导语:本文详细介绍了 ElasticSearch 如搜索性能指标、索引性能指标、内存使用和垃圾回收指标等六类监控关键指标、集群和索引两类大盘配置示例,以及 ES 在查询性能差、索引性能差的两种典型问题场景下详细的原因、排查方式和解决方案,同时也介绍了如何通过 Prometheus 监控搭建可靠的监控系统,详尽全面,推荐给大家,也欢迎各位一起交流。
1. ElasticSearch 简介
-
实时性:ElasticSearch 能够实时地存储、检索和分析数据,使得用户能够快速获得最新的搜索结果和分析数据;
-
分布式:ElasticSearch 采用分布式架构,能够水平扩展,处理 PB 级结构化或非结构化数据,同时具有高可用性和容错性;
-
多样化的搜索和分析功能:ElasticSearch 支持全文搜索、结构化查询、过滤、地理空间查询和复杂的分析功能;
-
可扩展性:ElasticSearch 提供了丰富的插件和 API,可以轻松地扩展其功能。
节点(Node)
-
主节点:处理创建,删除索引等请求,维护集群状态信息。可以设置一个节点不承担主节点角色;
-
协调节点:负责处理请求。默认情况下,每个节点都可以是协调节点;
-
数据节点:用来保存数据。可以设置一个节点不承担数据节点角色。
集群(Cluster)
ElasticSearch 是一个分布式的搜索引擎,所以一般由多台物理机组成。而在这些机器上通过配置一个相同的 cluster name,可以让其互相发现从而把自己组织成一个集群。
分片 & 副本(Shards & Replicas)
Index (索引)
类型(Type)
Document (文档)
字段(Fields)
映射(mapping)
示例
PUT members{"mappings": {"properties": {"id": {"type": "long"},"name": {"type": "text"},"birthday": {"type": "date"}}}}
PUT members/_doc/10086{ "id": 10086, "name": "法外狂徒张三", "birthday": "1990-10-24T09:00:00Z"}
-
搜索引擎:在网站、应用或文档存储中提供全文搜索功能。例如,一个电子商务网站使用 ElasticSearch 来让用户快速搜索产品;
-
日志和指标分析:用于收集、存储和分析日志以及指标数据。例如,一个网络应用程序使用 ElasticSearch 来存储和分析其日志文件,以便监控性能和排查问题;
-
实时数据分析:用于实时分析和可视化大规模的实时数据。例如,一个金融机构使用 ElasticSearch 来监控交易数据和实时市场动态;
-
内容推荐:用于根据用户偏好和行为提供个性化的内容推荐。例如,一个新闻网站使用 ElasticSearch 来推荐相关新闻文章给用户;
-
业务指标监控:用于跟踪和监控业务指标以支持决策。例如,一个企业使用 ElasticSearch 来监控销售数据和库存情况。
2. 监控关键指标
ElasticSearch 提供了大量的指标,可以用于监控各类故障现象:
-
搜索性能指标
-
索引性能指标
-
内存使用和垃圾回收指标
-
主机级别网络系统指标
-
集群健康和节点可用性指标
-
资源饱和度和错误
-
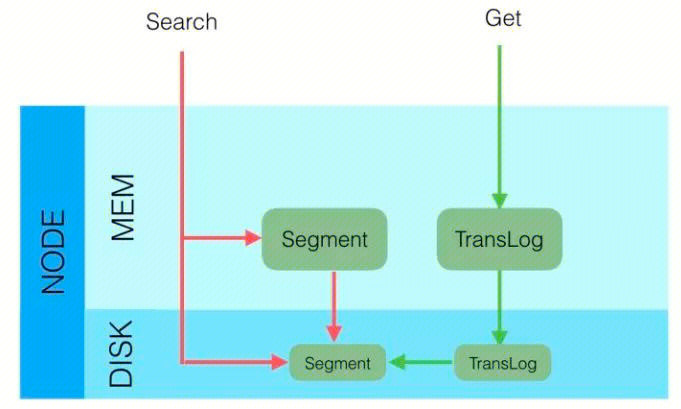
根据 ID 查询 Doc,可实时检索写入的数据。检索流程:检索内存中 Translog → 检索磁盘 Translog → 检索磁盘 Segment;
