拉卡拉支付成立于 2005 年,是国内领先的第三方支付企业,致力于整合信息科技,服务线下实体,从支付切入,全维度为中小微商户的经营赋能。2011 年成为首批获得《支付业务许可证》企业的一员,2019 年上半年服务商户超过 2100 万家。2019 年 4 月 25 日,登陆创业板。
由于拉卡拉的项目组数量较多,各个项目在建设时,分别根据需要选择了自己的消息系统。这就导致一方面很多系统的业务逻辑和具体的消息系统之间存在耦合,为后续系统维护和升级带来麻烦;另一方面业务团队成员对消息系统的管理和使用水平存在差异,从而使得整体系统服务质量和性能不稳定;此外,同时维护多套系统,物理资源利用率和管理成本都比较高。因此,我们计划建设一套分布式基础消息平台,同时为各个团队提供服务。该平台需要具备以下特性:高可靠、低耦合、租户隔离、易于水平扩展、易于运营维护、统一管理、按需申请使用,同时支持传统的消息队列和流式队列。表 1 展示了这两类服务应该具备的特性。
 表 1. 对消息队列和流式队列的要求
表 1. 对消息队列和流式队列的要求
现在可供用户选择的大厂开源消息平台有很多,架构设计大多类似,比如 Kafka 和 RocketMQ 都采用存储与计算一体的架构,只有 Pulsar 采用存储与计算分离的多层架构。我们比较选型的消息系统有三个:Kafka、RocketMQ 和 Pulsar。测试之前,我们通过网上的公开数据,对三者的性能和功能进行了简单的对比,表 2 为对比结果。从中可以看出 Pulsar 更符合我们的需求。
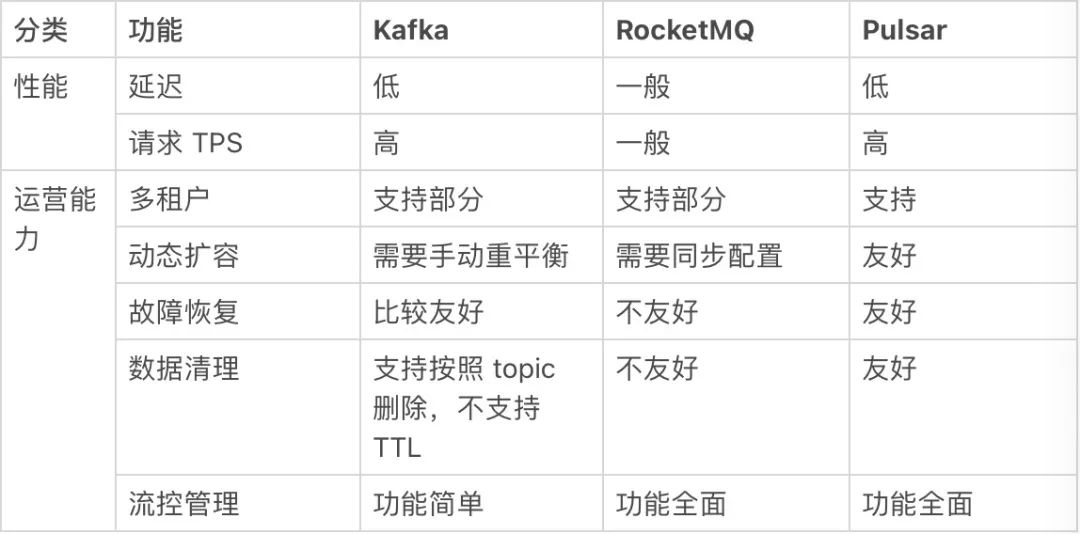 表 2. Kafka、RocketMQ 和 Pulsar 性能、功能对比
表 2. Kafka、RocketMQ 和 Pulsar 性能、功能对比
Pulsar 是云原生的分布式消息流平台,源于 Yahoo!,支持 Yahoo! 应用,服务 140 万个 topic,日处理超过 1000 亿条消息。2016 年 Yahoo! 开源 Pulsar 并将其捐赠给 Apache 软件基金会,2018 年 Pulsar 成为 Apache 软件基金会的顶级项目。
