搜索相关性主要指衡量Query和Doc的匹配程度,是信息检索的核心基础任务之一,也是商业搜索引擎的体验优劣最朴素的评价维度之一。本文主要介绍团队在相关性系统、算法方面的实践经历,特别是在看点搜索、搜狗搜索两个大型系统融合过程中,在系统融合、算法融合、算法突破方面的一些实践经验,希望对搜索算法、以及相关领域内的同学有所帮助及启发。
1、前言
搜索相关性主要指衡量Query和Doc的匹配程度,是信息检索的核心基础任务之一,也是商业搜索引擎的体验优劣最朴素的评价维度之一。本文主要介绍QQ浏览器搜索相关性团队,在相关性系统、算法方面的实践经历,特别是在QQ浏览器·搜索、搜狗搜索两个大型系统融合过程中,在系统融合、算法融合、算法突破方面的一些实践经验,希望对搜索算法、以及相关领域内的同学有所帮助及启发。
2、业务介绍
搜索业务是QQ浏览器的核心功能之一,每天服务于亿万网民的查询检索,为用户提供信息查询服务,区别于一些垂直领域的站内搜索,从索引规模、索引丰富度来看,QQ浏览器的搜索业务可以定位成综合型的全网搜索引擎。具体来说,检索结果的类型,不仅包含传统Web网页、Web图片,也包含新型富媒体形态,例如小程序、微信公众号文章、视频四宫格卡片、智能问答等移动互联网生态下的新型富媒体资源。
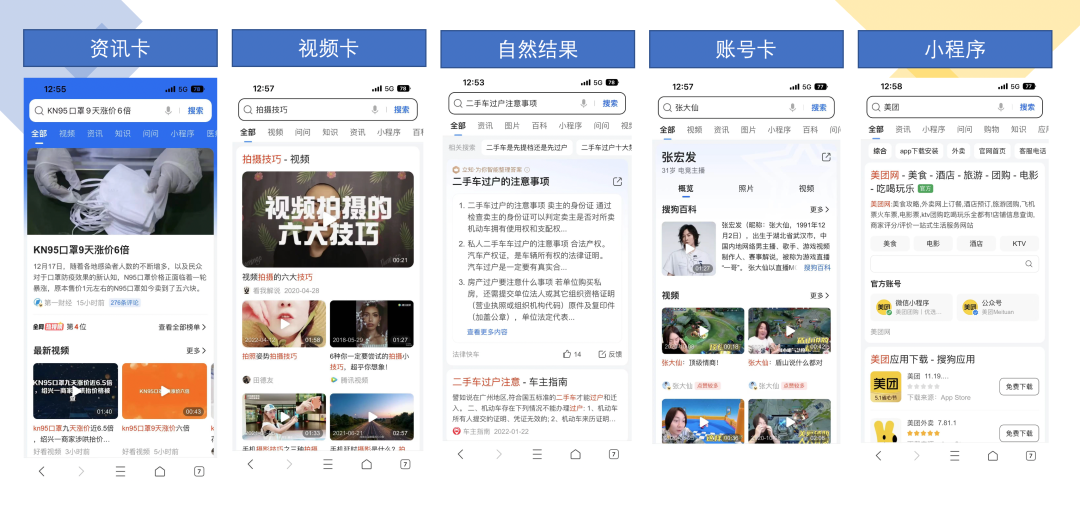
从相关性的视角看,QQ浏览器的业务场景,既包含传统综合搜索引擎的基本特点,即承接不同群体、不同兴趣、不同地域的海量用户的查询Query。从需求角度来看,QQ浏览器的搜索业务有着大量的用户主动查询,其需求种类、表达形式、结果偏好,存在非常大的差异性,对系统的检索、Query理解、相关性判别有着巨大的挑战;同时,从资源类型角度看,依托集团自有的生态优势,QQ浏览器的搜索场景包含海量的新形态的内容搜索,例如微信公众号文章、企鹅号图文、企鹅号视频,这些资源与传统网页在内容表述、内容形式上与传统网页有着较大的区别,也对相关性算法提出了新的要求。

3、搜索相关性介绍
A、搜索主体框架
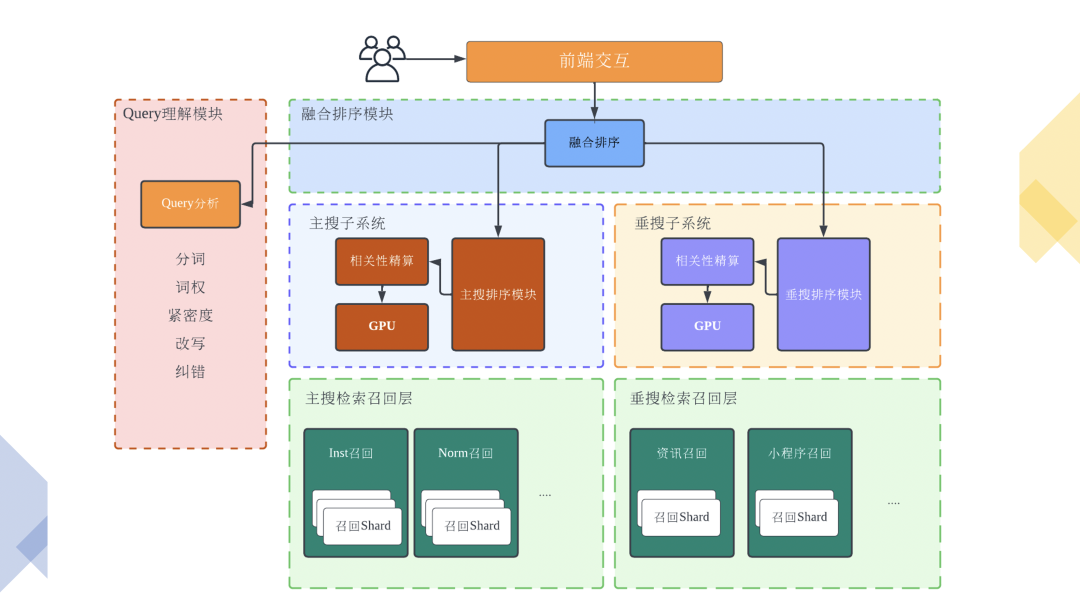
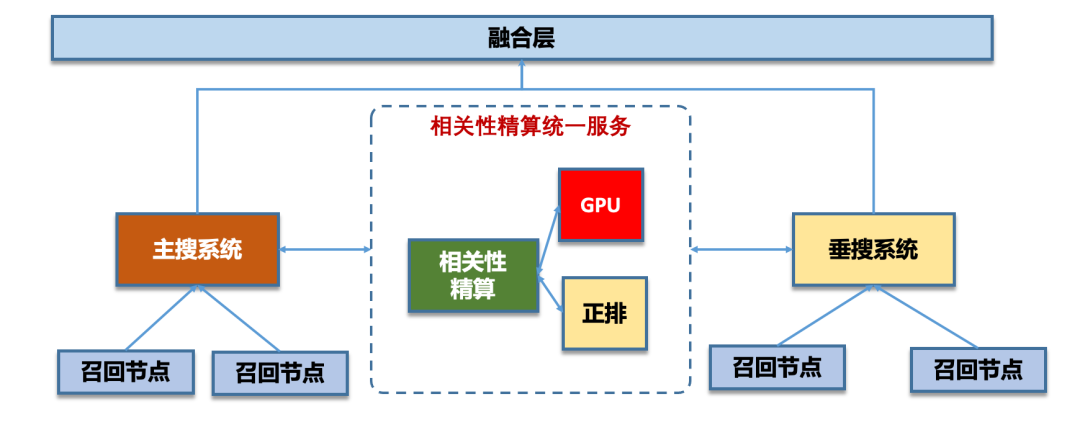
