # Configure JSON encoding. #codec.json: # Pretty-print JSON event. #pretty: false # Configure escaping HTML symbols in strings. #escape_html: false#---------------------------- Logstash output -----------------------------#output.logstash: # Boolean flag to enable or disable the output module. #enabled: false # The Logstash hosts. #hosts: ["localhost:5044"] # Number of workers per Logstash host. #worker: 1 # Set gzip compression level. #compression_level: 3 # Configure escaping html symbols in strings. #escape_html: true # Optional maximum time to live for a connection to Logstash, after which the # connection will be re-established. A value of `0s` (the default) will # disable this feature. # # Not yet supported for async connections (i.e. with the "pipelining" option set). #ttl: 30s # Optional load balance the events between the Logstash hosts. Default is false. #loadbalance: false # Number of batches to be sent asynchronously to Logstash while processing # new batches. #pipelining: 2 # If enabled only a subset of events in a batch of events is transferred per # group. The number of events to be sent increases up to `bulk_max_size` # if no error is encountered. #slow_start: false # The number of seconds to wait before trying to reconnect to Logstash # after a network error. After waiting backoff.init seconds, apm-server # tries to reconnect. If the attempt fails, the backoff timer is increased # exponentially up to backoff.max. After a successful connection, the backoff # timer is reset. The default is 1s. #backoff.init: 1s # The maximum number of seconds to wait before attempting to connect to # Logstash after a network error. The default is 60s. #backoff.max: 60s # Optional index name. The default index name is set to apm # in all lowercase. #index: 'apm' # SOCKS5 proxy server URL #proxy_url: socks5://user:password@socks5-server:2233 # Resolve names locally when using a proxy server. Defaults to false. #proxy_use_local_resolver: false # Enable SSL support. SSL is automatically enabled if any SSL setting is set. #ssl.enabled: false # Optional SSL configuration options. SSL is off by default. # Configure SSL verification mode. If `none` is configured, all server hosts # and certificates will be accepted. In this mode, SSL based connections are # susceptible to man-in-the-middle attacks. Use only for testing. Default is # `full`. #ssl.verification_mode: full # List of supported/valid TLS versions. By default all TLS versions 1.0 up to # 1.2 are enabled. #ssl.supported_protocols: [TLSv1.0, TLSv1.1, TLSv1.2] # List of root certificates for HTTPS server verifications. #ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] # Certificate for SSL client authentication. #ssl.certificate: "/etc/pki/client/cert.pem" # Client Certificate Key #ssl.key: "/etc/pki/client/cert.key" # Optional passphrase for decrypting the Certificate Key. # It is recommended to use the provided keystore instead of entering the passphrase in plain text. #ssl.key_passphrase: '' # Configure cipher suites to be used for SSL connections. #ssl.cipher_suites: [] # Configure curve types for ECDHE based cipher suites. #ssl.curve_types: [] # Configure what types of renegotiation are supported. Valid options are # never, once, and freely. Default is never. #ssl.renegotiation: never#------------------------------ Kafka output ------------------------------#output.kafka: # Boolean flag to enable or disable the output module. #enabled: false # The list of Kafka broker addresses from where to fetch the cluster metadata. # The cluster metadata contain the actual Kafka brokers events are published # to. #hosts: ["localhost:9092"] # The Kafka topic used for produced events. The setting can be a format string # using any event field. To set the topic from document type use `%{[type]}`. #topic: beats # The Kafka event key setting. Use format string to create unique event key. # By default no event key will be generated. #key: '' # The Kafka event partitioning strategy. Default hashing strategy is `hash` # using the `output.kafka.key` setting or randomly distributes events if # `output.kafka.key` is not configured. #partition.hash: # If enabled, events will only be published to partitions with reachable # leaders. Default is false. #reachable_only: false # Configure alternative event field names used to compute the hash value. # If empty `output.kafka.key` setting will be used. # Default value is empty list. #hash: [] # Authentication details. Password is required if username is set. #username: '' #password: '' # Kafka version libbeat is assumed to run against. Defaults to the "1.0.0". #version: '1.0.0' # Configure JSON encoding. #codec.json: # Pretty print json event #pretty: false # Configure escaping html symbols in strings. #escape_html: true # Metadata update configuration. Metadata do contain leader information # deciding which broker to use when publishing. #metadata: # Max metadata request retry attempts when cluster is in middle of leader # election. Defaults to 3 retries. #retry.max: 3 # Waiting time between retries during leader elections. Default is 250ms. #retry.backoff: 250ms # Refresh metadata interval. Defaults to every 10 minutes. #refresh_frequency: 10m # The number of concurrent load-balanced Kafka output workers. #worker: 1 # The number of times to retry publishing an event after a publishing failure. # After the specified number of retries, the events are typically dropped. # Set max_retries to a value less than 0 to retry # until all events are published. The default is 3. #max_retries: 3 # The maximum number of events to bulk in a single Kafka request. The default # is 2048. #bulk_max_size: 2048 # The number of seconds to wait for responses from the Kafka brokers before # timing out. The default is 30s. #timeout: 30s # The maximum duration a broker will wait for number of required ACKs. The # default is 10s. #broker_timeout: 10s # The number of messages buffered for each Kafka broker. The default is 256. #channel_buffer_size: 256 # The keep-alive period for an active network connection. If 0s, keep-alives # are disabled. The default is 0 seconds. #keep_alive: 0 # Sets the output compression codec. Must be one of none, snappy and gzip. The # default is gzip. #compression: gzip # Set the compression level. Currently only gzip provides a compression level # between 0 and 9. The default value is chosen by the compression algorithm. #compression_level: 4 # The maximum permitted size of JSON-encoded messages. Bigger messages will be # dropped. The default value is 1000000 (bytes). This value should be equal to # or less than the broker's message.max.bytes. #max_message_bytes: 1000000 # The ACK reliability level required from broker. 0=no response, 1=wait for # local commit, -1=wait for all replicas to commit. The default is 1. Note: # If set to 0, no ACKs are returned by Kafka. Messages might be lost silently # on error. #required_acks: 1 # The configurable ClientID used for logging, debugging, and auditing # purposes. The default is "beats". #client_id: beats # Enable SSL support. SSL is automatically enabled if any SSL setting is set. #ssl.enabled: false # Optional SSL configuration options. SSL is off by default. # Configure SSL verification mode. If `none` is configured, all server hosts # and certificates will be accepted. In this mode, SSL based connections are # susceptible to man-in-the-middle attacks. Use only for testing. Default is # `full`. #ssl.verification_mode: full # List of supported/valid TLS versions. By default all TLS versions 1.0 up to # 1.2 are enabled. #ssl.supported_protocols: [TLSv1.0, TLSv1.1, TLSv1.2] # List of root certificates for HTTPS server verifications. #ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] # Certificate for SSL client authentication. #ssl.certificate: "/etc/pki/client/cert.pem" # Client Certificate Key #ssl.key: "/etc/pki/client/cert.key" # Optional passphrase for decrypting the Certificate Key. # It is recommended to use the provided keystore instead of entering the passphrase in plain text. #ssl.key_passphrase: '' # Configure cipher suites to be used for SSL connections. #ssl.cipher_suites: [] # Configure curve types for ECDHE based cipher suites. #ssl.curve_types: [] # Configure what types of renegotiation are supported. Valid options are # never, once, and freely. Default is never. #ssl.renegotiation: never#================================= Paths ==================================# The home path for the apm-server installation. This is the default base path# for all other path settings and for miscellaneous files that come with the# distribution.# If not set by a CLI flag or in the configuration file, the default for the# home path is the location of the binary.path.home/app/soft/apm-server# The configuration path for the apm-server installation. This is the default# base path for configuration files, including the main YAML configuration file# and the Elasticsearch template file. If not set by a CLI flag or in the# configuration file, the default for the configuration path is the home path.path.config$path.home# The data path for the apm-server installation. This is the default base path# for all the files in which apm-server needs to store its data. If not set by a# CLI flag or in the configuration file, the default for the data path is a data# subdirectory inside the home path.path.data$path.home/data# The logs path for an apm-server installation. If not set by a CLI flag or in the# configuration file, the default is a logs subdirectory inside the home path.path.logs$path.home/logs#================================= Logging =================================# There are three options for the log output: syslog, file, and stderr.# Windows systems default to file output. All other systems default to syslog.# Sets the minimum log level. The default log level is info.# Available log levels are: error, warning, info, or debug.logging.leveldebug# Enable debug output for selected components. To enable all selectors use ["*"].# Other available selectors are "beat", "publish", or "service".# Multiple selectors can be chained.logging.selectors"*"# Send all logging output to syslog. The default is false.logging.to_syslogfalse# If enabled, apm-server periodically logs its internal metrics that have changed# in the last period. For each metric that changed, the delta from the value at# the beginning of the period is logged. Also, the total values for# all non-zero internal metrics are logged on shutdown. The default is false.#logging.metrics.enabled: false# The period after which to log the internal metrics. The default is 30s.#logging.metrics.period: 30s# Logging to rotating files. When true, writes all logging output to files.