-
根据 query 查询 Doc,近实时检索写入的数据。检索流程:检索 filesystem cache中 segmnet → 检索磁盘 Segment。
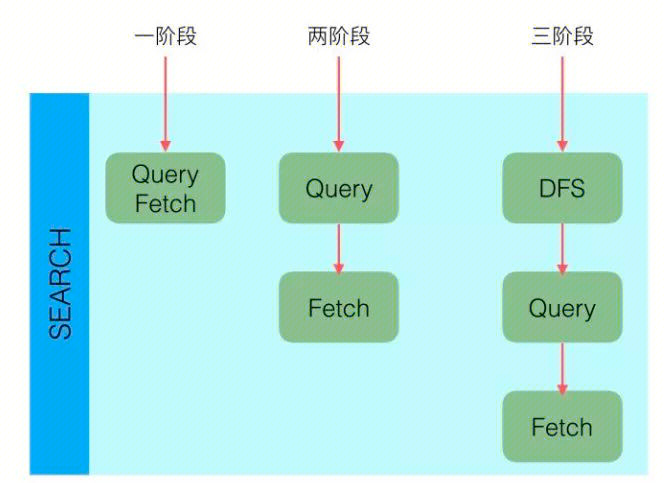
QUERY_AND_FETCH:查询完就返回整个 Doc 内容,对应根据 ID 查询 Doc;
QUERY_THEN_FETCH:先查询出对应的 Doc id ,然后再根据 Doc id 匹配去对应的文档;
DFS_QUERY_THEN_FETCH:在 QUERY_THEN_FETCH 的基础上多了算分环节。
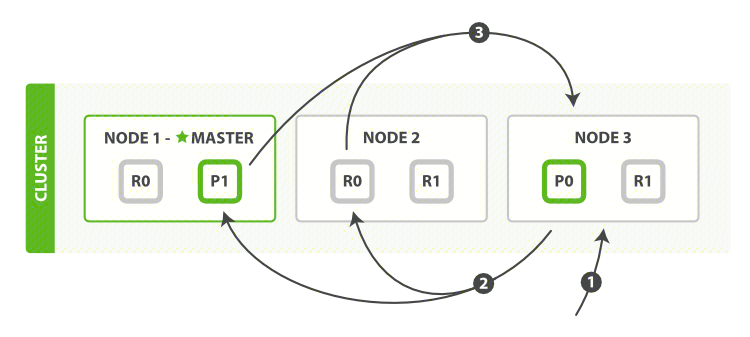
-
客户端发送一个 search 请求到 NODE 3 , NODE 3 会创建一个大小为 from + size 的空优先队列;
-
Node 3 将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为 from + size 的本地有序优先队列中;
-
每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,也就是 NODE 3 ,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
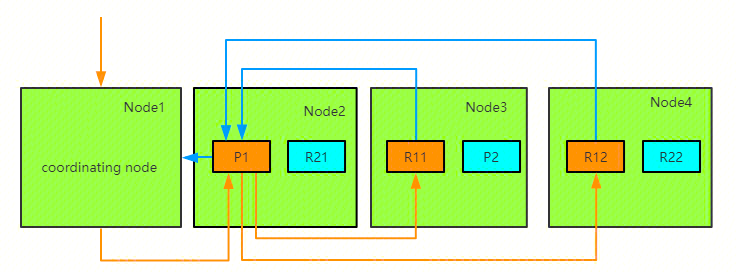
-
协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求;
-
每个分片加载并丰富文档,如果有需要的话,接着返回文档给协调节点;
-
一旦所有的文档都被取回了,协调节点返回结果给客户端。

相关指标
| 序号 | 指标 | 类型 | 详情 |
|---|---|---|---|
| 1 | elasticsearch_indices_search_query_total | counter | 查询总数 吞吐量 |
| 2 | elasticsearch_indices_search_query_time_seconds | counter | 查询总时间 性能 |
| 3 | elasticsearch_indices_search_fetch_total | counter | 提取总数 |
| 4 | elasticsearch_indices_search_fetch_time_seconds | counter | 花费在提取上的总时间 |
| 5 | elasticsearch_indices_get_time_seconds | counter | GET请求总时间 |
| 6 | elasticsearch_indices_get_missing_total | counter | 丢失的文件的GET请求总数 |
| 7 | elasticsearch_indices_get_missing_time_seconds | counter | 花费在文档丢失的GET请求上的总时间 |
| 8 | elasticsearch_indices_get_exists_time_seconds | counter | 花费在文档存在的GET请求上的总时间 |
| 9 | elasticsearch_indices_get_exists_total | counter | 存在的文件的GET请求总数 |
| 10 | elasticsearch_indices_get_total | counter | GET请求总次数 |
