前几天 Elon Musk 在线 @xAI,宣布本周将开源 Grok,没想到它真的来了,我满怀欣喜的打开 GitHub,然后…
Grok-1(Open Release of Grok-1[1])是一款由 xAI 开发的大型语言模型,拥有 3140 亿个参数,属于混合专家模型(MoE:Mixture-of-Experts model)。模型特点是在处理每个 token 时,只有 25% 的权重(weights)被激活。它是在 2023 年 10 月,利用 JAX 和 Rust 构建的自定义训练栈,从头开始训练的。
该模型的基础模型权重和网络架构现已在 GitHub 上公开发布,并未经过针对任何特定任务的微调,因此它是预训练阶段的原始模型。开源协议遵循 Apache 2.0 许可证。

Grok-1
下载运行
看上去很简单嘛,我来跑一个!
Grok-1(xai-org/grok-1[2])存储库提供了使用 JAX 框架加载和运行 Grok-1 模型的示例代码。要运行这些示例,用户需要先下载模型的检查点文件,将其放置在指定的目录中(将下载的 ckpt-0 目录放置在 checkpoint 目录中),然后执行以下命令来安装依赖并运行示例:
# download
git clone https://github.com/xai-org/grok-1.git
cd grok-1
# install
pip install -r requirements.txt
python run.py
注意:运行代码需要一台拥有充足 GPU 内存的机器,因为 Grok-1 模型的参数量非常庞大。此外,虽然存储库中包含的 MoE(混合专家模型)层的实现不是最高效的,但它被选用是为了避免使用自定义内核,从而更容易验证模型的正确性。
用户可以通过以下磁力链接使用种子客户端下载模型权重:
magnet:?xt=urn:btih:5f96d43576e3d386c9ba65b883210a393b68210e&tr=https%3A%2F%2Facademictorrents.com%2Fannounce.php&tr=udp%3A%2F%2Ftracker.coppersurfer.tk%3A6969&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce
无法运行
无法运行,真的太大了…
本来还幻想本地运行一下,但当我打开磁力链接时,就彻底断绝了想法。七百多个文件,近 300G(这还只是模型下载)…

打开 Grok issues,不出所料,清一色在询问在本地运行 Grok,需要什么样的配置。
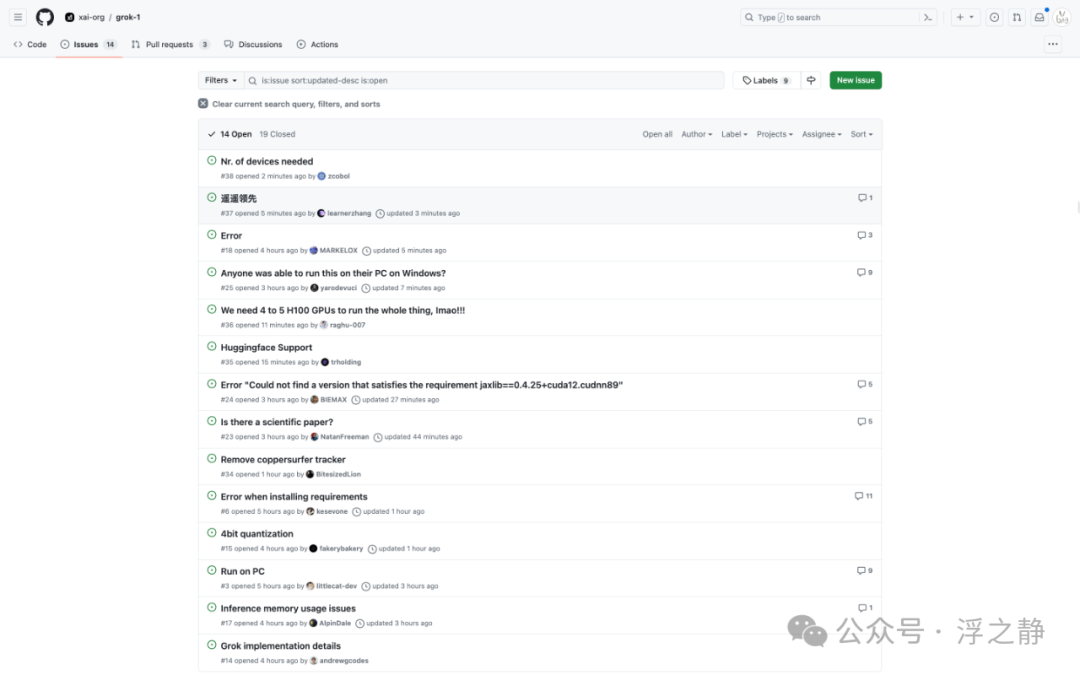
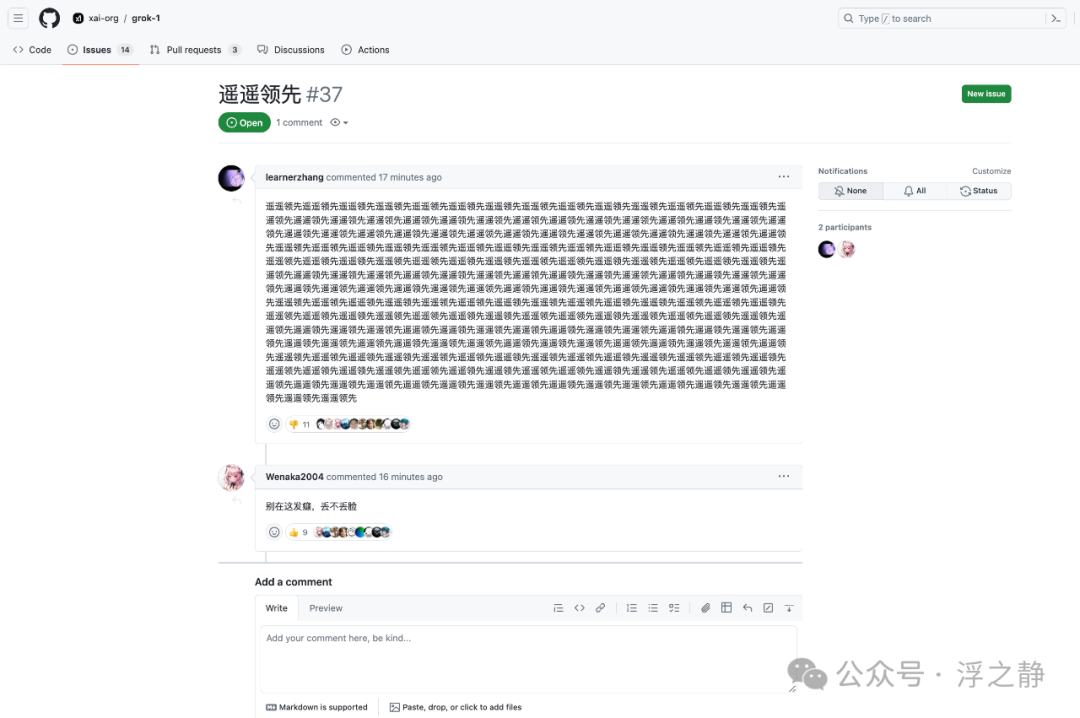
看到“遥遥领先”的 issues,真不知道该说些什么…,在开源社区总有一些人在不断拉低国人的下限…
运行要求
普通人缺的不是开源模型,而是显卡…
我翻阅了大量 issues,总结出运行 Grok 的最低配置要求(仅作为参考):
-
#3[3]:在 FP16 下大约需要 630GB 的显存,可能会达到 700GB。使用 8 个 H100 是否能运行还是未知数,我认为在它被优化之前,你无法在 CPU 上运行它。在 FP16 精度下,Grok-1 模型大约需要 630GB 至 700GB 的显存。即便配置了 8 个 NVIDIA H100 GPU,能否成功运行该模型仍不确定。在进行某些优化(如通过 GGUF[4] 工具)之前,这个模型可能无法在 CPU 上运行。
-