在介绍相关性实践前,首先介绍下系统当前的现状,我们于2021年完成了看点、搜狗两套系统的系统级融合,经过不断地思考、讨论、推演、演化后,整体系统的整体最终演化为如图所示的样子(示意图)。在整个系统融合的过程中,整个团队进行了充分的人员、技术融合,同时也进行了相当长时间的系统改造。系统从逻辑上分为了两大搜索子系统,即主搜子系统和通用垂搜子系统,分别由搜狗系统、看点系统演化而来,同时在系统顶层将两个子系统结果进行进一步融合排序,最终输出检索结果。具体来说分位,分位三个逻辑层次:
● 融合系统:对自然结果、垂搜特型结果(卡片)进行整页异构排序,包含点击预估、异构多目标排序等阶段,同时也会进行一些业务顶层的轻量重排序或微调。
● 通用垂搜子系统:垂搜检索系统由看点搜索系统演化而来,主要用于对接入对高速迭代、快速部署有很高要求,与通用检索逻辑有较大差别的业务。整体系统的特点是部署便捷、快速,这套系统从设计之初就充分考虑了多业务快速接入的场景,目前承接的主要是特型形态的结果。
● 主搜子系统:对十亿级规模的索引库中,对用户的Query进行检索,一般会经历召回、精排两个重要阶段。主要的Doc形态是传统Web网页、Web图片、H5形态网页等,这套系统的特点为,业务形态、效果相对稳定、持续,问题类型有相对的共性,适合算法处于稳定器的业务,主要的难点在于满足用户的中长尾需求。
B、算法架构
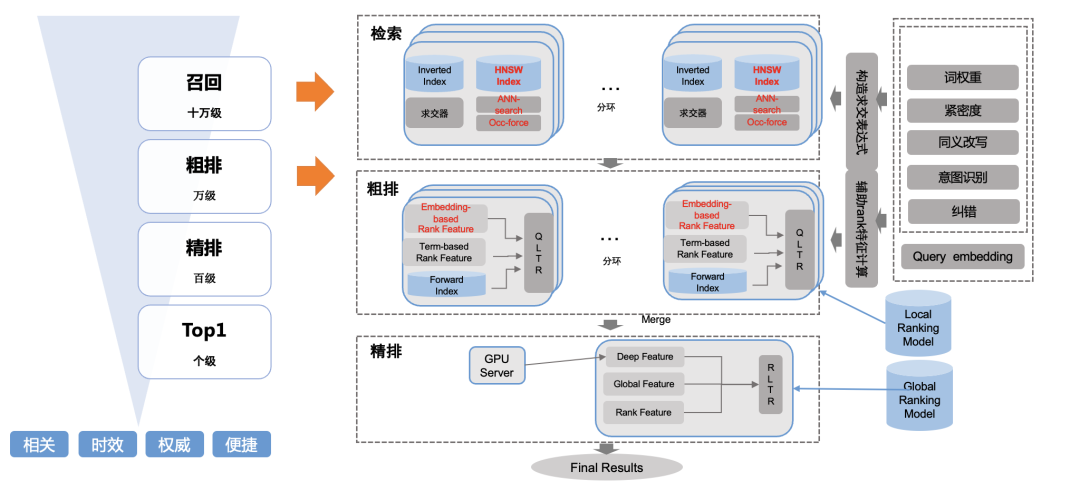
搜索算法的计算流程,大致可以分为召回和排序两大逻辑部分。从算法处理的Doc规模来看,在工业界的一般算法架构,都是类似金字塔型的漏斗结构(QQ浏览器目前的主搜子系统、垂搜子系统,虽然定位不同,但都遵照了上述模式):单个Query会从海量的索引中,检索出一个初始Doc集合,然后经过系统的几个重要的Ranking阶段,逐步对上一个阶段的Doc集合进行筛选,最终筛序出系统认为最好的N条结果。具体来说,如图所以可以分为:
● 召回层:包含文本检索和向量检索两部分,文本检索会按照Query的核心词进行语法树构建,由倒排系统进行Doc归并、截断产出文本召回集合。向量检索部分利用深度模型将Query、Doc映射到隐空间,在线利用向量检索引擎召回与Query相似的N条结果,相比倒排检索能够充分利用PLM对Query和Doc的表示进行学习,实现近似一段式检索,相比传统的召回+粗排的二段式检索有更好的效果。