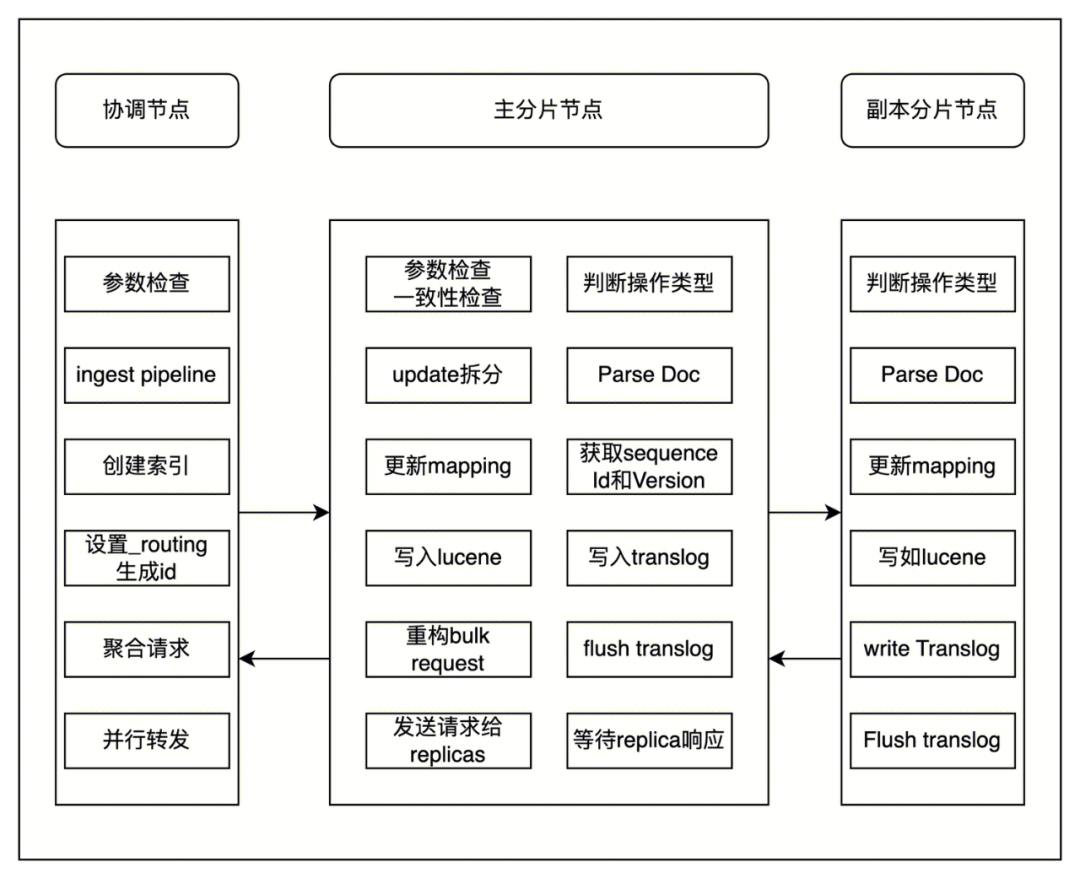
ES 写入流程介绍
相关指标
| 序号 | 指标 | 类型 | 详情 |
|---|---|---|---|
| 1 | elasticsearch_indices_indexing_index_total | counter | 被索引的文档总数 |
| 2 | elasticsearch_indices_indexing_index_time_seconds_total | counter | 索引文档花费的总时间 |
| 3 | elasticsearch_indices_refresh_total | counter | 索引refresh的总数 |
| 4 | elasticsearch_indices_refresh_time_seconds_total | counter | refresh索引总共话费的时间 |
| 5 | elasticsearch_indices_flush_total | counter | flush索引到磁盘的总数 |
| 6 | elasticsearch_indices_flush_time_seconds | counter | flush索引到磁盘的总花费时间 |
| 7 | elasticsearch_indices_merges_total | counter | Total merges(merge操作总次数) |
| 8 | elasticsearch_indices_merges_total_time_seconds_total | counter | 索引merge操作总花费时间 |
| 9 | elasticsearch_indices_merges_Docs_total | counter | merge的文档总数 |
| 10 | elasticsearch_indices_merges_total_size_bytes_total | counter | merge的数据量合计 |
| 11 | elasticsearch_indices_indexing_delete_total | counter | 索引的文件删除总数 |
| 12 | elasticsearch_indices_indexing_delete_time_seconds_total | counter | 索引的文件删除总时间 |
| 序号 | 指标 | 类型 | 详情 |
|---|---|---|---|
| 1 | elasticsearch_jvm_gc_collection_seconds_sum | counter | JVM GC垃圾回收时间 |
| 2 | elasticsearch_jvm_gc_collection_seconds_count | counter | JVM GC 垃圾搜集数 |
| 3 | elasticsearch_jvm_memory_committed_bytes | gauge | JVM最大使用内存限制 |
| 4 | elasticsearch_jvm_memory_max_bytes | gauge | 配置的最大jvm值 |
| 5 | elasticsearch_jvm_memory_pool_max_bytes | counter | JVM内存最大池数 |
| 6 | elasticsearch_jvm_memory_pool_peak_max_bytes | counter | 最大的JVM内存峰值 |
