如果直接使用通义千问API从0到1来构建应用,技术成本还是相对比较高的。幸运的是,当前已经有非常优秀的框架LangChain来串联AIGC相关的各类组件,让我们轻松构建自己的应用。由于业务上对客户支持的需要,我在几个月前已经在LangChain模块中添加了调用通义千问API的模块代码。在这个时间点,刚好可以直接拿来使用。
在过去的一段时间,已经有很多同学分享了LangChain的框架和原理,本文则从实际开发角度出发,以构建应用过程中遇到的问题,和我们实际遇到的客户案例出发,来详细讲解LangChain的代码,希望给大家在基于通义API构建应用入门时提供一些启发和思路。本文主要包括几个部分:
4)如何提高大模型的问答准确率,比如如何更好地处理现有数据,如何使用思维链能力提升Agent的实际思考能力等。
LangChain模块
class Embeddings(ABC):"""Interface for embedding models."""def embed_documents(self, texts: List[str]) -> List[List[float]]:"""Embed search docs."""def embed_query(self, text: str) -> List[float]:
Agents模块 和chain类似,提供了丰富的agent模版,用于实现不同的agent,后面会详细介绍。
还有一些模块比如indexes,retrievers等都是上面这些模块的变种,以及提供一些可调用的工具类,比如tools等。这里就不再详细展开。我们会在后面的案例中讲解如何使用这些模块来构建自己的应用。
构建ChatBot
TextSplitter一篇文档的内容往往篇幅较长,由于LLM和Embedding token限制,无法将其全部传给LLM,因此将需要存储的文档按照一定的规则切分成内聚的小块chunk进行存储。
LLM模块 用于总结问题和回答问题。
Embedding模块 用于生产知识和问题的向量表示。
VectorStore模块 用于存储和检索匹配的本地知识内容。
一个比较清晰的调用链路图如下(比较经典清晰,老图借用):
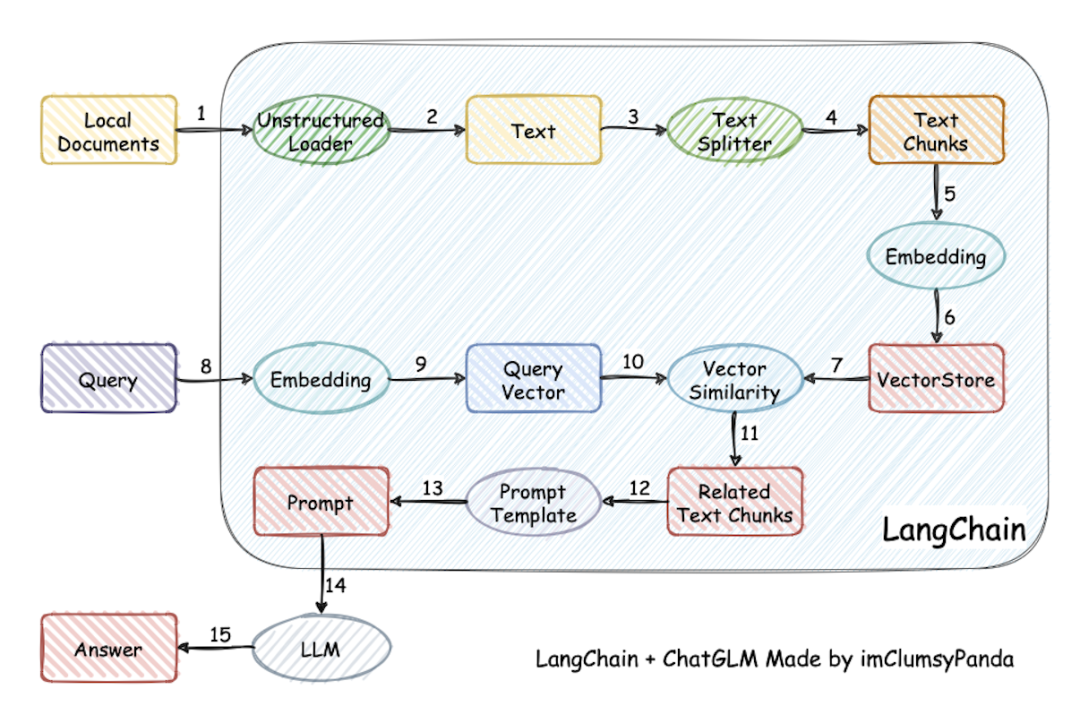
Example
基于通义API和ADB-PG向量数据库的ChatBot
首先我们从Google拉取一些问答数据,然后调用Dashscope上的Embedding模型进行向量化,并写入AnalyticDB PostgreSQL。