作为一种高性能解决方案,Pulsar 具有以下特性:支持多租户,通过多租户可为每个租户单独设置认证机制、存储配额、隔离策略等;高吞吐、低延迟、高容错;原生支持多集群部署,集群间支持无缝数据复制;高可扩展,能够支撑上百万个 topic;支持多语言客户端,如 Java、Go、Python、C++ 等;支持多种消息订阅模式(独占、共享、灾备、Key_Shared)。
架构合理Kafka 采用计算与存储一体的架构,当 topic 数量较多时,Kafka 的存储机制会导致缓存污染,降低性能。Pulsar 采用计算与存储分离的架构(如图 1)。无状态计算层由一组接收和投递消息的 broker 组成,broker 负责与业务系统进行通信,承担协议转换,序列化和反序列化、选主等功能。有状态存储层由一组 bookie 存储节点组成,可以持久存储消息。

图 1. Pulsar 架构图
Broker 架构
Broker 主要由四个模块组成。我们可以根据实际需求对相应的功能进行二次开发。
-
Dispatcher:调度分发模块,承担协议转换、序列化反序列化等。
-
Load balancer:负载均衡模块,对访问流量进行控制管理。
-
Global replicator:跨集群复制模块,承担异步的跨集群消息同步功能。
-
Service discovery:服务发现模块,为每个 topic 选择无状态的主节点。

图 2. Broker 架构图
持久层(BookKeeper)架构
图 3 为 Pulsar 中持久层的架构图。Bookie 是 BookKeeper 的存储节点,提供独立的存储服务。ZooKeeper 为元数据存储系统,提供服务发现以及元数据管理服务。BookKeeper 架构属于典型的 slave-slave 架构,所有 bookie 节点的角色都是 slave,负责持久化数据,每个节点的处理逻辑都相同;BookKeeper 客户端为 leader 角色,承担协调工作,由于其本身无状态,所以可以快速实现故障转移。
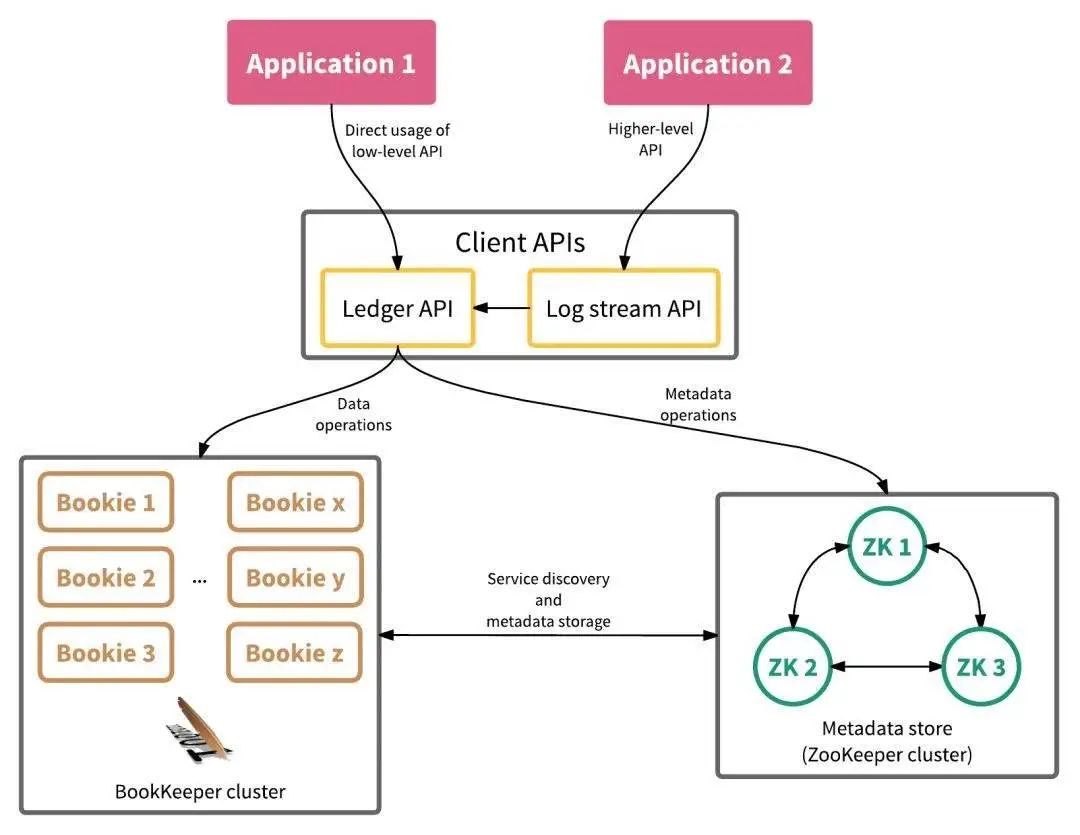
图 3. Pulsar 持久层架构图隔离架构
隔离架构
保证了 Pulsar 的优良性能,主要体现在以下几个方面:
-
IO 隔离:写入、追尾读和追赶读隔离。
-
利用网络流入带宽和磁盘顺序写入的特性实现高吞吐写:传统磁盘在顺序写入时,带宽很高,零散读写导致磁盘带宽降低,采取顺序写入方式可以提升性能。