#24[5]:你需要拥有 TPU 或 NVIDIA/AMD 品牌的 GPU,且系统中必须装有 8 个此类设备。当前不支持 Apple silicon 设备(如 M1、M2、M3 等)。尽管 Jax 提供了一个 Metal 插件,让你可以在苹果芯片上运行 Jax(Accelerated JAX training on Mac[6]),但在使用 dm_haiku[7] 依赖时仍会遇到问题。即便克服了这些技术障碍,苹果芯片设备可能也没有足够的内存来运行如此庞大的 Grok-1 模型。
-
#25[8]:需要 8 个 GPU,每个 GPU 拥有 80GB 的显存,典型的选择是 A100 型号。即使是使用 4 个 NVIDIA 4090 显卡,也只能在 4 位量化的情况下勉强容纳模型的权重,而无法实际运行模型。此外,所需的硬件成本极高,单个 A100 的价格约为 12,000 美元,而一台配备 4 个 A100 GPU 的 NVIDIA DGX Station 的起价在 120,000 美元左右。因此,尽管技术上可行,但这样的配置对于大多数人来说是不切实际的。
从源码中(grok-1/model.py[9])可以获取到的其他相关信息(#14[10]):
-
3140 亿参数(314B parameters)
-
8 个专家的混合体(Mixture of 8 Experts)
-
每个 token 使用 2 个专家(2 experts used per token)
-
64 层(64 layers)
-
查询的 48 个注意力头(48 attention heads for queries)
-
键/值的 8 个注意力头(8 attention heads for keys/values)
-
嵌入大小:6144(embeddings size: 6,144)
-
旋转嵌入(rotary embeddings, RoPE)
-
SentencePiece 分词器;131,072 个令牌(SentencePiece tokenizer; 131,072 tokens)
-
支持激活分片和 8 位量化(Supports activation sharding and 8-bit quantization)
-
最大序列长度(上下文):8192 个 token(Max seq length (context): 8,192 tokens)
名词解释
JAX
JAX[11] 是一个专为加速器优化的数组计算和程序转换设计的 Python 库,主要目标是高性能数值计算和大规模机器学习。它通过改进的 Autograd[12] 版本,能够自动计算 Python 和 NumPy 函数的导数,支持复杂结构的自动微分,包括循环、分支、递归和闭包,并能进行多阶导数计算。
一个关键特性是 JAX 利用 XLA(Accelerated Linear Algebra)编译器将 NumPy 代码编译运行在 GPU 和 TPU 上,实现高效的计算。这种编译是即时进行的,无需用户干预。此外,JAX 提供了 jit 函数,允许用户将自定义 Python 函数即时编译成 XLA 优化的内核,极大提升性能。
JAX 支持的功能不仅限于自动微分和即时编译,它还包括自动向量化(通过 vmap)和单程序多数据(SPMD)并行编程(通过pmap),使得在多加速器环境下的编程变得简单。JAX 旨在使得复杂的算法能够在 Python 环境下高效实现,同时保持代码的可读性和可维护性。
尽管 JAX 是一个强大的工具,但它仍然是一个研究项目,并非正式的 Google 产品,因此可能存在一些错误和不足之处。开发团队鼓励用户尝试使用 JAX,并通过报告问题或提供反馈来帮助改进项目。
GGUF