from langchain.chains import RetrievalQAfrom langchain.llms import Tongyios.environ["DASHSCOPE_API_KEY"] = "your-dashscope-api-key"llm = Tongyi()
问题和挑战
在我们实际给用户提供构建一站式ChatBot的过程中,我们依然遇到了很多问题,比如文本切分过碎,导致语义丢失,文本包含图表,切分后导致段落无法被理解等。
-
文本切分器 向量的匹配度直接影响召回率,而向量的召回率又和内容本身以及问题紧密联系在一起,哪怕有一个很强大的embedding模型,如果文本切分本身做的不好,也无法达到用户的预期效果。比如LangChain本身提供的CharacterTextSplitter,其会根据标点符号和换行符等来切分段落,在一些多级标题的场景下,小标题会被切分成单独的chunk,与正文分割开,导致被切分的标题和正文都无法很内聚地表达需要表达的内容。
-
优化切分长度,过长的chunk会导致在召回后达到token限制,过小的chunk又可能丢失想要找到的关键信息。我们尝试过很多切分策略,发现如果不做深度的优化,将文本直接按照200-500个token长度来切分反而效果比较好。
-
召回优化1. 回溯上下文,在某些场景,我们能够准确地召回内容,但是这部分内容并不全,因此我们可以在写入时为chunk按照文章级别构建id,在召回时额外召回最相关chunk的相邻chunk,随后做拼接。
-
召回优化2. 构建标题树,在富文本场景,用户非常喜欢使用多级标题,有些文本内容在脱离标题之后就无法了解其究竟在说什么,这时我们可以通过构建内容标题树的方式来优化chunk.比如把chunk按照下面的方式构建。
-
双路召回,纯向量召回有时候会因为对专有名词的不理解导致无法召回相关内容,这时可以考虑使用向量和全文检索进行双路召回,在召回后再做精排去重。在全文检索时,我们可以通过额外增加自定义专有名词库和虚词屏蔽的方式来进一步优化召回效果。 -
问题优化,有时候用户的问题本身并不适合做向量匹配,这时我们可以根据聊天历史让模型来总结独立问题,来提升召回率,提高回答准确度。
虽然我们做了很多优化,但是由于用户的文档本身五花八门,现在依然无法找到一个完全通用的方案来应对所有的数据源.比如某一切分器在markdown场景表现很好,但是对于pdf就效果下降得厉害。比如有的用户还要求能够在召回文本的同时召回图片,视频甚至ppt的slice.目前我们也只是通过metadata link的方式召回相关内容,而不是把相关内容直接做向量化。如果有同学有很好的办法,欢迎在评论区交流。