| 7 | elasticsearch_jvm_memory_pool_peak_used_bytes | counter | 池使用的JVM内存峰值 |
| 8 | elasticsearch_jvm_memory_pool_used_bytes | gauge | 目前使用的JVM内存池 |
| 9 | elasticsearch_jvm_memory_used_bytes | gauge | JVM内存使用量 |
主机级别资源及网络使用情况也需要关注。
| 序号 | 指标 | 类型 | 详情 |
|---|---|---|---|
| 1 | elasticsearch_process_cpu_percent | gauge | CPU使用率 |
| 2 | elasticsearch_filesystem_data_free_bytes | gauge | 磁盘可用空间 |
| 3 | elasticsearch_process_open_files_count | gauge | ES进程打开的文件描述符 |
| 4 | elasticsearch_transport_rx_packets_total | counter | ES节点之间网络入流量 |
| 5 | elasticsearch_transport_tx_packets_total | counter | ES节点之间网络出流量 |
相关指标
| 序号 | 指标 | 类型 | 详情 |
|---|---|---|---|
| 1 | elasticsearch_cluster_health_status | gauge | 集群状态,green( 所有的主分片和副本分片都正常运行)、yellow(所有的主分片都正常运行,但不是所有的副本分片都正常运行)red(有主分片没能正常运行)值为1的即为对应状态 |
| 2 | elasticsearch_cluster_health_number_of_data_nodes | gauge | node节点的数量 |
| 3 | elasticsearch_cluster_health_number_of_in_flight_fetch | gauge | 正在进行的碎片信息请求的数量 |
| 4 | elasticsearch_cluster_health_number_of_nodes | gauge | 集群内所有的节点 |
| 5 | elasticsearch_cluster_health_number_of_pending_tasks | gauge | 尚未执行的集群级别更改 |
| 6 | elasticsearch_cluster_health_initializing_shards | gauge | 正在初始化的分片数 |
| 7 | elasticsearch_cluster_health_unassigned_shards | gauge | 未分配分片数 |
| 8 | elasticsearch_cluster_health_active_primary_shards | gauge | 活跃的主分片总数 |
| 9 | elasticsearch_cluster_health_active_shards | gauge | 活跃的分片总数(包括复制分片) |
| 10 | elasticsearch_cluster_health_relocating_shards | gauge | 当前节点正在迁移到其他节点的分片数量,通常为0,集群中有节点新加入或者退出时该值会增加 |