● 粗排层:粗排层使用计算复杂度相对低的方式进行特征捕捉,基本上分位三类:第一类为相关性类特征,文本相关性、语义相关性,其中语义相关性受限于这个位置的算力,主要采用双塔结构,将Query、Doc表示为向量,用点积或者半交互得到。第二类为Query、Doc的静态特征,例如Query的一些长度、频次、Doc质量、Doc发布时间等。第三类特征为统计类特征,例如历史窗口下的用户行为数据。
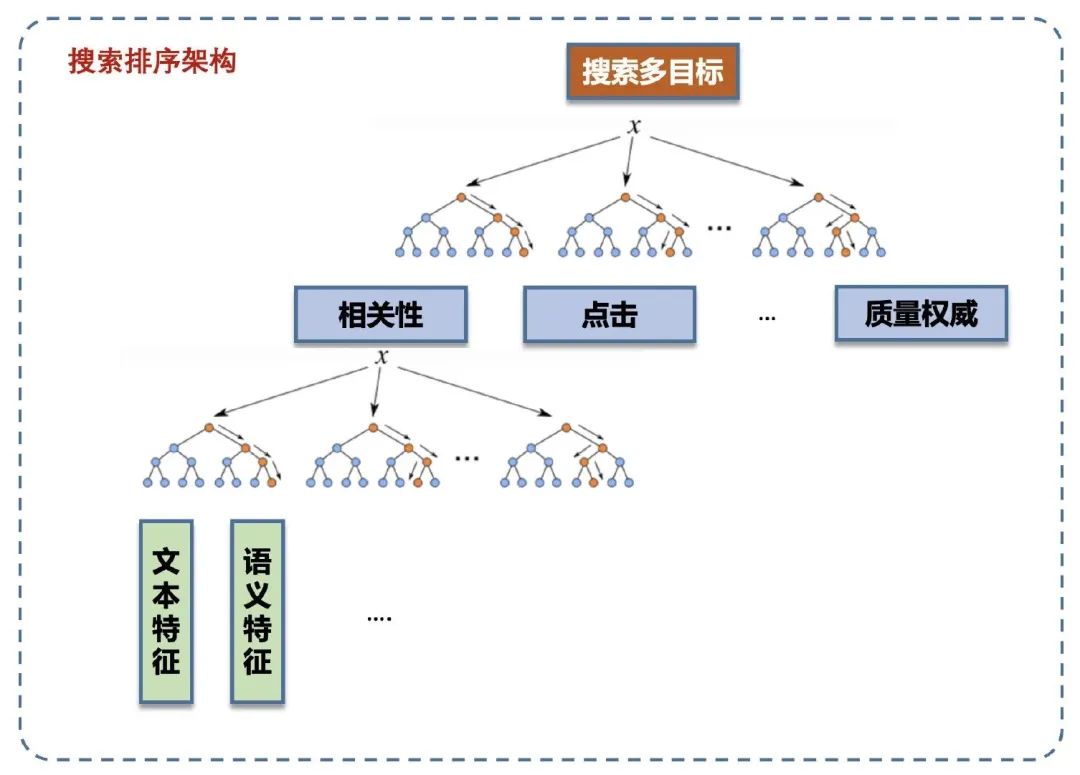
● 精排层:对粗排层输入的Doc集合进行更精细化的区分,按照搜索多目标来,精排层要对Doc以下几个维度进行综合判断,例如相关性、时效性、质量权威性、点击预估等几个维度进行综合考量。
相关性计算的位置:按照上述介绍的算法架构,QQ浏览器的搜索相关性计算主要分为粗排相关性、精排相关性两部分,其中粗排相关性用于在万级别->百级别这个筛选阶段,算法大部分使用基于倒排的文本匹配特征,同时加上双塔结构的语义特征,在计算复杂度相比精排更轻量;精排相关性,主要用于百级别->个级别的筛选,算法相比粗排,利用了Doc的正排数据,建模方式更精细和计算复杂度也相对更高,本文在算法实践方面,会偏向于介绍团队在精算阶段的经验。
C、评估体系
搜索相关性的评估,主要分为离线和在线评估。离线评估主要看重PNR以及DCG的指标变化,在线评估上主要看重interleaving实验以及人工的GSB评估。下面将详介绍几种评估指标的计算方式:
● PNR:Positive-Negative Ratio是一种pairwise的评估手段,用来评估搜索相关性效果。它的物理含义是在一个排序列表中的结果按照query划分,对每个query下的结果进行两两组pair,计算正序pair的数量/逆序pair的数量。值越大说明整个排序列表中正序的比例越多
● DCG:Discounted Cumulative Gain是一种listwise的评估手段。它的物理含义是整个排序相关性,并且越靠前的item收益越高。

其中r(i)代表相关性label。一般而言K选择1或者3.