构建AI Agent
Agent System组成
在以LLM为核心的自主代理系统中,LLM是Agent的大脑,我们还需要一些其他的组件来补全它的四肢。AI Agent主要借助思维链和思维树的思想,提高Agent的思考和决策能力。
Planning
planning的作用有两个:
-
进行子任务的设定和拆解: 实际生活中的任务往往是复杂的,需要将大任务分解为更小、可管理的子目标,从而能够有效处理复杂任务。
-
进行自我反思和迭代: 通过对过去的行动进行自我批评和反思,从错误中学习并为将来的步骤进行完善,从而提高最终结果的质量。
Memory
短期记忆:将所有上下文学习(参见提示工程)视为利用模型的短期记忆来学习。
长期记忆:这为代理提供了在长时间内保留和检索(无限)信息的能力,通常通过利用外部向量存储和快速检索来实现。
Tools
Tools模块可以让Agent调用外部API以获取模型权重中缺失的额外信息(通常在预训练后难以更改),包括实时信息、代码执行能力、访问专有信息源等。通常是通过设计API的方式让LLM调用执行。
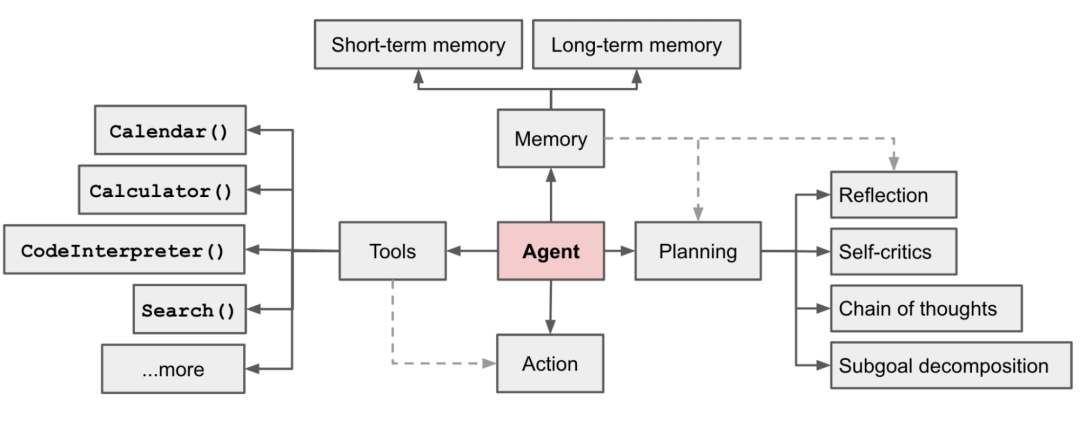
Planning模块
一个复杂的任务通常包括许多步骤。代理需要知道这些步骤并提前规划。
任务拆解
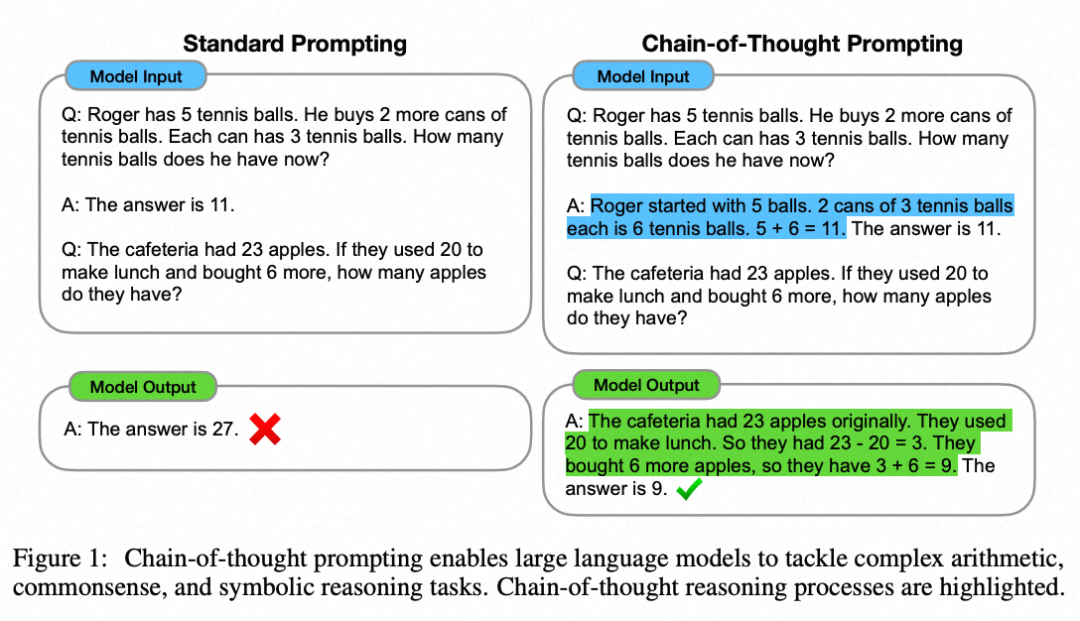
思维链(Chain of thought) (CoT; Wei et al. 2022)已经成为提高模型在复杂任务上性能的标准提示技术。模型被指示“逐步思考”,以利用更多的测试时间计算来将困难任务分解成更小更简单的步骤。CoT将大任务转化为多个可管理的任务,并揭示了模型思考过程的解释。
思维树(Tree of Thoughts) (Yao et al. 2023) 通过在每一步探索多种推理可能性来扩展了CoT。它首先将问题分解为多个思维步骤,并在每一步生成多种思考,创建一个树状结构。搜索过程可以是广度优先搜索(BFS)或深度优先搜索(DFS),每个状态都由分类器(通过提示)或多数投票进行评估。
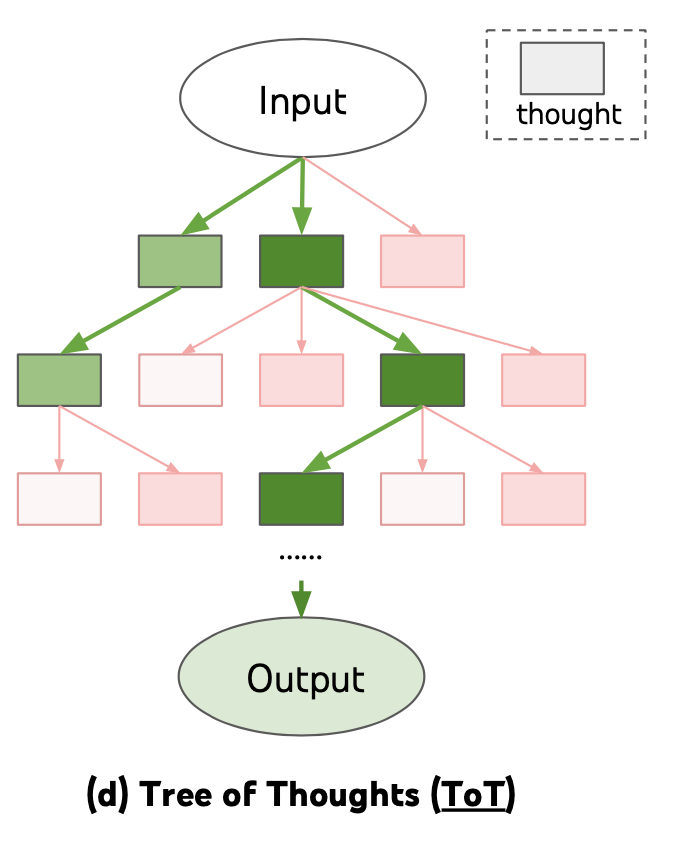