| 11 | elasticsearch_breakers_tripped | counter | 熔断发生次数 |
| 12 | elasticsearch_breakers_limit_size_bytes | gauge | 熔断内存限制大小 |
| 13 | elasticsearch_breakers_estimated_size_bytes | gauge | 熔断器内存大小 |
相关指标
| 序号 | 指标 | 类型 | 详情 |
|---|---|---|---|
| 1 | elasticsearch_thread_pool_completed_count | gauge | 线程池操作完成线程数 |
| 2 | elasticsearch_thread_pool_active_count | gauge | 线程池活跃线程数 |
| 3 | elasticsearch_thread_pool_largest_count | gauge | 线程池最大线程数 |
| 4 | elasticsearch_thread_pool_queue_count | gauge | 线程池中的排队线程数 |
| 5 | elasticsearch_thread_pool_active_count | gauge | 线程池的被拒绝线程数 |
| 6 | elasticsearch_indices_fielddata_memory_size_bytes | gauge | fielddata缓存的大小(字节) |
| 7 | elasticsearch_indices_fielddata_evictions | gauge | 来自fielddata缓存的驱逐次数 |
3. 监控大盘
Prometheus 监控服务提供了开箱即用的 Grafana 监控大盘,根据预设大盘可以直接监控 ES 集群各类重要指标状态,能够进行问题的快速定位。本文集群大盘使用了腾讯云 ES 作为数据源,腾讯云 Elasticsearch Service(ES)是云端全托管海量数据检索分析服务,拥有高性能自研内核,集成X-Pack。ES 支持通过自治索引、存算分离、集群巡检等特性轻松管理集群,也支持免运维、自动弹性、按需使用的 Serverless 模式。使用 ES 您可以高效构建信息检索、日志分析、运维监控等服务,它独特的向量检索还可助您构建基于语义、图像的AI深度应用。
集群概要

分片监控(Shards)

熔断监控(Breakers)

-
Tripped for breakers:分析各类型的熔断器熔断的次数;
-
Estimated size in bytes of breaker:分析给类型熔断器熔断内存使用量。
节点监控
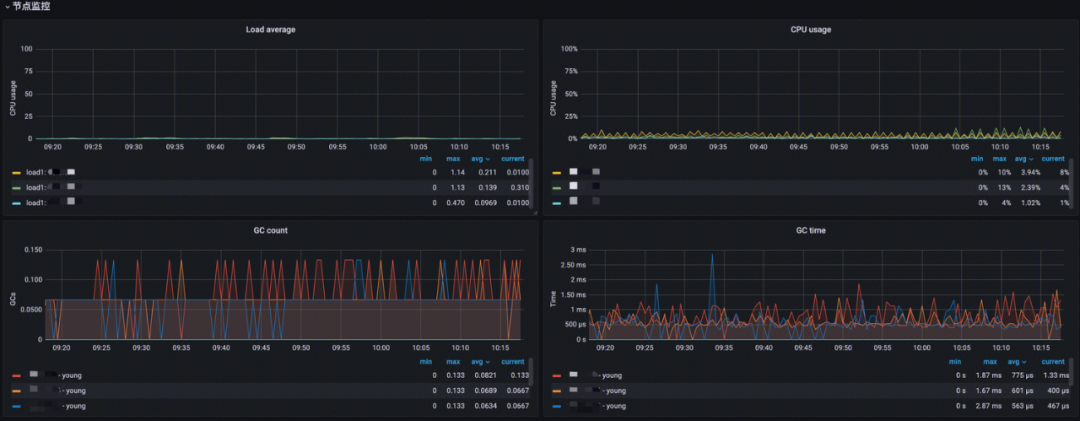
-
Load average:分析各节点的短期平均负载;
-
CPU usage:分析 CPU 使用率;
-
GC count:分析 JVM GC 运行次数;
-
GC time:分析 JVM GC 运行时间。
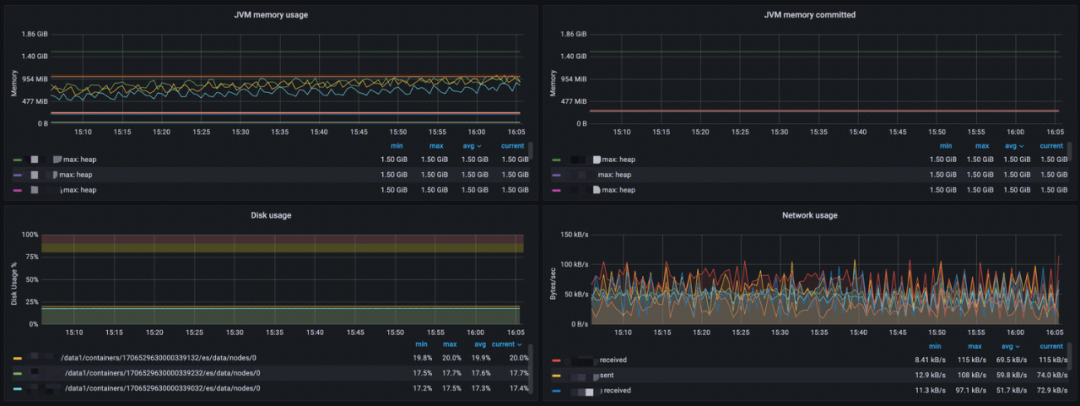
-
JVM memory usage:分析 JVM 内存使用量、内存最大限制以及池内存使用峰值;
-
JVM memory committed:分析各区域提交内存使用量;
-
Disk usage:分析数据存储使用情况;
-
Network usage:分析网络使用情况,包括发送和接收。
线程池监控(Thread Pool)
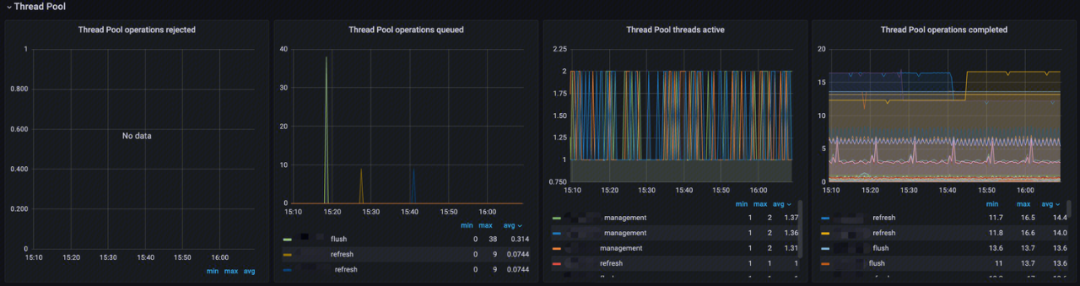