● interleaving:Interleaving是一种在线评估用户点击偏好的实验。它是将两个排序列表的结果交织在一起曝光给用户,并记录用户最总的点击偏好。整体的感知增益计算逻辑:
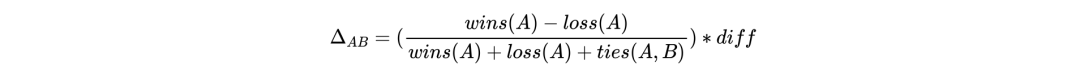
其中 wins代表用户最总点击了A列表结果,ties代表持平,loss则代表落败。
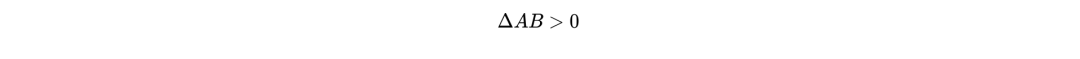
则代表感知增益胜出,反之则代表落败。
● GSB:Good vs Same vs Bad 是一种采用专家评估的手段。标注专家会对左右两边的排序列表进行评估,一边是来自基线线上,一边是来自试验组线上。对于标注专家而言,他不清楚那边的结果是试验组产生的,然后对这两个排序列表进行打分,Good or Same or Bad。最后统计统计整体的GSB指标:(Good-Bad)/(Good + Same +Bad)
4、相关性精算的系统演进
搜狗搜索作为一款历经迭代18年的搜索产品,在数据积累、技术打磨、系统成熟度方面有很强的先天优势;QQ浏览器·搜索是搜索行业较为年轻的新人,在架构选型、技术代际、历史债务方面有很强的后发优势。为了兼顾两家之长,在系统融合的过程中,团队的首要目标就是充分融合两套系统的特有优势。以相关性视角来看,我们大致经历了以下几个改造时期
A、1.0时代,群雄割据 -> 三国争霸
从相关性的视角看,面临最大的难题是两套系统相关性得分不可比的问题。具体来说:
● 标准差异:两套系统的相关性判定标准、标注方法不同,从根本上不可比。
● 建模差异:两个系统对于多目标(相关性、时效性、点击、权威性)的建模方式存在较大差异:主搜系统以End-To-End思路解决搜索多目标的问题,具体来说使用GBDT作为融合模型,所有子特征一并送入融合模型,我们后继称之为「大一统」模型。垂搜系统对多目标进行了进一步的拆解,尽量将同一个维度的特征系列汇聚形成高级特征,以相关性为例,垂搜的会存在一个单独的基础相关性精算阶段,输出相关性高级特征,再将高级特征替换所有的子特征的方式进入融合排序,我们后继称之为「抽象高级特征」。
对比思考:从系统设计上看,「大一统」VS「抽象高级特征」,是两种完全不同的思路,前者更符合机器学习的理念,暴露更多的子特征细节能够提供更多的信息;后者的思路,对目标进行了高度抽象,具有更好的可解释性。从表面看似乎没有明显的优劣可言,但从工业实践经验看,这里还是有较强的实践结论的。
下面揭晓一下结论,从工业系统设计的角度看,更倾向于「抽象高级特征」这种方案,而非「大一统」的方式。理由有以下几点:
● 可解释性:工业算法系统的首要考虑就是如何支撑算法持续、高效迭代。在多目标导向下,「大一统」方式下子特征规模已经达到了100维以上,逆序的问题归因相比「高级特征」来讲,归因难度大、问题会更分散,这个模式也间接鼓励算法同学去新增能够带来指标提升的新特征,而不是去迭代已有的特征。
● 业务需求:「大一统」方式下,一旦脱离该阶段的多目标排序后,后继的更High-Level的融合场景即失去判断相关性的载体,无法对相关性维度进行比较。更High-Level的融合不得不将必要的子特征继续向上传递,往往看到某些子特征从最底层一路透传到最顶层,对子特征的可比性、覆盖率、迭代维护成本都要很大的要求
● 特征管理:High-Level的业务同学大量使用子特征也会造成管理混乱,一旦某些子特征在后继的业务中使用,该特征迭代就与其在后继业务中的形成了耦合,例如比较常见的通过某个特征MagicNumber进行过滤,很有可能的情况是,特征迭代时也要去调整该MagicNumber。所以,以相关性为例,使用具有物理含义的统一「高级特征」会大大减少子特征的管理问题。
改进方式:简单来说,我们在垂搜子系统、主搜系统按照同样的设计思路,抽象了一个基础相关性计算阶段,这个阶段的目标是单目标的相关性,即不考察Doc的质量、时效性等。这一阶段会接管所有刻化相关性目标的特征,通过相关性模型,输出相关性高级特征。同时,相关性高级特征,会经过Probility Calibration算法将score转化为是否相关的概率(对齐标准、档位,跨系统可比),同时具有较好的分布稳定性、跨Query可比性,即具有物理含义的相关性得分。应用视角上看,分位两部分,即交给融合排序模型,替换一批刻化相关性的子特征,另外一部分是直接用于High-Level的场景,例如某些业务会将相关性大于某个阈值的Doc进行过滤或者提权。
演进总结:
● 标准对齐:主要的业务场景,对齐了相关性标准,特别是每个档位物理含义。