任务拆解可以通过以下方式完成:(1)LLM使用简单的提示,如“完成任务X需要a、b、c的步骤。n1。”,“实现任务X的子目标是什么?”,(2)使用任务特定的指令;例如,“撰写文案大纲。”,或者(3)通过交互式输入指定需要操作的步骤。
自我反思(Self-Reflection)是一个非常重要的思想,它允许Agent通过改进过去的行动决策和纠正以前错误的方式来不断提高。在可以允许犯错和试错的现实任务中,它发挥着关键作用。比如写一段某个用途的脚本代码。
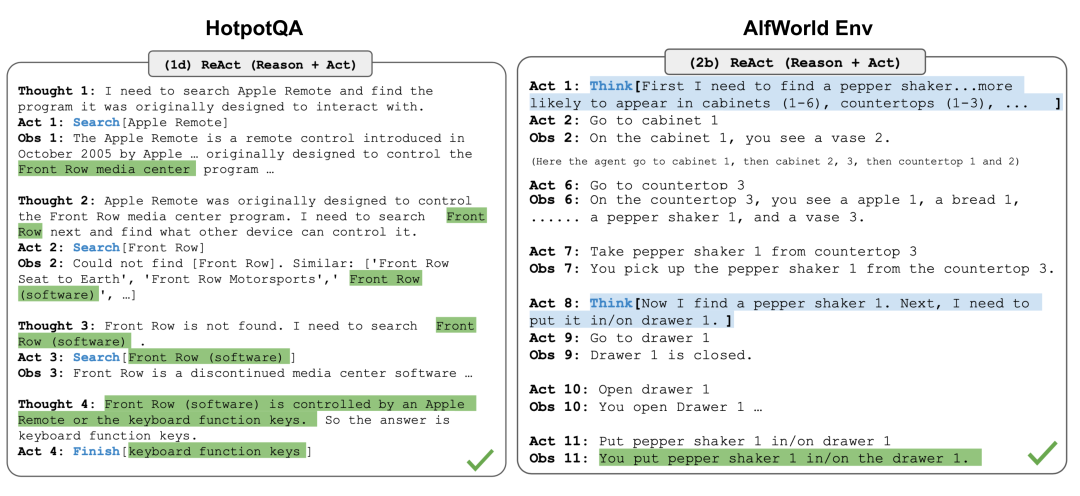
ReAct (Yao et al. 2023)通过将行动空间扩展为任务特定的离散行动和语言空间的组合,将推理和行动整合到LLM中。前者使LLM能够与环境互动(例如使用搜索引擎API),而后者促使LLM生成自然语言中的推理轨迹。
ReAct的prompt template包含了明确的步骤,供LLM思考,大致格式如下:
Thought: ...Action: ...Observation: ...... (Repeated many times)
Memory模块
记忆可以定义为用于获取、存储、保留和以后检索信息的过程。对于人类大脑,有几种类型的记忆。
感觉记忆:这是记忆的最早阶段,它使我们能够在原始刺激结束后保留感觉信息(视觉、听觉等)的能力。感觉记忆通常只持续几秒钟。子类别包括图像记忆(视觉)、声音记忆(听觉)和触觉记忆(触觉)。
短期记忆(Short-Term Memory):它存储我们当前意识到的信息,需要执行复杂的认知任务,如学习和推理。短期记忆的容量被认为约为7个项目(Miller 1956),持续时间为20-30秒。
长期记忆(Long-Term Memory):长期记忆可以存储信息很长时间,范围从几天到数十年,具有本质上无限的存储容量。长期记忆有两个子类型:
显式/陈述性记忆:这是关于事实和事件的记忆,指的是那些可以有意识地回忆起来的记忆,包括情节记忆(事件和经历)和语义记忆(事实和概念)。
隐式/程序性记忆:这种记忆是无意识的,涉及自动执行的技能和例行程序,如骑自行车,在键盘上打字等。

我们可以粗略地考虑以下映射关系:
感觉记忆是为原始输入内容(包括文本、图像或其他模态),其可以在embedding之后作为输入。
短期记忆就像上下文内容,也就是聊天历史,它是短暂而有限的,因为受到Token长度的限制。
长期记忆就像Agent可以在查询时参考的外部向量存储,可以通过快速检索访问。