-
Thread Pool operations rejected:分析线程池中各类型操作拒绝率;
-
Thread Pool operations queued:分析线程池中各类型线程排队数;
-
Thread Pool threads active:分析线程池中各类型活跃线程数;
-
Thread Pool operations completed:分析线程池中各类型线程完成数。
Translog

-
Total Translog Operations:分析 Translog 操作总数;
-
Total Translog size in bytes:查看 Translog 内存使用趋势,分析性能是否影响写入性能。
文档(Documents)
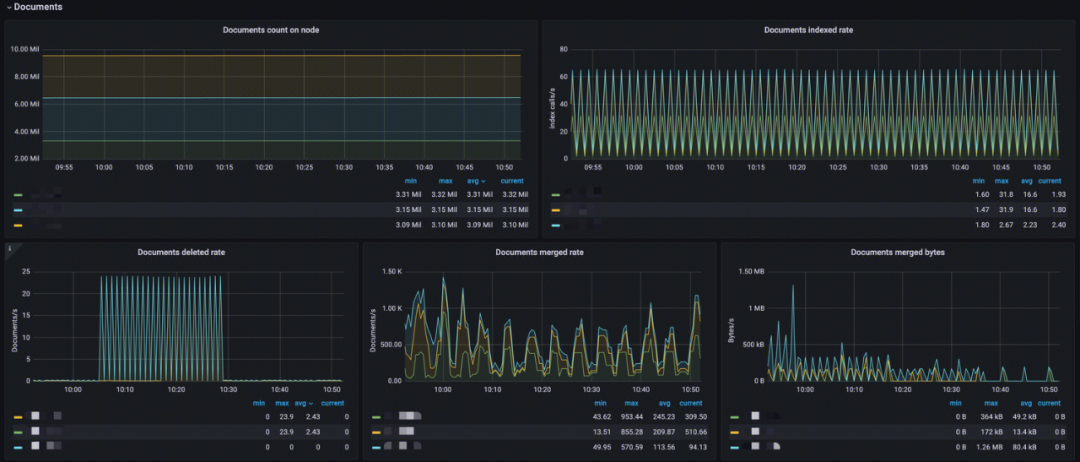
-
Documents count on node:分析节点 Index 文档数,看索引是否过大;
-
Documents indexed rate:分析 Index 索引速率;
-
Documents deleted rate:分析 Index 文档删除速率;
-
Documents merged rate:分析索引文档 merge 速率;
-
Documents merged bytes:分析 Index merge 内存大小。
延时
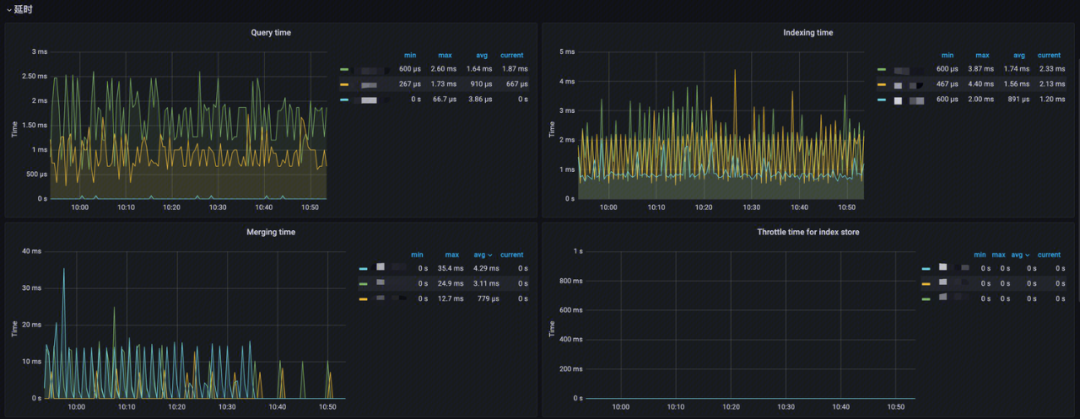
-
Query time:分析 Index 查询耗时;
-
Indexing time:分析索引文档耗时;
-
Merging time:分析索引 merge 操作耗时;
-
Throttle time for index store:Index 写入限制时间,分析 merge 与写入的合理性。
索引操作次数及耗时(Total Operation stats)

-
Total Operations rate:分析 Index 索引操作速率、查询速率、查询 fetch 速率,merge 速率、refresh 速率、flush 速率、GET 存在的速率、GET 不存在的速率、GET操作速率、Index 删除速率;
-
Total Operations time:分析 Index 索引操作耗时、查询耗时、查询 fetch 耗时,merge 耗时、refresh 耗时、flush 耗时、GET 存在的耗时、GET 不存在的耗时、GET操作耗时、Index 删除耗时。
线程池(Thread Pool)
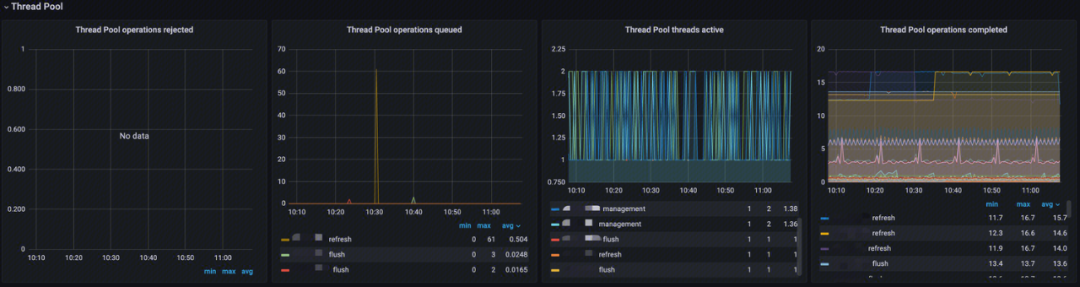
-
Thread Pool operations rejected:分析线程池中各类型操作拒绝率;
-
Thread Pool operations queued:分析线程池中各类型线程排队数;
-
Thread Pool threads active:分析线程池中各类型活跃线程数;
-
Thread Pool operations completed:分析线程池中各类型线程完成数。
缓存(Caches)

-
Field data memory size:分析 Fielddata 缓存大小;
-
Field data evictions:分析 Fielddata 缓存达到驱逐限制后驱逐的数据的速率;
-
Query cache size:分析查询缓存大小;
-
Query cache evictions:分析 Query 缓存达到驱逐限制后驱逐的数据的速率;
-