● 具有物理含义的相关性得分:对相关性特征进行归纳和融合,通过Probility Calibration算法对得分进行相关概率校准,在ranking任务能力尚可的情况下,能够保证跨Query、跨业务可比,同时从特征管理的角度看,也从特征割据的时代进入了三足鼎立的时代。
B、2.0时代,统一复用
1.0阶段我们通过校准算法、相关性标准统一,输出了具有一定的物理含义相关性得分,可以基本做到子特征保持差异的情况下,基本实现跨业务可比的问题。此时,虽然校准可以解决系统内部的实现上的差异问题,但团队面临更核心问题是系统的近一步融合问题,具体来说:
算法融合:如果说「大一统」「高级特征」两种模式的统一是系统级方法论的对齐,那么「相关性算法融合」角度,则需要近一步将执行细节对齐。如何最大化算法能力,兼两家之长,是最基本的融合初衷。
人效问题:系统细节的差异,算法角度看,在内部的模型、特征体系、数据结构、代码库,全部是完全不同的。维护两套大型复杂系统,分别投入则必须要面对人力折半的问题,背后的压力是可想而知的。
在上述背景下,22年重新对两套系统进行了整合,力图用统一的一套相关性服务,服务于主搜索系统和垂搜系统。这里介绍下我们其中一项重要的重构,重新设计构建了相关性精算服务,统一了主搜系统和垂搜系统的相关性能力,做到90%代码级别的复用。

相关性精算服务:新的相关性精算服务,定位于精算旁路系统,为搜索精排阶段提供高级相关性得分,服务内部可以高速并行获取Doc正排,进行精细化的相关性特征计算、GPU计算、模型预测等。算法统一,一套代码,90%的特征属于通用基础匹配,10%特征根据场景差异,对该业务的独有问题进行独立刻化。具体来看,新的服务相比之前提供的能力包括:
调研实验效率:新的相关性精算服务,调研实验周期由周级下降为天级,背后的效率提升,主要是由于模块位置带来的调研环境搭建成本上的区别。在以前的系统,相关性大部分非GPU类的特征,均在召回层实现,这样带来的问题是,由于召回层的架构大部分都是分布式系统,调研成本相比精算模块需要更多的机器成本,这也造成了该阶段的调研需要团队共用1-2套调研环境,调研&实验成本将会大大增加。

算力能力:相关性分布式计算,最重要的贡献是能够让系统的计算条数变的更多,这种思路在GPU并行技术出现以前是非常有效的设计,将相关性计算放到召回层不仅能够最大限度的利用分布式架构,同时也节省了Doc正排在HighLevel获取的存储和带宽,这部分正排数据往往是召回层必须的可以兼顾复用。但最近几年随着深度学习、GPU并行加速技术在搜索系统重越来越多的应用,业务越来越需要重型计算,这样的重型计算是召回层的算力远远无法满足的,召回层的相关性计算只有基于倒排的特征,更关心是否命中、命中距离,缺少对未命中词与query的关系刻化。
算法独立性:相比之前最大的区别是,新的相关性精算服务,与召回层解耦。从基础数据结构、特包括Query信息、Doc正排,进行重构对齐,传导至特征设计、实现,也能够相应的进行统一。最终做到算法统一,一套代码,90%的特征属于通用基础匹配,10%特征根据场景差异,对该业务的独有问题进行独立刻化。
5、搜索相关性技术实践
5.1 相关性标准
QQ浏览器搜索下的相关性标准,主要用于基础相关性样本的标注,为了能精细化的表达是否相关这一概率,我们将相关、不相关这个二分类任务,拓展到了五档分类,能够提供更多的监督信息。同时,每一档的物理含义,在不同的业务下,尽量保持对等。例如,搜用搜索场景、视频搜索场景下,同一档位的Doc需要具有对等的相关程度,即应具备同一等级的相关性。这样做的好处是,在High-Level场景下,当分类能力尚可的情况下,通过Probility Calibration可以对不同的业务下的doc进行得分的比较,但仍可以对相关性内部特征的实现保留一定的差异性,对系统非常友好。

5.2 相关性的技术架构

5.3 深度语义匹配实践
5.3.1 QQ浏览器搜索相关性的困难与挑战
QQ浏览器的搜索业务每天服务于亿万网民的查询检索,因为业务场景偏向于综合搜索业务,每天的用户的查询表达都呈现海量量级,在这个场景下的用户Query天然的具备很强的长尾效应,对搜索相关性的匹配能力提出了巨大的挑战。

5.3.2 深度语义的现状
为了解决一词多义等模糊表达的问题,QQ浏览器的搜索相关性场景,进行了大量的语义匹配工作实践。随着深度学习技术的兴起,基于预训练语言模型的方法,特别是基于BERT模型的语义匹配,目前是我们工作的主要研究方向。当前系统按照表达方式来看,主要包括基于表示的匹配方法(Representation-based)和基于交互的匹配方法(Interaction-based)。
