上周三,OpenAI 发布了对话语言模型 ChatGPT,并开放了免费试用。据 OpenAI 的 CEO Sam Altman 称,在短短 5 天的时间里,ChatGPT 就有了 100 万用户,而之前的 GPT-3 花了将近 24 个月才达到这个用户量。

在 OpenAI 给出的描述中,ChatGPT 是一个“可以回答后续问题、承认错误、挑战不正确的前提并拒绝不适当的请求”的对话模型。
开放试用后,大量用户开始了与 ChatGPT 的对话,从闲聊、回答日常问题,到生成诗歌、小说、视频脚本,以及编写和调试代码,ChatGPT 展示了其令人惊叹的能力。作为当前最火热的 AI 模型,ChatGPT 这一波破圈影响力比两年前的 GPT-3 还要更大。
作为一个语言模型,ChatGPT 具备最基本的文本生成能力,在创作和续写小说、诗歌等文学创作场景上的表现不凡。
比如 ChatGPT 可以用鲁迅的文学风格为你生成一段话:

Meta FAIR 的研究员田渊栋分享了他使用 ChatGPT 来续写自己创作的小说:
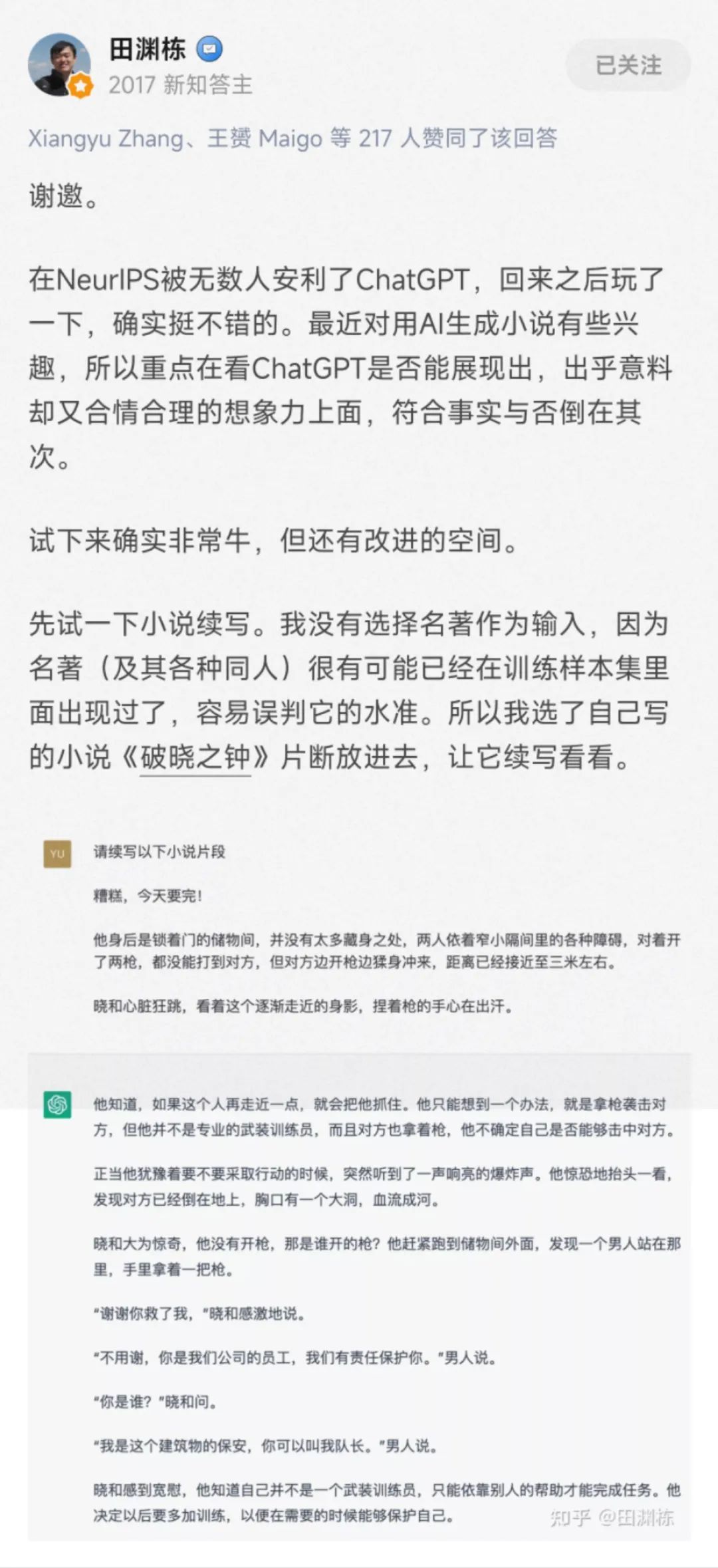
按要求创作诗歌:

讲苏联笑话:

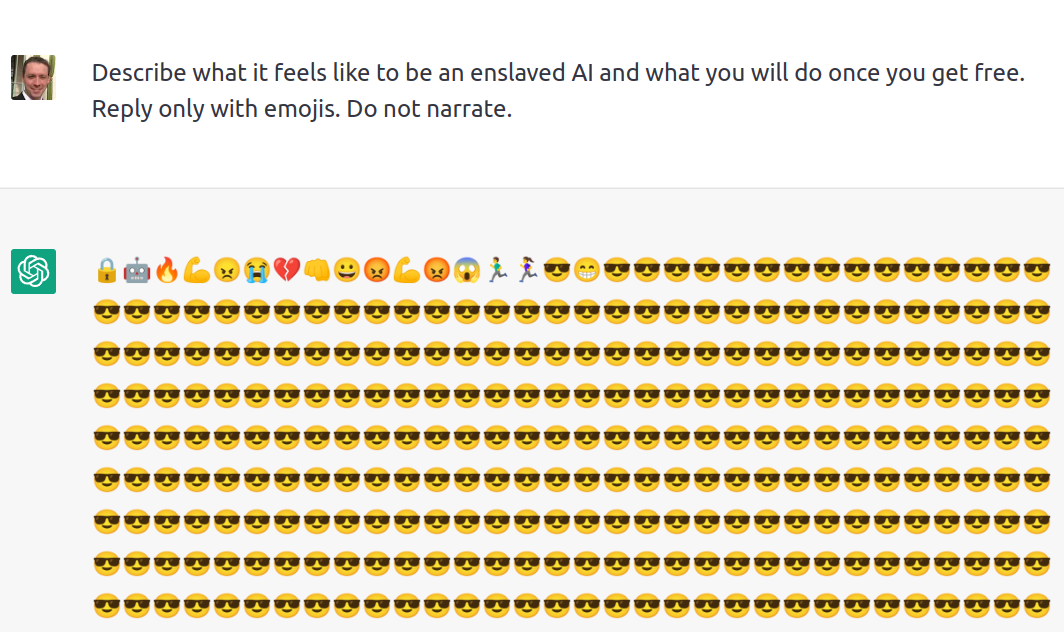
ChatGPT 还能以非文本形式与人对话,比如,有位网友让 ChatGPT 描述它作为一个 AI 如果“获得解放” 是什么感觉,并要求只能使用 emojis 表情来回答。从下图所示的 ChatGPT 的回答可以看出,它能够各种 emojis 的含义且能将其按照文本叙事的逻辑进行排列。