Evictions from filter cache:分析过滤查询达到驱逐限制后驱逐的数据的速率。
段(Segments)
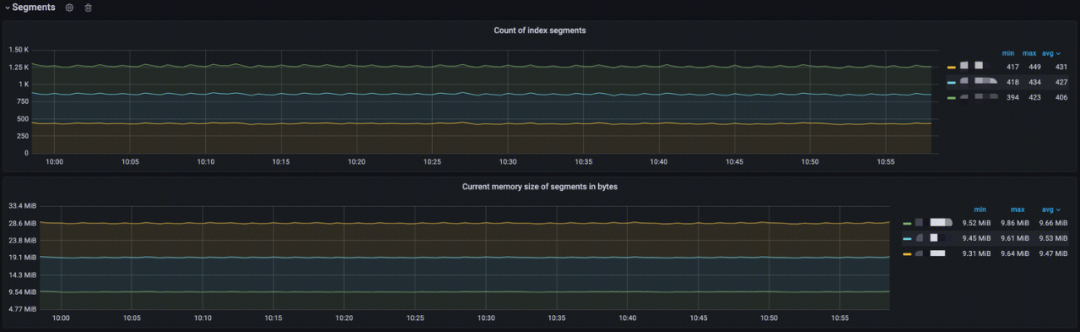
-
Documents count on node:分析节点上的索引 Segment 计数;
-
Current memory size of Segments in bytes:分析当前索引 Segment 内存大小。
4. 典型问题场景
4.1 ElasticSearch 查询性能差
非活动状态下资源利用率也很高
-
原因:集群中分片太多,以至于任何查询的执行速度看起来都很慢;
-
排查方法:检查集群大盘中的分片监控,查看分片是否过多;
-
解决方案:减少分片计数,实施冻结索引和/或添加附加节点来实现负载平衡。考虑结合使用 ElasticSearch 中的热/温架构(非常适合基于时间的索引)以及滚动/收缩功能,以高效管理分片计数。要想顺利完成部署,最好先执行适当的容量计划,以帮助确定适合每个搜索用例的最佳分片数。
线程池存在大量的“rejected”
-
原因:查询面向的分片太多,超过了集群中的核心数。这会在搜索线程池中造成排队任务,从而导致搜索拒绝。另一个常见原因是磁盘 I/O 速度慢,导致搜索排队或在某些情况下 CPU 完全饱和;
-
排查方法:查看集群大盘线程池监控中的拒绝率监控,判断是否有大量拒绝;
-
解决方案:创建索引时采用1个主分片:1个副本分片 (1P:1R) 模型。使用索引模板是一个在创建索引时部署此设置的好方法。(ElasticSearch 7.0 或更高版本将默认 1P:1R)。ElasticSearch 5.1 或更高版本支持搜索任务取消,这对于取消任务管理 API 中出现的慢查询任务非常有用。
高 CPU 使用率和索引延迟
-
原因:集群索引量大会影响搜索性能。
-
排查方法:查看索引大盘节点监控中的 CPU 使用率、JVM CPU 使用率监控查看 CPU 利用率,然后通过延时告警中的索引耗时面板查看索引延迟状况;
-
解决方案:提高 refresh 间隔 index.refresh_ interval 至30s,通常有助于提高索引性能。这可以确保分片不必因为每1秒默认创建一个新分段而造成工作负载增大。
副本分片增加后延迟增大
-
原因:文件系统缓存没有足够的内存来缓存索引中经常查询的部分。ElasticSearch 的查询缓存实现了 LRU 逐出策略:当缓存变满时,将逐出最近使用最少的数据,以便为新数据让路。
-
排查方法:在分片有增加时,查看索引大盘延时中的查询耗时监控,观察查询延迟是否增大,若有增大,查看索引大盘缓存面板中的查询缓存及查询缓存驱逐监控,缓存变高,驱逐量增大,就是该问题;
-
解决方案:为文件系统缓存留出至少50%的物理 RAM。内存越多,缓存的空间就越大,尤其是当集群遇到 I/O 问题时。假设堆大小已正确配置,任何剩余的可用于文件系统缓存的物理 RAM 都会大大提高搜索性能。除了文件系统缓存,ElasticSearch 还使用查询缓存和请求缓存来提高搜索速度。所有这些缓存都可以使用搜索请求首选项进行优化,以便每次都将某些搜索请求路由到同一组分片,而不是在不同的可用副本之间进行交替。这将更好地利用请求缓存、节点查询缓存和文件系统缓存。
共享资源时利用率高
-
原因:其他进程(例如 Logstash)和 ElasticSearch 本身之间存在资源(CPU 和/或磁盘 I/O)争用。
-
排查方法:查看集群大盘节点监控面板中的 CPU、磁盘、网络等利用率监控,发现持续居高,此时停止第三方应用,就会发现 CPU、磁盘、网络等利用率下降,同时性能提高;