基于表示的匹配方法:使用深度模型分别学习Query和Doc的Embbeding,在线通过cosine计算Query和Doc相似度来作为语义匹配分数。计算框架上,借鉴百度的SimNet双塔结构,由于在线计算相对交互式模型更友好,目前普遍应用于粗排语义相关性的计算。
基于交互的匹配方法:将Query和Doc(Title)拼接后输入给BERT模型,经过N层Transformer Block后,将CLS Token的Embbeding接入下游相关性任务,由于交互式普遍需要比较高的计算复杂度,一般用于QQ浏览器的精排阶段。

5.3.2 QQ浏览器搜索相关性深度语义实践
A、 相关性Ranking Loss
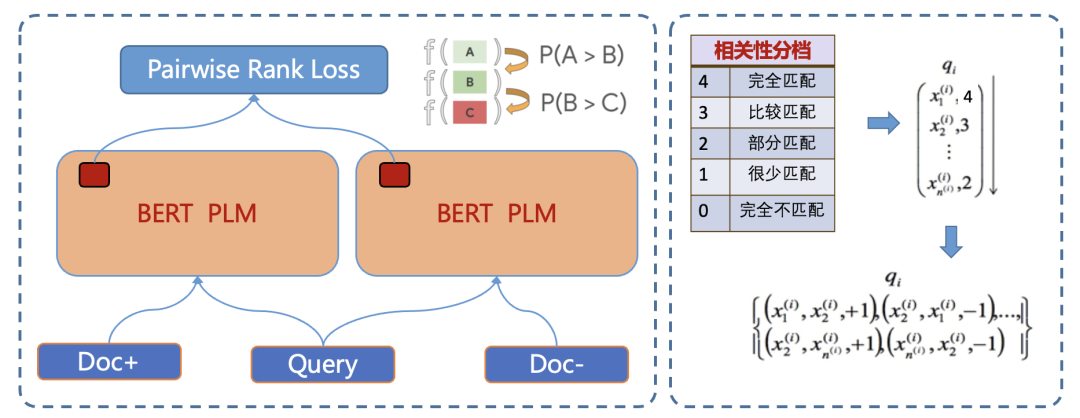
目前我们的相关性标注标准共分为五个档位,最直接的建模方式,其实是进行N=5的N分类任务,即使用Pointwise的方式建模。搜索场景下,我们其实并不关心分类能力的好坏,而更关心不同样本之前的偏序关系,例如对于同一个Query的两个相关结果DocA和DocB,Pointwise模型只能判断出两者都与Query相关,无法区分DocA和DocB相关性程度。因此搜索领域的任务,更多更广泛的建模思路是将其视为一个文档排序场景,广泛使用Leaning To Rank思想进行业务场景建模。
Pairwise 方法通过考虑两两文档之间的相关对顺序来进行排序,相比 Pointwise 方法有明显改善,因此我们对BERT模型的Fine-tuning任务,也进行了RankingLoss的针对性改进。Pairwise Loss下的训练框架,任务输入的单条样本为三元组的形式,在多档标注下,我们对于同一Query的多个候选Doc,选择任意一个高档位Doc和一个低档位Doc组合成三元组作为输入样本。
B、深度语义特征的校准问题
Ranking Loss的问题:相关性是搜索排序的基础能力,在整个计算流程的视角看,相关性计算不是最后一个阶段,所以当相关性内部子特征的目标如果直接使用RankingLoss,要特别注意与上下游的配合应用,特别要关注单特征的RankingLoss持续减少,是否与整体任务的提升一致。同时,RankLoss由于不具有全局的物理含义,即不同Query下的DocA和DocB的得分是不具有可比性,这直接导致了其作为特征值应用到下游模型时,如果我们使用例如决策树这种基于全局分裂增益来划分阈值的模型,会有一定的损失。
搜索系统,一般为了追求可解释性,往往会将高级特征通过一些解释性较强的模型进行融合。以相关性高级特征的产出过程为例,我们在产出整体的相关性得分时,会使用例如XGB模型对相关性N维子特征进行最终的打分预测,如果此时放大这个打分过程,即当训练好的决策树进行最终模型预测时,当执行到某一个决策树时,会按照特征分裂值判断走左子树还是右子树,这个分裂值就要求该特征在全部Query下都按照此分裂点判断,这里如果当前的特征值域在不同Query下差异很大,在个别Query下的打分准确率一定会大打折扣。
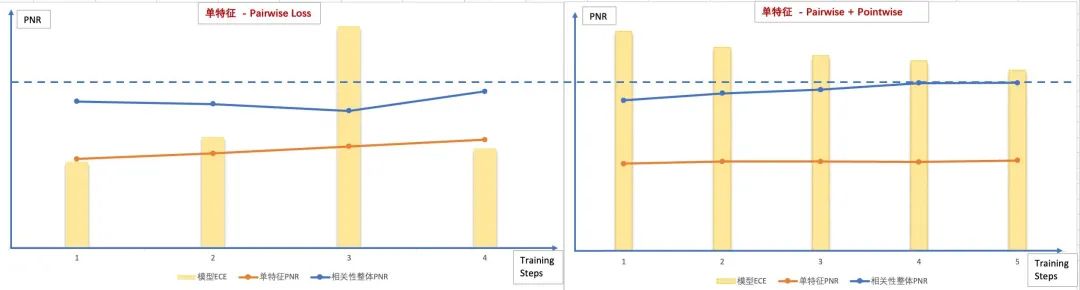
实践中我们对语义特征的ranking loss,也同时进行了一部分pointwise loss结合,目的是希望单特征得分的分布尽量在全局有一定的可比性,即对其进行一定Calibration能够帮助相关性模型整体的PNR提升。由图所示,当单特征持续以PairwiseLoss训练,随着训练步数的增加,单特征PNR是持续上升的,但其放入相关性模型后,整体的PNR并不是线性上升的,此时观察单特征ECE(Expected Calibration Error 期望标定误差)有较大波动;如果将单特征变成Pairwise+PointwiseLoss,发现随着训练过程的进行,模型ECE持续下降,单特征PNR微弱上升,且相关性整体的PNR能够上升,且最终高于单纯使用Pairwise的方式。
C、领域自适应
最近几年的NLP领域,预训练方向可以称得上AI方向的掌上明珠,从模型的参数规模、预训练的方法、多语言多模态等几个方向持续发展,不断地刷新着领域Benchmark。预训练通过自监督学习,从大规模数据中获得与具体任务无关的预训练模型。那么,在搜索领域下,如何将预训练语言模型,与搜索语料更好的结合,是我们团队一直在探索的方向。