-
利用网络流出带宽和多个磁盘共同提供的 IOPS 处理能力实现高吞吐读:收到数据后,写到性能较好的 SSD 盘里,进行一级缓存,然后再使用异步线程,将数据写入到传统的 HDD 硬盘中,降低存储成本。
-
利用各级缓存机制实现低延迟投递:生产者发送消息时,将消息写入 broker 缓存中;实时消费时(追尾读),首先从 broker 缓存中读取数据,避免从持久层 bookie 中读取,从而降低投递延迟。读取历史消息(追赶读)场景中,bookie 会将磁盘消息读入 bookie 读缓存中,从而避免每次都读取磁盘数据,降低读取延时。

图 4. Pulsar 隔离架构图
左侧为 Kafka、RabbitMQ 等消息系统采用的架构设计,broker 节点同时负责计算与存储,在某些场景中使用这种架构,可以实现高吞吐;但当 topic 数量增加时,缓存会受到污染,影响性能。
右侧为 Pulsar 的架构,Pulsar 对 broker 进行了拆分,增加了 BookKeeper 持久层,虽然这样会增加系统的设计复杂性,但可以降低系统的耦合性,更易实现扩缩容、故障转移等功能。表 3 总结了分区架构和分片架构的主要特性。

图 5. 分区架构与分片架构对比图
 表 3. 分区架构与分片架构特性
表 3. 分区架构与分片架构特性
基于对 Pulsar 的架构和功能特点,我们对 Pulsar 进行了测试。在操作系统层面使用 NetData 工具进行监控,使用不同大小的数据包和频率进行压测,测试的几个重要指标是磁盘、网络带宽等的波动情况。
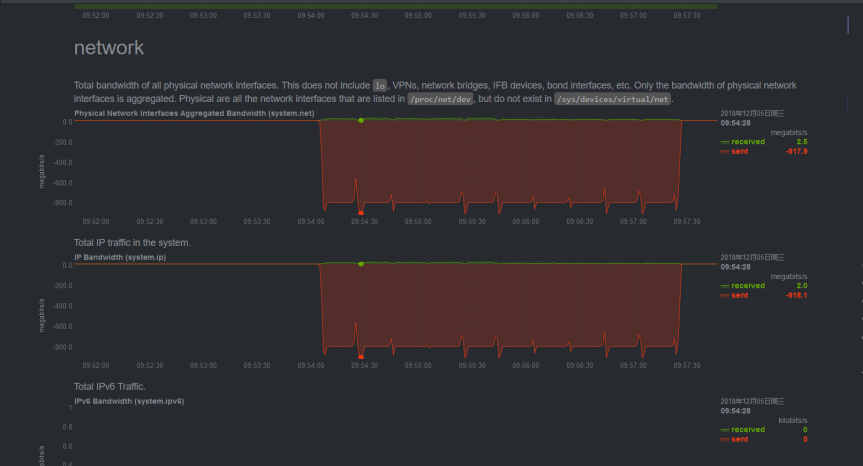
图 6. Pulsar 测试过程
测试结论如下:
-
部署方式:混合部署优于分开部署。broker 和 bookie 可以部署在同一个节点上,也可以分开部署。节点数量较多时,分开部署较好;节点数量较少或对性能要求较高时,将二者部署在同一个节点上较好,可以节省网络带宽,降低延迟。
-
负载大小:随着测试负载的增大,tps 降低,吞吐量稳定。
-
刷盘方式:异步刷盘优于同步刷盘。
-
压缩算法:压缩算法推荐使用 LZ4 方式。我们分别测试了 Pulsar 自带的几种压缩方式,使用 LZ4 压缩算法时,CPU 使用率最低。使用压缩算法可以降低网络带宽使用率,压缩比率为 82%。