# The log files are automatically rotated when the log file size limit is reached.logging.to_filestruelogging.files # Configure the path where the logs are written. The default is the logs directory # under the home path (the binary location). path/app/soft/apm-server/logs/ # The name of the files where the logs are written to. nameapm-server.log # Configure log file size limit. If limit is reached, log file will be # automatically rotated. rotateeverybytes10485760 # = 10MB # Number of rotated log files to keep. Oldest files will be deleted first. keepfiles7 # The permissions mask to apply when rotating log files. The default value is 0600. # Must be a valid Unix-style file permissions mask expressed in octal notation. permissions0644 # Enable log file rotation on time intervals in addition to size-based rotation. # Intervals must be at least 1s. Values of 1m, 1h, 24h, 7*24h, 30*24h, and 365*24h # are boundary-aligned with minutes, hours, days, weeks, months, and years as # reported by the local system clock. All other intervals are calculated from the # Unix epoch. Defaults to disabled. interval24h# Set to true to log messages in json format.#logging.json: false#=============================== HTTP Endpoint ===============================# apm-server can expose internal metrics through a HTTP endpoint. For security# reasons the endpoint is disabled by default. This feature is currently experimental.# Stats can be access through http://localhost:5066/stats. For pretty JSON output# append ?pretty to the URL.# Defines if the HTTP endpoint is enabled.#http.enabled: false# The HTTP endpoint will bind to this hostname or IP address. It is recommended to use only localhost.#http.host: localhost# Port on which the HTTP endpoint will bind. Default is 5066.#http.port: 5066#============================= X-pack Monitoring =============================# APM server can export internal metrics to a central Elasticsearch monitoring# cluster. This requires x-pack monitoring to be enabled in Elasticsearch. The# reporting is disabled by default.# Set to true to enable the monitoring reporter.#monitoring.enabled: false# Most settings from the Elasticsearch output are accepted here as well.# Note that these settings should be configured to point to your Elasticsearch *monitoring* cluster.# Any setting that is not set is automatically inherited from the Elasticsearch# output configuration. This means that if you have the Elasticsearch output configured,# you can simply uncomment the following line.#monitoring.elasticsearch: # Protocol - either `http` (default) or `https`. #protocol: "https" # Authentication credentials - either API key or username/password. #api_key: "id:api_key" #username: "elastic" #password: "changeme" # Array of hosts to connect to. # Scheme and port can be left out and will be set to the default (`http` and `9200`). # In case you specify and additional path, the scheme is required: `http://localhost:9200/path`. # IPv6 addresses should always be defined as: `https://[2001:db8::1]:9200`. #hosts: ["localhost:9200"] # Set gzip compression level. #compression_level: 0 # Dictionary of HTTP parameters to pass within the URL with index operations. #parameters: #param1: value1 #param2: value2 # Custom HTTP headers to add to each request. #headers: # X-My-Header: Contents of the header # Proxy server url. #proxy_url: http://proxy:3128 # The number of times a particular Elasticsearch index operation is attempted. If # the indexing operation doesn't succeed after this many retries, the events are # dropped. The default is 3. #max_retries: 3 # The maximum number of events to bulk in a single Elasticsearch bulk API index request. # The default is 50. #bulk_max_size: 50 # The number of seconds to wait before trying to reconnect to Elasticsearch # after a network error. After waiting backoff.init seconds, apm-server # tries to reconnect. If the attempt fails, the backoff timer is increased # exponentially up to backoff.max. After a successful connection, the backoff # timer is reset. The default is 1s. #backoff.init: 1s # The maximum number of seconds to wait before attempting to connect to # Elasticsearch