在实践过程中,我们发现通用预训练的语料,与搜索场景的任务,依然存在不小的gap,所以一个比较朴素的思想是,是否可以将搜索领域的自有数据进行预训练任务。在实际的实验中,我们发现将搜索领域的语料,在基础预训练模型后,继续进行post-pretrain,能够有效的提升业务效果,对下游任务的提升,最大可以大致9%。
5.4 相关性语义匹配增强实践
5.4.1 深度语义匹配的鲁棒性问题
在NLP领域,预训练语言模型(Pretrained Language Model)已经在很多任务上取得了显著的成绩,PLM搭配领域Finetune也同时在工业界成为解决搜索、推荐等领域的标准范式。在搜索相关性业务中,行业内在2019年开始,就已将神经网络模型全面转为基于Transformer结构的模型结构上来。区别于传统的字面匹配,语言模型能够有效解决Term模糊匹配的问题,但大力出奇迹的同时,也引入了很多核心词缺失等问题。例如,基于预训练语言模型,“二手车”和“二手摩托车”会判定为比较匹配,但实际上二者明显不同。如何解决此类鲁棒性问题,是预训练语言模型下的语义匹配要解决的核心问题。
5.4.2 什么是相关性匹配(RelevanceMatching)
搜索业务下的核心词缺失问题,我们认为传统的预训练方向并不能提供一个统一的解决方案,因为该问题属于搜索领域的特型问题,我们在实际工作中发现,搜索场景下很多形态的问题,与NLP的SemanticMatching任务的差异还是比较明显的,例如短Query和长Title的匹配。对此,我们更倾向于通过对特型问题独立建模和处理,为了强化搜索相关性的鲁棒性,提出了Relevance Matching的概念和对应的建模方式,二者的区别,具体来说:
Relevance Matching:注重关键词的精确匹配,相应的需要考虑核心词的识别、多种维度的要求。(一般需要关注query的重要性以及提取匹配信号,同时形态上Q比较短)
Semantic Matching:注重Term间的相似关系,建模Term、Phrase、Sentence间的相似关系。(偏向query,title表达是不是相似,同时认为query和title的重要性一样)
● 相似度匹配信号 Similarity matching signals:和准确的单词匹配相比,捕获单词、短语和句子的语义相关性/相似性更重要。
● 语义结构 Compositional meanings:语义匹配的文本通过是具有一定语法结构的,使用语义结构的含义会非常有效。
● 全局匹配 Global matching requirement:语义匹配通常将文本的两个片段作为一个整体来推理它们之间的语义关系。
5.4.3 相关性匹配的相关工作
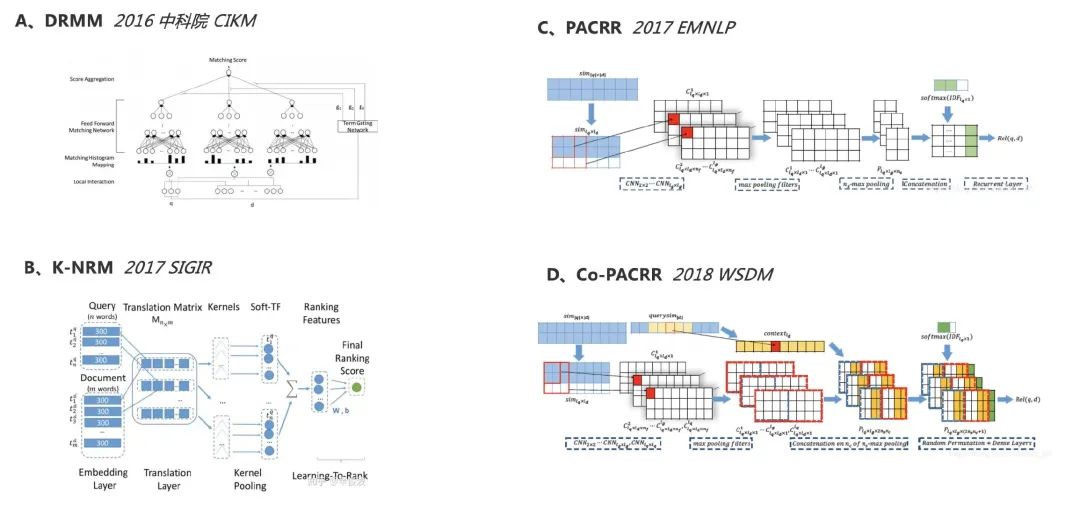
早期的做法:行业内其实很早就有提出Relevance Matching的概念,在Transformer结构以前的主要工作,大多通过对Query和Doc的文本建立匹配矩阵,矩阵中的每一个元素是对应位置的Term相似度,然后再通过对匹配矩阵的命中Pattern进行提取,具体来说:
● MatchPyramid(中科院 2016 AAAI),构建了基于字面匹配或Embedding匹配,构建query-document匹配矩阵,命中提取使用CNN + Dynamic Pooling + MLP完成。
● DRMM (2016 中科院 CIKM),提出了一个交互得模型结构,Query中的每一个Term分别与Doc中的所有的Term交互,将相似度离散到直方图上,通过MLP,以及Q中的Term Gating Network产出得分;其中Term Gating尝试了两种方式,分别是单层FeedForward+softmax和无监督的IDF,实验效果是后者更好。由于Embedding是直接使用的300d word2vec,因此参数量非常小 —— Matching部分有155个参数,Term Gating部分有300个参数。
● K-NRM (2017 SIGIR) ,主要贡献在于提出了RBF Kernel的Pooling方式,与前作最大的不同是,Embedding使用随机初始化并端到端训练的方式,总参数量达到了约5000w(绝大部分来自Embedding层)实验效果显著优于DRMM,其中端到端训练Embedding带来了最大幅度的提升,Kernel Pooling相比基线的pooling方式能带来小幅提升。