-
分区数量:如果单 topic 未达到单节点物理资源上限,建议使用单分区;由于 Pulsar 存储未与分区耦合,可以根据业务发展情况,随时调整分区数量。
-
主题数量:压测过程中,增加 topic 数量,性能不受影响。
-
资源约束:如果网络带宽为千兆,网络会成为性能瓶颈,网络 IO 可以达到 880 MB/s;在网络带宽为万兆时,磁盘会成为瓶颈,磁盘 IO 使用率为 85% 左右。
-
内存与线程:如果使用物理主机,需注意内存与线程数目的比例。默认配置参数为 IO 线程数等于 CPU 核数的 2 倍。这种情况下,实体机核数为 48 核,如果内存设置得较小,比较容易出现 OOM 的问题。
除了上述测试以外,我们还复测了 Jack Vanlightly(RabbitMQ 的测试工程师)的破坏性测试用例,得到如下结论:
-
所有测试场景中,没有出现消息丢失与消息乱序;
-
开启消息去重的场景中,没有出现消息重复。
另外,我们与 Apache Pulsar 项目的核心开发人员交流沟通时间较早,他们在 Yahoo! 和推特有过丰富的实践经验,预备成立公司在全世界范围内推广使用 Pulsar,并且会将中国作为最重要的基地,这为我们的使用提供了强有力的保障。现在大家也都知道,他们成立了 StreamNative 公司,并且已获得多轮融资,队伍也在不断壮大。
我们基于 Pulsar 构建的基础消息平台架构如下图,图中绿色部分为基于 Pulsar 实现的功能或开发的组件。本节将结合实际使用场景,详细介绍我们如何在实际使用场景中应用 Pulsar 及基于 Pulsar 开发的组件。

图 7. 基于 Pulsar 构建的基础消息平台架构图
1. OGG For Pulsar 适配器
源数据存储在 Oracle 中,我们希望实时抓取 Oracle 的变更数据,进行实时计算、数据分析、提供给下游业务系统查询等场景。
我们使用 Oracle 的 OGG(Oracle Golden Gate) 工具进行实时抓取,它包含两个模块:源端 OGG 和目标 OGG。由于 OGG 官方没有提供 Sink 到 Pulsar 的组件,我们根据需要开发了 OGG For Pulsar 组件。下图为数据处理过程图,OGG 会抓取到表中每条记录的增删改操作,并且把每次操作作为一条消息推送给 OGG For Pulsar 组件。