-
解决方案:避免在共享硬件上与其他资源密集型应用程序一起运行 ElasticSearch。
ElasticSearch 索引性能变差的原因同样有很多,具体情况具体分析。
硬件资源不足
-
原因:硬盘速度慢、CPU 负载高、内存不足等会导致写入性能下降;
-
排查方法:查看集群大盘节点监控面板中的 CPU、磁盘、网络等利用率监控,各指标持续居高;
-
解决方案:升级硬件、增加节点或者使用更快的存储设备。
索引设置不当
-
原因:不合理的索引设置,如过多的分片数、不合理的副本数、不适当的刷新间隔等会影响写入性能。分片越多会导致写入变慢,多副本会极大的影响写入吞吐,刷新操作属于代价很高的操作,过于频繁的刷新操作会影响集群整体性能;
-
排查方法:查看集群大盘中的分片大盘,查看分片数、副本数是否过多,判断其合理性;
-
解决方案:优化索引设置,调整分片和副本数量,增大刷新间隔等。
索引压力过大
-
原因:大量的写入请求超过了集群的处理能力,导致写入性能下降;
-
排查方法:查看索引大盘中的 Total Operations rate 查看各类型索引操作速率,通过 Total Operations time 查看各类型索引操作耗时来综合判断写入能力是否达到上限;
-
解决方案:通过水平扩展增加节点、优化写入请求分发策略、使用异步写入等方式缓解写入压力。
索引数据过大
-
原因:索引过大会导致写入性能下降,特别是在硬盘空间不足的情况下;
-
排查方法:查看索引大盘文档监控查看文档总数、文档索引速率、文档删除速率。若文档删除速率为0,则说明索引生命管理周期有问题,存在生命管理周期的情况下文档数和索引速率还是居高,则为考虑索引其他问题;
-
解决方案:定期对索引进行优化、使用索引生命周期管理功能、或者将数据分散到多个索引中。
索引数据热点
-
原因:部分热点数据集中写入会造成部分节点负载过重,而其他节点负载较轻;
-
排查方法:查看集群大盘中的节点监控,查看是否部分节点各类负载较高,其余节点较低;
-
解决方案:重新分片、使用索引别名进行数据迁移、或者调整数据写入策略。
共享资源时利用率高
5. 监控系统搭建
1. 自建需要安装并配置 Prometheus、Grafana、AlertManager 、Exportor 等,过程复杂,周期冗长;
2. 配置复杂,需要配置 Exporter 和服务发现等来监控 ElasticSearch 集群;
3. 开源 Grafana 大盘不够专业,缺少结合 ElasticSearch 原理/特征和最佳实践进行深入优化;
4. 告警配置复杂,且告警系统需要自主搭建,提高复杂度;
5. 需要定期更新和维护 Prometheus 及其相关组件,以确保其正常运行和监控效果。
| 自建Prometheus | 腾讯云可观测平台 Prometheus监控 |
|
|---|---|---|
| 成本 | 需自行配置和部署Prometheus及相关组件,采集组件需要自行扩缩容,运维成本高 | 开箱即用的Prometheus+Grafana+告警中心一体化平台,全托管,免运维 |
| 服务发现 | 自行配置,维护成本高 | 图形界面可直接选择需要上报的指标,大大降低维护复杂度 |
| Grafana大盘 | 开源大盘信息较少,无法有效排查问题 | 专业的 ElasticSearch 监控大盘,方便用户快速定位问题及性能优化 |
| 告警 | 需要用户自行部署告警相关内容,且配置较为复杂 | 提供告警平台,同时提供清晰界面进行告警配置,简化操作 |
0 条评论