由 @ggerganov[13] 开发,他也是 llama.cpp(一个流行的 C/C++ LLM 推理框架)的开发者。原先在 PyTorch 等框架中开发的模型可以转换为 GGUF 格式,以便在这些推理引擎中使用。
GGUF 是一种专为快速加载和保存模型而设计的二进制文件格式,主要用于与基于 GGML[14] 的执行器进行推理。这种格式是为了高效地进行模型推理而优化的,支持单文件部署,具有良好的可扩展性,兼容 mmap 以实现快速加载,易于使用,且包含加载模型所需的全部信息。
它是 GGML、GGMF 和 GGJT 格式的后续版本,采用键值结构存储元数据,以提高灵活性和扩展性。这种结构允许在不影响现有模型兼容性的前提下,为模型添加新的元数据或额外信息。

mmap
mmap(内存映射,memory-mapped files)是一种在文件和内存间直接映射的技术,允许应用程序直接从内存中访问文件内容,而无需进行传统的读写操作。这种技术可以显著提高文件访问的效率,特别是对于大型文件的处理。
当一个文件被 mmap 映射到内存时,操作系统会为该文件内容在内存中创建一个直接映射。应用程序可以像访问普通内存一样访问这部分映射的内存,而操作系统会负责将任何更改同步回文件本身,或者从文件中拉取最新的数据到内存中。
在机器学习和深度学习中,mmap 可以用于快速加载大型模型权重或数据集。例如,使用 mmap 可以在不将整个文件内容一次性加载到内存的情况下,实现对大型模型权重文件的快速随机访问。这样做可以显著减少模型加载时间和运行时内存消耗。
具体到 GGUF 格式,利用 mmap 可以实现对模型文件的快速加载和保存,尤其是在处理大型模型时,这种方法可以大大提高效率和性能。通过将模型文件映射到内存,模型加载和推理过程中对权重的访问将更加迅速,从而提升整体的推理速度。
References
Open Release of Grok-1: https://x.ai/blog/grok-os
[2]
xai-org/grok-1: https://github.com/xai-org/grok-1
[3]
#3: https://github.com/xai-org/grok-1/issues/3
[4]
GGUF: https://github.com/ggerganov/ggml/blob/master/docs/gguf.md
[5]
#24: https://github.com/xai-org/grok-1/issues/24
[6]
Accelerated JAX training on Mac
: https://developer.apple.com/metal/jax
[7]
dm_haiku: https://github.com/google-deepmind/dm-haiku
[8]
#25: https://github.com/xai-org/grok-1/issues/25
[9]
grok-1/model.py: https://github.com/xai-org/grok-1/blob/main/model.py
[10]
#14: https://github.com/xai-org/grok-1/issues/14
[11]
JAX: https://github.com/google/jax
[12]
Autograd: https://github.com/HIPS/autograd
[13]
@ggerganov: https://github.com/ggerganov
[14]
GGML: https://github.com/ggerganov/ggml
0 条评论