OGG For Pulsar 组件会调用 Pulsar 客户端的 producer 接口,进行消息投递。投递过程中,需要严格保证消息顺序。我们使用数据库表的主键作为消息的 key,数据量大时,可以根据 key 对 topic 进行分区,将相同的 key 投递到同一分区,从而保证对数据库表中主键相同的记录所进行的增删改操作有序。
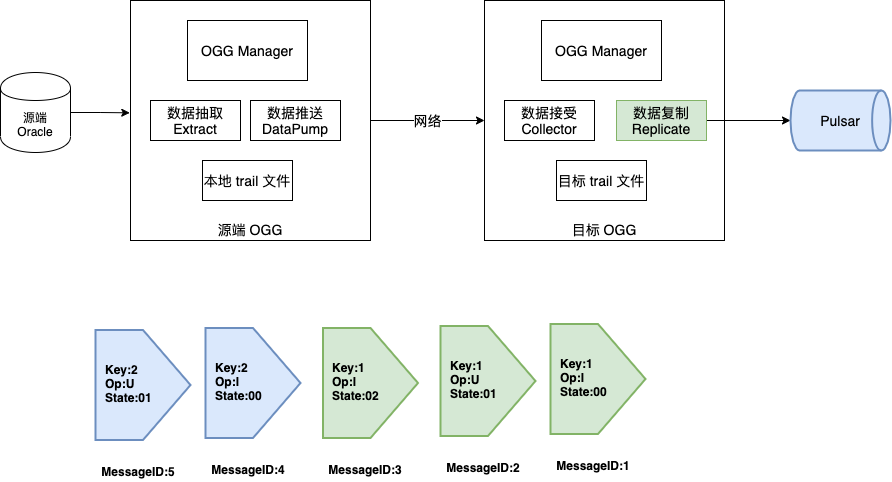
图 8. OGG For Pulsar 组件示意图
2. Pulsar To TiDB 组件
我们通过 Pulsar To TiDB 组件将抓取到的变更消息存储到 TiDB 中,对下游系统提供查询服务。这一组件的处理逻辑为:
-
使用灾备订阅方式,消费 Pulsar 消息。
-
根据消息的 key 进行哈希运算,将相同的 key 散列到同一持久化线程中。
-
启用 Pulsar 的消息去重功能,避免消息重复投递。假设 MessageID2 重复投递,那么数据一致性将被破坏。
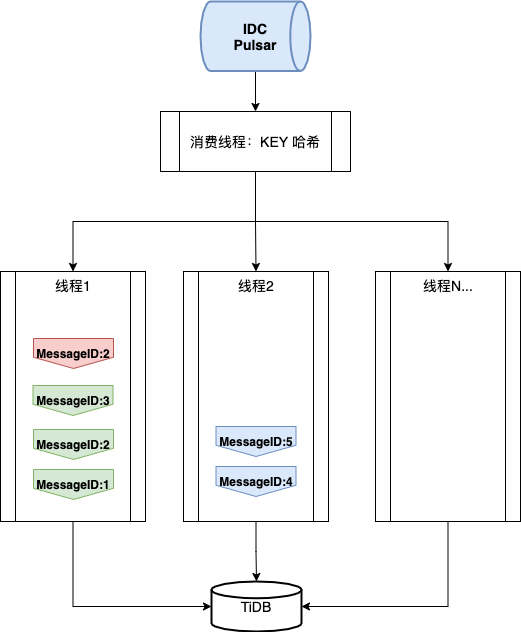
图 9. Pulsar To TiDB 组件使用流程图
3. Pulsar 的消息持久化过程分析
Pulsar 的消息持久化过程包括以下四步:
-
OGG For Pulsar 组件调用 Pulsar 客户端的 producer 接口,投递消息。
-
Pulsar 客户端根据配置文件中的 broker 地址列表,获取其中一个 broker 的地址,然后发送 topic 归属查询服务,获取服务该 topic 的 broker 地址(下图示例中为 broker2)。
-
Pulsar 客户端将消息投递给 Broker2。
-
Broker2 调用 BookKeeper 的客户端做持久化存储,存储策略包括本次存储可选择的 bookie 总数、副本数、成功存储确认回复数。

图 10. Pulsar 的消息持久化示意图
4. 数据库表结构动态传递