after a network error. The default is 60s. #backoff.max: 60s # Configure HTTP request timeout before failing an request to Elasticsearch. #timeout: 90 # Enable custom SSL settings. Set to false to ignore custom SSL settings for secure communication. #ssl.enabled: true # Optional SSL configuration options. SSL is off by default, change the `protocol` option if you want to enable `https`. # Configure SSL verification mode. If `none` is configured, all server hosts # and certificates will be accepted. In this mode, SSL based connections are # susceptible to man-in-the-middle attacks. Use only for testing. Default is # `full`. #ssl.verification_mode: full # List of supported/valid TLS versions. By default all TLS versions 1.0 up to # 1.2 are enabled. #ssl.supported_protocols: [TLSv1.0, TLSv1.1, TLSv1.2] # List of root certificates for HTTPS server verifications. #ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] # Certificate for SSL client authentication. #ssl.certificate: "/etc/pki/client/cert.pem" # Client Certificate Key #ssl.key: "/etc/pki/client/cert.key" # Optional passphrase for decrypting the Certificate Key. # It is recommended to use the provided keystore instead of entering the passphrase in plain text. #ssl.key_passphrase: '' # Configure cipher suites to be used for SSL connections. #ssl.cipher_suites: [] # Configure curve types for ECDHE based cipher suites. #ssl.curve_types: [] # Configure what types of renegotiation are supported. Valid options are # never, once, and freely. Default is never. #ssl.renegotiation: never #metrics.period: 10s #state.period: 1m
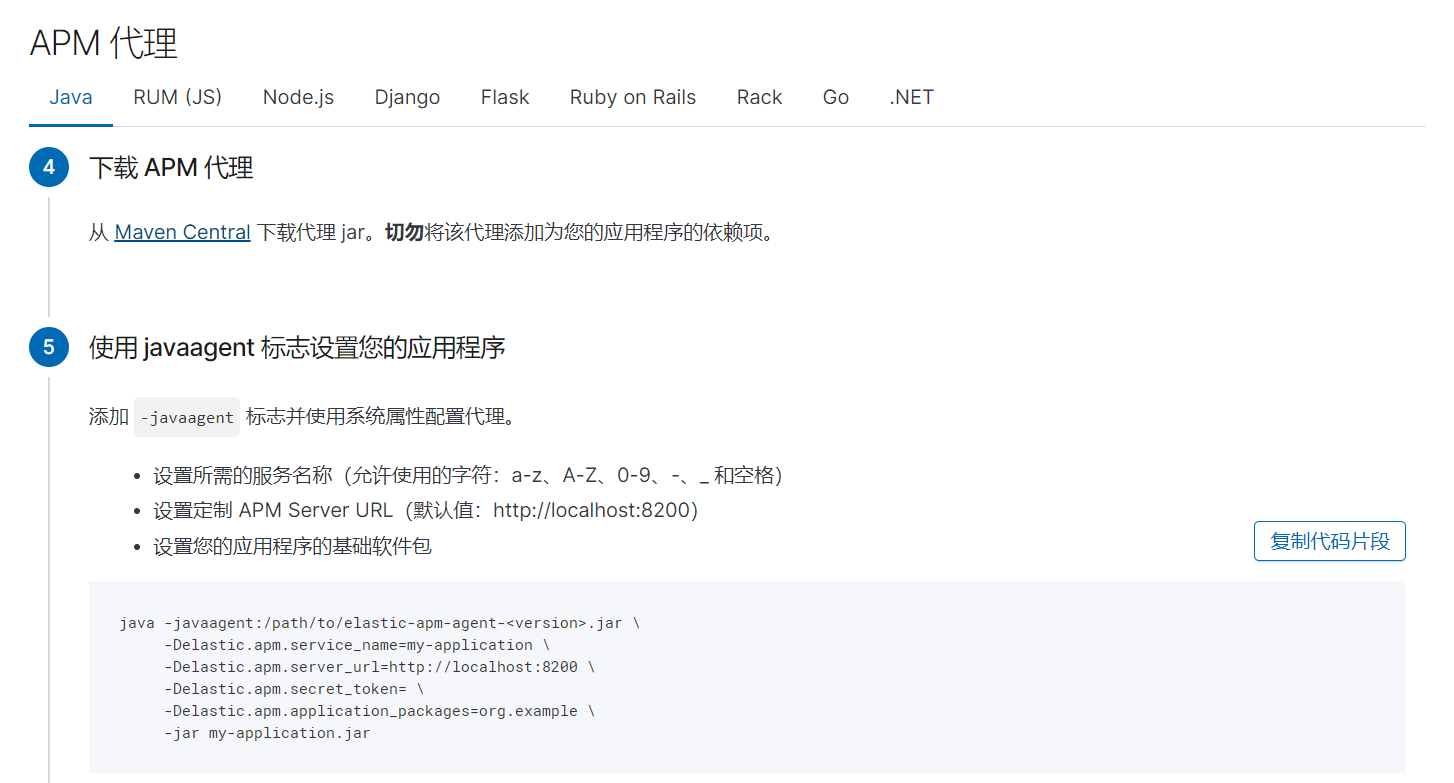
java代理使用的版本:
elastic-apm-agent-1.15.0.jar
代码集成:
https://www.elastic.co/guide/en/apm/get-started/7.5/configure-apm.html
帮助页面
配置参数指引:
https://www.elastic.co/guide/en/apm/agent/java/1.x/configuration.html
核心参数:
https://www.elastic.co/guide/en/apm/agent/java/1.x/config-core.html
手动配置参数:
https://www.elastic.co/guide/en/apm/agent/java/1.x/setup-javaagent.html
tomcat集成:文件目录: tomcat-x/bin/setnev.sh
xxxxxxxxxx##setnev.sh## apm-agent 代理jar包路径export CATALINA_OPTS="$CATALINA_OPTS -javaagent:/app/iParkCloudBase/liwei_use/agent/apm-server/elastic-apm-agent-1.15.0.jar"## apm 服务名称 对应kibana后台的apm服务列表下的名称export CATALINA_OPTS="$CATALINA_OPTS -Delastic.apm.service_name=82-apm-test-8001"##默认值 拦截入口export CATALINA_OPTS="$CATALINA_OPTS -Delastic.apm.application_packages=org.example,org.another.example"##export CATALINA_OPTS="$CATALINA_OPTS -Delastic.apm.server_urls=http://192.168.9.93:8200"export CATALINA_OPTS="$CATALINA_OPTS -Delastic.apm.service_node_name=192.168.9.82-8001"export CATALINA_OPTS="$CATALINA_OPTS -Delastic.apm.hostname=9.82:8001"export CATALINA_OPTS="$CATALINA_OPTS -Delastic.apm.log_level=debug"export CATALINA_OPTS="$CATALINA_OPTS -Delastic.apm.log_file=_AGENT_HOME_/logs/8001-elastic-apm.log"## log4j log4j2 logback 集成##export CATALINA_OPTS="$CATALINA_OPTS -Delastic.apm.enable_log_correlation=true"
apm的开销及性能调优:
https://www.elastic.co/guide/en/apm/agent/java/1.x/tuning-and-overhead.html
Elastic APM 版本对应代理版本的支持
https://www.elastic.co/guide/en/apm/get-started/7.6/agent-server-compatibility.html
ES 常用的查询
xxxxxxxxxxGET _search{ "query": { "match_all": {} }}DELETE /bee-log-*## query all GET bee-log-*/_search/{ "query": { "match_all": {} }}## query by idsGET bee-log-*/_search{ "query": { "ids" : { "values" : ["lTN1h3EBgyaril54Qn94"] } }}## apmGET apm-7.6.2-span/_search/{ "query": { "match_all": {} }}## apm by conditionGET apm-7.6.2-span/_search/{ "query": { "term": { "span.subtype": { "value": "mysql", "boost": 1 } } }}PUT /_cluster/settings{ "transient": { "cluster": { "max_shards_per_node":10000 } }}
入场请求:
扫码支付请求:
岗亭手动匹配订单:
月卡扫码续费:
扫码支付回调报错:
扫码支付回调成功:
ES APM





0 条评论