外部存储可以缓解有限注意力跨度的限制。一个标准的做法是将信息的嵌入表示保存到一个向量存储数据库中,该数据库可以支持快速的最大内积搜索(Maximum Inner Product Search)。为了优化检索速度,常见的选择是使用近似最近邻(ANN)算法,以返回近似的前k个最近邻,可以在略微损失一些准确性的情况下获得巨大的速度提升。对于相似性算法有兴趣的同学可以阅读这篇文章《ChatGPT都推荐的向量数据库,不仅仅是向量索引》。
Tool模块
使用工具可以使LLM完成一些其本身不能直接完成的事情。
Modular Reasoning, Knowledge and Language (Karpas et al. 2022)提出了一个MRKL系统,包含一组专家模块,通用的LLM作为路由器,将查询路由到最合适的专家模块。这些模块可以是其他模型(文生图,领域模型等)或功能模块(例如数学计算器、货币转换器、天气API)。现在最典型的方式就是使用ChatGPT的function call功能。通过对ChatGPT注册和描述接口的含义,就可以让ChatGPT帮我们调用对应的接口,返回正确的答案。
典型案例-AUTOGPT
autogpt通过类似下面的prompt可以成功完成一些复杂的任务,比如review开源项目的代码,给开源项目代码写注释。最近看到了Aone Copilot,其主要focus在代码补全和代码问答两个场景。那么如果我们可以调用Aone Copilot的API,是否也可以在我们推送mr之后,让agent帮我们完成一些代码风格,语法校验的代码review工作,和单元测试用例编写工作。
LangChain已经内置了很多agent实现的框架模块,主要包含:
agent_toolkits
这个模块目前是实验性的,其目的是为了模拟代替甚至超越ChatGPT plugin的能力,通过提供一系列的工具集提供链式调用,来让用户组装自己的workflow.比较典型的包括发送邮件功能, 执行python代码,执行用户提供的sql,调用zapier api等。
toolkits主要通过注册机制向agent返回一系列可以调用的tool。其基类代码为BaseToolkit。
class BaseToolkit(BaseModel, ABC):"""Base Toolkit representing a collection of related tools."""def get_tools(self) -> List[BaseTool]:"""Get the tools in the toolkit."""