OGG 使用 AVRO 方式进行序列化操作时,如果将多个表投递到同一个 topic 中,AVRO Schema 为二级结构:wrapper schema 和 table schema。wrapper schema 结构始终不变,包含 table_name、schema_fingerprint、payload 三部分信息;OGG 在抓取数据时,会感知数据库表结构的变化并通知给 OGG For Pulsar,即表结构决定其 table schema,再由 table schema 生成对应的 schema_fingerprint。
我们将获取到的 table schema 发送并存储在指定的 Schema topic 中。Data topic 中的消息只包含 schema_fingerprint 信息,这样可以降低序列化后消息包的大小。Pulsar To TiDB 启动时,从 Schema topic 消费数据,使用 schema_fingerprint 为 Key 将 table schema 缓存在内存中。反序列化 Data Topic 中的消息时,从缓存中根据 schema_fingerprint 提取 table schema,对 payload 进行反序列化操作。

图 11. 表结构管理流程图
5. 一致性保障
要保证消息有序和去重,需要从 broker、producer、consumer 三方面进行设置。
Broker
-
在 namespace 级别开启去重功能:bin/pulsar-admin namespaces set-deduplication namespace –enable
-
修复 / 优化 Pulsar 客户端死锁问题。2.7.1 版本已修复,详细信息可参考 PR 9552。
Producer
-
pulsar.producer.batchingEnabled=false
在 producer 设置中,关闭批量发送。如果开启批量发送消息,则消息可能会乱序。
-
pulsar.producer.blocklfQueueFull=true
为了提高效率,我们采用异步发送消息,需要开启阻塞队列处理,否则可能会出现消息丢失。调用异步发送超时,发送至异常 topic。如果在异步超时重发消息时,出现消息重复,可以通过开启自动去重功能进行处理;其它情况下出现的消息发送超时,需要单独处理,我们将这些消息存储在异常 topic 中,后续通过对账程序从源库直接获取终态数据。
Consumer
-
实现拦截器:ConsumerInterceptorlmpl implements ConsumerInterceptor