● PACRR (2017 EMNLP),主要创新点:在对每一个query term完成pooling后,使用LSTM建模整体的query coverage。LSTM每个timestep的输入是concat(pooling后的query term representation,normalized_IDF)。LSTM的输出维度是1,LSTM的输出直接作为最终的score。
Bert以后的做法:大部分从预训练语言模型的角度,在MASK机制、外部知识引入、参数规模等角度进行研究,也取得了显著的效果提升。但在搜索相关性业务上,大部分交互式的应用方式,是将Query和Title完全拼接后输入Bert,最后在输出层基于CLS这个特殊Token的Embbeding做领域任务。目前我们了解到的是,除了CEDR这个工作外,很少有直接使用非CLS以外的Token的模型架构。这里可能对Transformer比较熟悉的同学会觉得,每一个Transformer Block内部架构其实会天然的对两两Term进行Attention计算,形成多头AttentionMap,与Relevance Matching中的Matrix的设计思路几乎一致,是否还有必要继续再手动进行一次MatrixMatching的计算。对此我们在22年通过一系列实践,证明Relevance Matching的重要意义。

5.4.4 相关性匹配增强
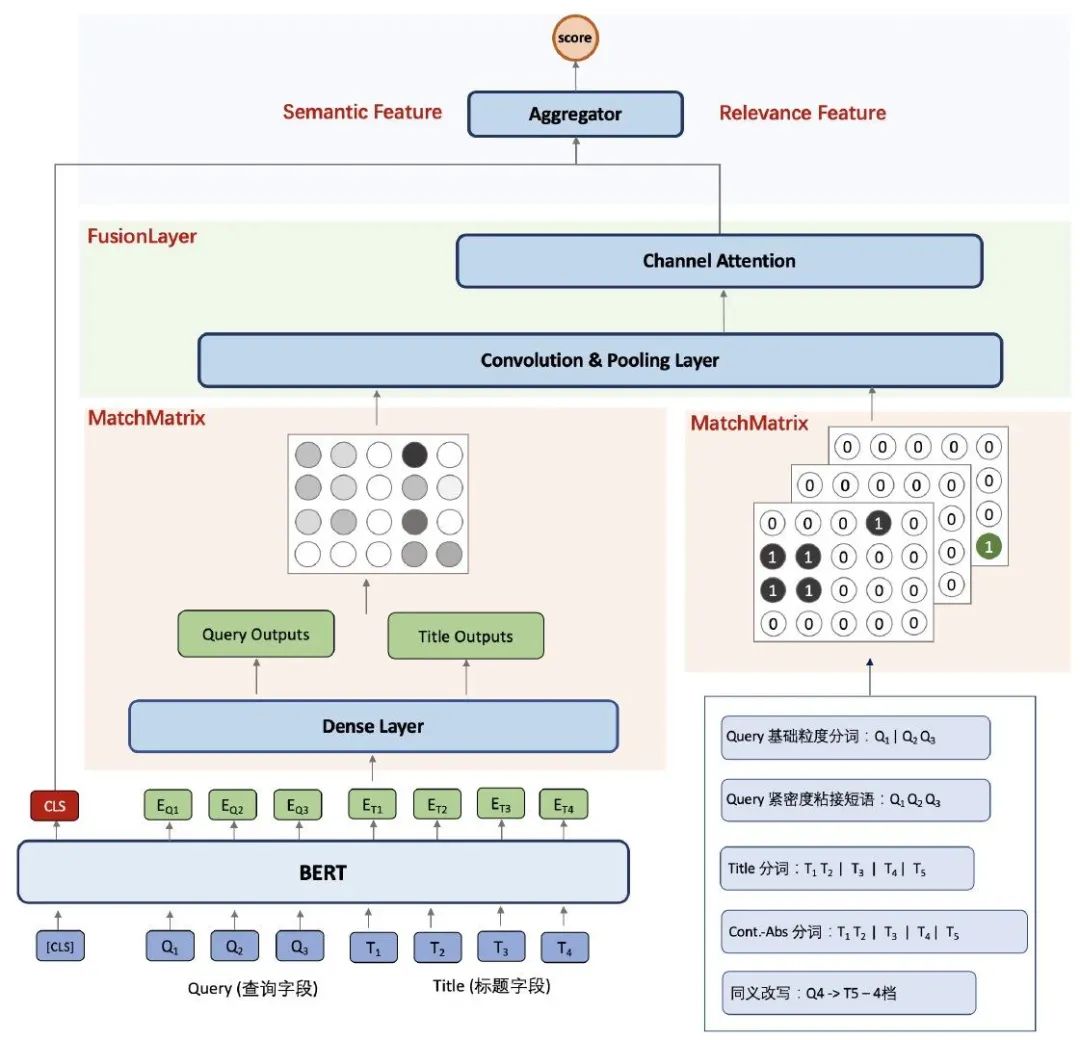
为了兼顾SemanticMatching和RelevanceMatching两者的能力,我们提出了HybridMratrixMatching(HMM)模型,提升模型在核心成分精确匹配和语义泛化匹配两方面的综合能力。具体优化点为:
● Query-Title匹配矩阵建模:
隐式匹配矩阵构造:基于BERT产出的最后一层的token embedding,通过dense + cosine similarity的方式构造Q-T语义匹配矩阵。
显式文本匹配矩阵构造:基于query与title分词后的词粒度命中信息,构造Q-T精确匹配矩阵,并进一步打平映射到与BERT输入信息相同的token粒度。
● 语义匹配与文本匹配信息融合:
CNN汇聚两种匹配矩阵信息:在模型输出层,对隐式和显式匹配矩阵拼接产出N个|Q|x|T|匹配矩阵 ,通过3D-CNN + Weighted Sum Pooling的方式来捕捉语义匹配和Term显式匹配相结合的命中pattern,产出匹配矩阵特征向量。
最终得分融合:将匹配矩阵侧产出的特征向量与BERT CLS特征向量拼接,融合产出最终的模型得分。
5.4.5 实验&效果
为了能够验证Hybrid MratrixMatching(HMM)模型在搜索场景下的匹配能力,我们对模型进行了离线和在线两方面的效果验证。
A、离线实验:
我们对新模型进行了消融实验分析,其中几个比较重要的实验结论为:(1)隐式MatchingMatrix结构,单独进行下游任务预测时,测试集的PNR、NDCG等指标几乎与只用CLS进行下游任务相同 (2)隐式Matrix+CNN后与CLS拼接融合后,整体去做相关性任务,在PNR、NDCG指标上看,相对只用CLS进行下游任务,相对提升大约1.8% (3)外部Matrix的引入,包括多层显示匹配矩阵,能够继续为HMM模型整体的提升带来2.3%的提升。外部匹配Matrix带来的额外信息能够带来效果提升,也证明了精确匹配能力在搜索这个任务中的考核占比是比较高的,将外部精确匹配信号的引入,能够帮助模型强化这部分能力。
B、在线实验:
HMM模型目前已在搜索相关性场景下全量部署,实验期间我们通过ABTest系统和Interleaving系统对实验组效果进行观察,其中Interleaving感知相关性指标在实验期间显著正向,这也与模型升级对精确匹配、核心词命中能力提升等预期比较吻合。同时,我们每次项目实验评估,需要将实验效果送第三方评估团队进行SideBySide评估,由专家标注员对实验组和对照组进行Good、Same、Bad打分,最终随机Query下的送评结果显示,有比较显著的变好趋势。

6、小结与思考
搜索相关性方向,是一个充满了技术挑战的硬核方向,无数网民的检索需求、五花八门的查询表达、越来越新颖的内容模态,全部对系统的效果提出了极其艰巨的挑战。目前QQ浏览器搜索相关性团队的小伙伴们,在搜狗并入腾讯的大背景下,逐步将两套系统的优势合并,完成大量的技术重构、技术债务清理,逐步形成了一个高可用、高性能的业界头部大型搜索系统。接下来,我们将继续在搜索相关性领域持续投入,结合工业界、学术界在NLP领域、AI领域等最前沿的技术突破,为提升业务效果不断努力。
作者:jesangliu,腾讯 PCG 应用研究员
0 条评论