Example2 SQL Agent
这个case是结合大模型和数据库,通过查询表里的数据来回答用户问题,用的关键prompt为
问题和挑战
和ChatBot不同,agent的构建是对LLM的推理能力提出了更高的要求。ChatBot的回答可能是不正确的,但这依然可以通过人类的判别回馈来确定问答结果是否有益,对于无效的回答可以容忍地直接忽略或者重新回答。 但是agent对模型的错误判断的容忍度则更低。虽然我们可以通过自我反思机制减少agent的出错率,但是其当前可以应用的场景依然较小。需要我们不断去探索和开拓新的场景,同时不断提高大模型的推理能力,从而能够搭建更加复杂的agent。
同时,agent目前能够在比较小的场景胜任工作,比如我们的意图是明确的,同时也只给agent提供了比较少量的toolkit来执行任务(10个以内),且每个tool的用差异明显,在这种情况下,LLM能够正确选择tool进行任务,并得到期望的结果。但是当一个agent里注册了上百个甚至更多工具时,LLM就可能无法正确地选择tool执行操作了。这里的一个解法是通过多层agent树的方式来解决,父agent负责路由分发任务给不同的子agent。每一个子agent则仅仅包含和使用有限的toolkit来执行任务,从而提高agent复杂场景的任务完成率。
云原生数据仓库 AnalyticDB 是一种大规模并行处理数据仓库服务,可提供海量数据在线分析服务。在云原生数据仓库能力上全自研企业级向量引擎,支持流式向量数据写入、百亿级向量数据检索;支持结构化数据分析、向量检索和全文检索多路召回,支持对接通义千问等国内外主流大模型。
了解更多 AnalyticDB 介绍和相关解决方案请参考:
AnalyticDB向量引擎介绍:https://www.aliyun.com/activity/database/adbpg_vector
一键部署PAI+通义千问+AnalyticDB向量引擎搭建ChatBot:https://computenest.console.aliyun.com/user/cn-hangzhou/serviceInstanceCreate?ServiceId=service-ddfecdd9b626465f85b6
-
通义千问 官网API文档:https://help.aliyun.com/zh/dashscope/developer-reference/api-details?spm=a2c4g.11186623.0.0.1ea416e9s2tYEJ -
LangChain官方文档:https://python.langchain.com/docs/get_started/introduction -
https://github.com/langchain-ai/langchainLangChain源码仓库 -
https://github.com/chatchat-space/Langchain-Chatchat LangChain优秀的中文大模型集成项目 -
OpenAI Cookbook 拥有很多使用LLM构建应用的优秀案例:https://github.com/openai/openai-cookbook -
https://github.com/RGGH/OpenAI_SQL/blob/master/LangChain_01.ipynb ChatBI example source code -
Zhao et al. “Calibrate Before Use: Improving Few-shot Performance of Language Models.” ICML 2021:https://arxiv.org/abs/2102.09690 -
Yao et al. “ReAct: Synergizing reasoning and acting in language models.” ICLR 2023.:https://arxiv.org/abs/2210.03629 -
Yao et al. “Tree of Thoughts: Dliberate Problem Solving with Large Language Models.” arXiv preprint arXiv:2305.10601 (2023).:https://arxiv.org/abs/2305.10601 -
Liu et al. “Chain of Hindsight Aligns Language Models with Feedback “ arXiv preprint arXiv:2302.02676 (2023).:https://arxiv.org/abs/2302.02676 -
Zhang et al. “Automatic chain of thought prompting in large language models.” arXiv preprint arXiv:2210.03493 (2022).:https://arxiv.org/abs/2210.03493 -
Schick et al. “Toolformer: Language Models Can Teach Themselves to Use Tools.” arXiv preprint arXiv:2302.04761 (2023).:https://arxiv.org/abs/2302.04761 -
Yao et al. “Tree of Thoughts: Deliberate Problem Solving with Large Language Models.” arXiv preprint arXiv:2305.10601 (2023).:https://arxiv.org/abs/2305.10601 -
https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/#chain-of-thought-cot -
https://lilianweng.github.io/posts/2023-06-23-agent/ LLM使用优秀的博客文章
0 条评论