-
配置确认超时:pulsarClient.ackTimeout(3000, TimeUnit.MILLISECONDS).ackTimeoutTickTime(500, TimeUnit.MILLISECONDS)
-
使用累积确认:consumer.acknowledgeCumulative(sendMessageID)
备注:配置确认超时参数,如果没有在 ackTimeout 时间内进行消费确认的话,消息将重新投递。为了严格保证一致性,我们需要使用累计确认方式进行确认。
6. 消息消费的确认方式
假如在 MessageID 为 1 的消息已确认消费成功,开始采用累积确认方式,此时正在确认 MessageID 为 3 的消息,则已消费但未确认的 MessageID 为 2 的消息也会被确认成功。假如在“确认超时”时间内一直未收到确认,则会按照原顺序重新投递 MessageID 为 2、3、4、5 的消息。

图 12. 消息确认流程图(1)
假如采用单条确认方式,图中 MessageID 为 1、3、4 的消息确认消费成功,而 MessageID 为 2 的消息“确认超时”。在这种情况下,如果应用程序处理不当,未按照消费顺序逐条确认,则出现消息“确认超时”时,只有发生超时的消息(即 MessageID 为 2 的消息)会被重新投递,导致消费顺序发生错乱。

图 12. 消息确认流程图(2)
总结:队列消费模式建议使用单条确认方式,流式消费模式建议使用累积确认方式。
7. 消息确认超时(客户端)检测机制
确认超时机制中有两个参数,超时时间和轮询间隔。超时检测机制通过一个双向队列 + 多个 HashSet 实现。HashSet 的个数为(超时时间)除以(轮询间隔)后取整,因此每次轮询处理一个 HashSet,从而有效规避全局锁带来的性能损耗。
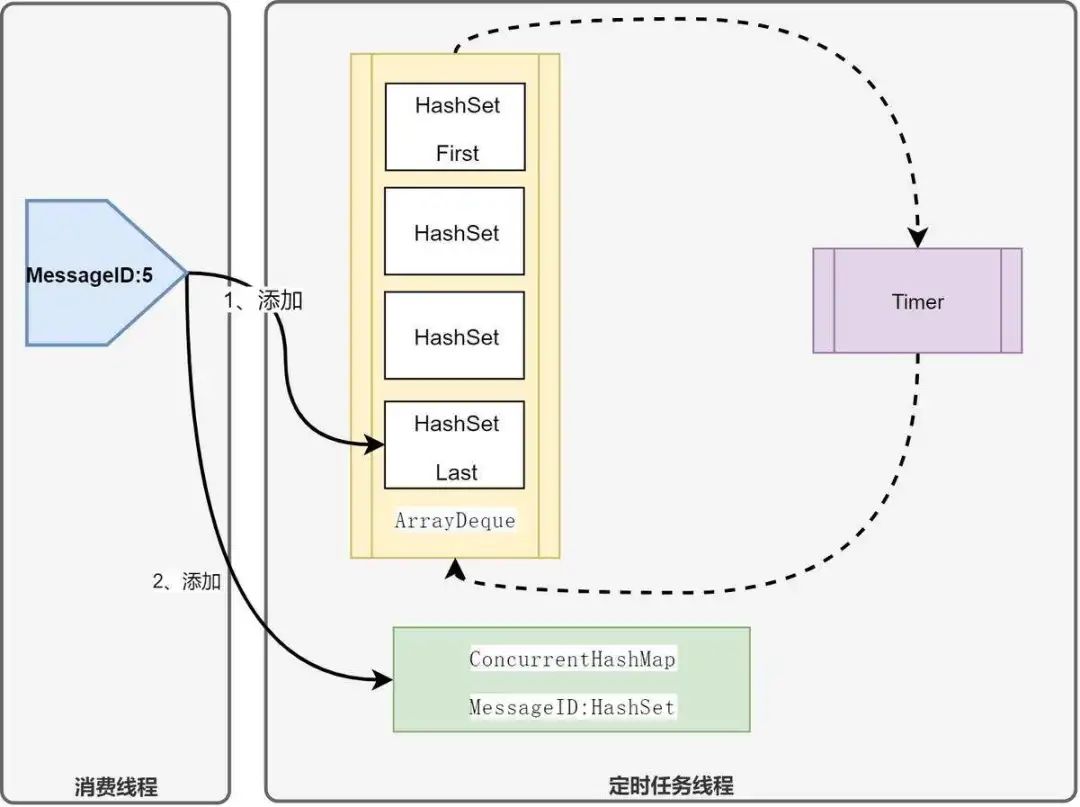
图 13. 消息确认超时(客户端)检测机制示意图
我们过去使用的很多业务系统都和消息系统强耦合,导致后续升级和维护很麻烦,因此我们决定使用 OpenMessaging 协议作为中间层进行解耦。
-
通过 Pulsar 实现 OpenMessaging 协议。
-
开发框架(基于 spring boot)调用 OpenMessaging 协议接口,发送和接收消息。
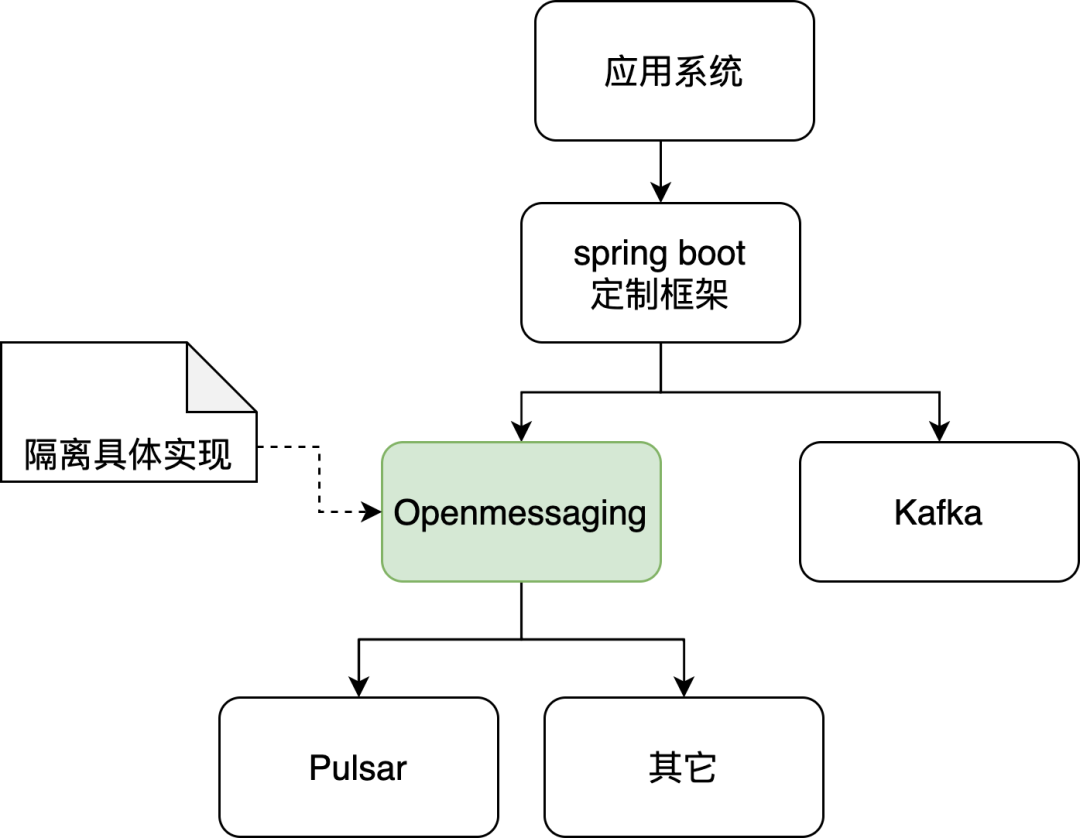
图 14. 透明层协议流程图
Pulsar IO 可以轻松对接到各种数据平台。我们的部分业务系统使用的是 Kafka 0.8,官方没有提供对应的 Source,因此我们根据 Pulsar IO 的接口定义,开发了 Kafka 0.8 Source 组件。

图 15. Kafka 0.8 Source 组件示意图
我们通过 Pulsar Functions 把 Pulsar IDC 集群消息中的敏感字段(比如身份证号,手机号)脱敏后实时同步到云集群中,供云上应用消费。

图 16. Pulsar Functions 消息过滤示意图
商户经营分析场景中,Flink 通过 Pulsar Flink Connector 连接到 Pulsar,对流水数据根据不同维度,进行实时计算,并且将计算结果再通过 Pulsar 持久化到 TiDB 中。从目前的使用情况来看,Pulsar Flink Connector 的性能和稳定性均表现良好。
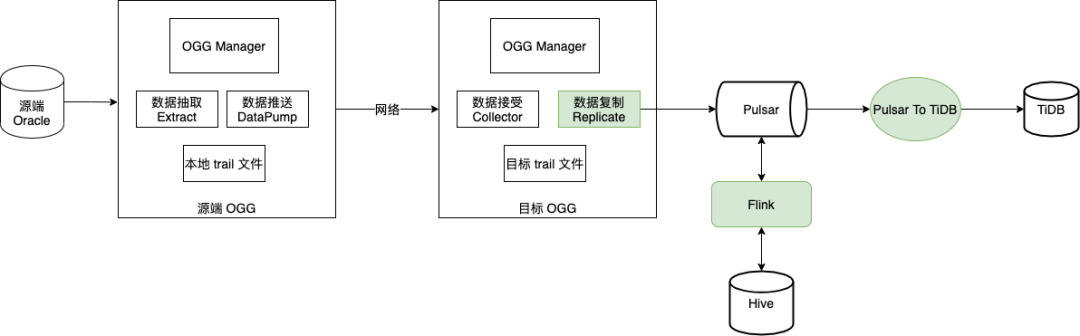
图 17. Pulsar Flink Connector 流式计算示意图
我们需要基于 TiDB 数据变更进行实时抓取,但 TiDB CDC For Pulsar 序列化方式不支持 AVRO 方式,因此我们针对这一使用场景进行了定制化开发,即先封装从 TiDB 发出的数据,再投递到 Pulsar 中。TiDB CDC For Pulsar 组件的开发语言为 Go 语言。

图 18. TiDB CDC For Pulsar 组件示意图
我们基于 Pulsar 构建的基础消息平台有效提高了物理资源的使用效率;使用一套消息平台简化了系统维护和升级等操作,整体服务质量也得以提升。我们对 Pulsar 的未来使用规划主要包括以下两点:
-
陆续下线其它消息系统,最终全部接入到 Pulsar 基础消息平台;
-
深度使用 Pulsar 的资源隔离和流控机制。
在实践过程中,借助 Pulsar 诸多原生特性和基于 Pulsar 开发的组件,新消息平台完美实现了我们预期的功能需求。
作者 | 姜殿璟
0 条评论