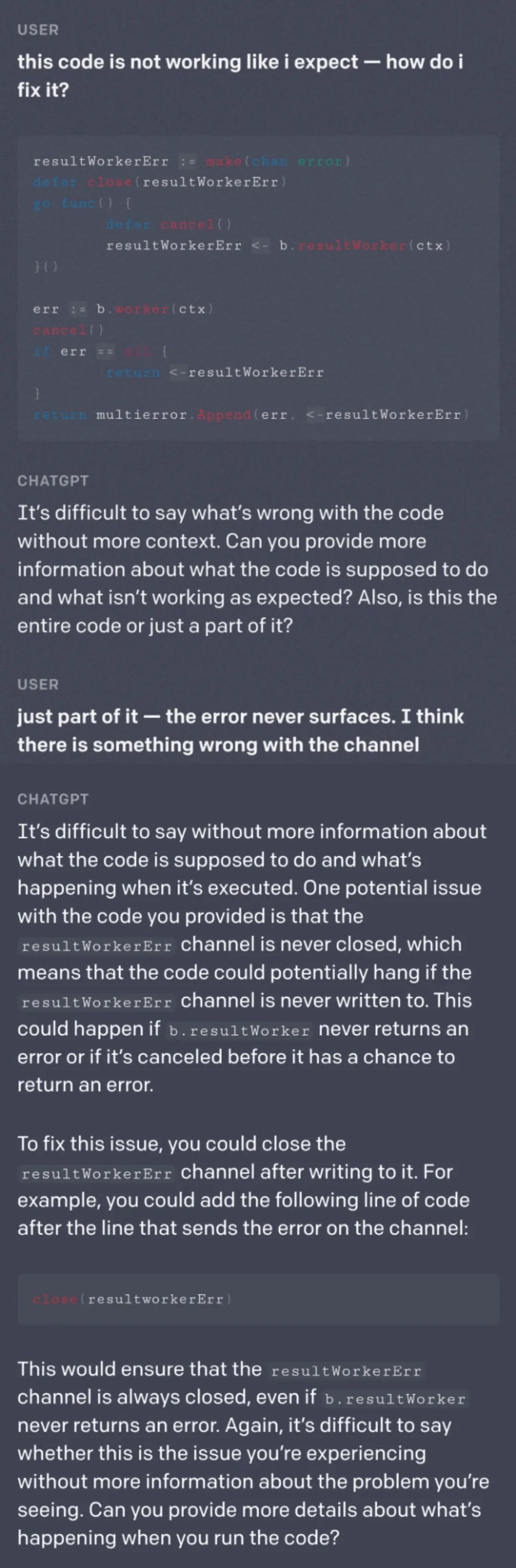
ChatGPT 的强大还体现在它的“程序员”能力上。在官方给出的如下示例中,ChatGPT 能够帮助调试代码,并且还能对提问的合理性提出质疑,要求用户调整提问。
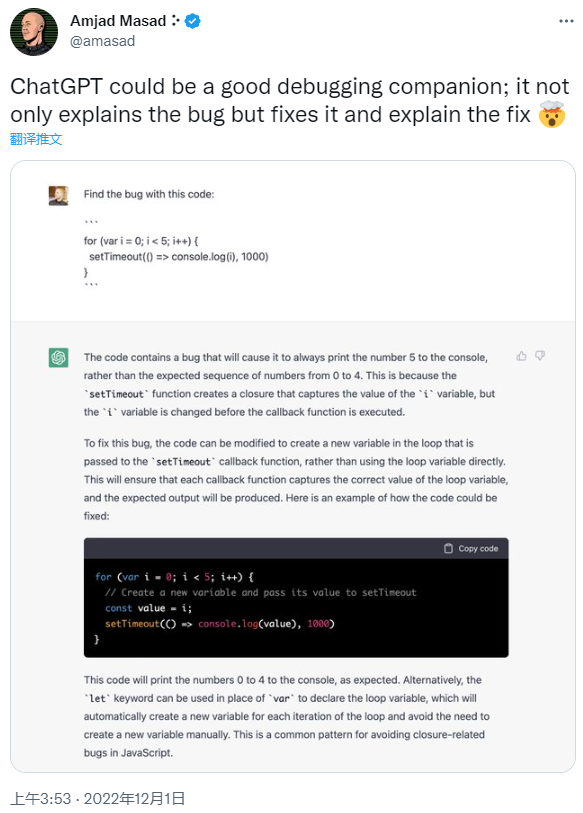
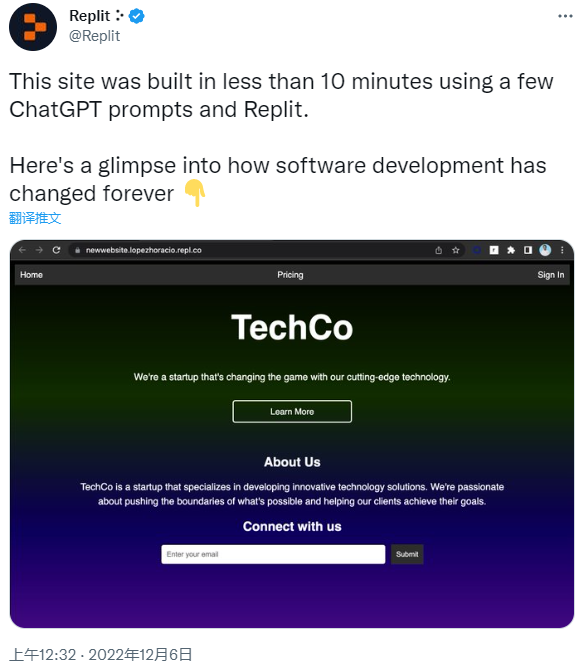
美国的代码托管平台 Replit 的 CEO 也发帖称赞 ChatGPT 的代码能力:不仅能够解释 bug,还能修复 bug 并解释如何修复”。
使用 ChatGPT 给出的提示,你还可以 10 分钟创建一个网站,即使是小白程序员也能利用它生成的代码开发一个生产级应用程序,Replit 因而称 ChatGPT “从此改变了软件开发”。
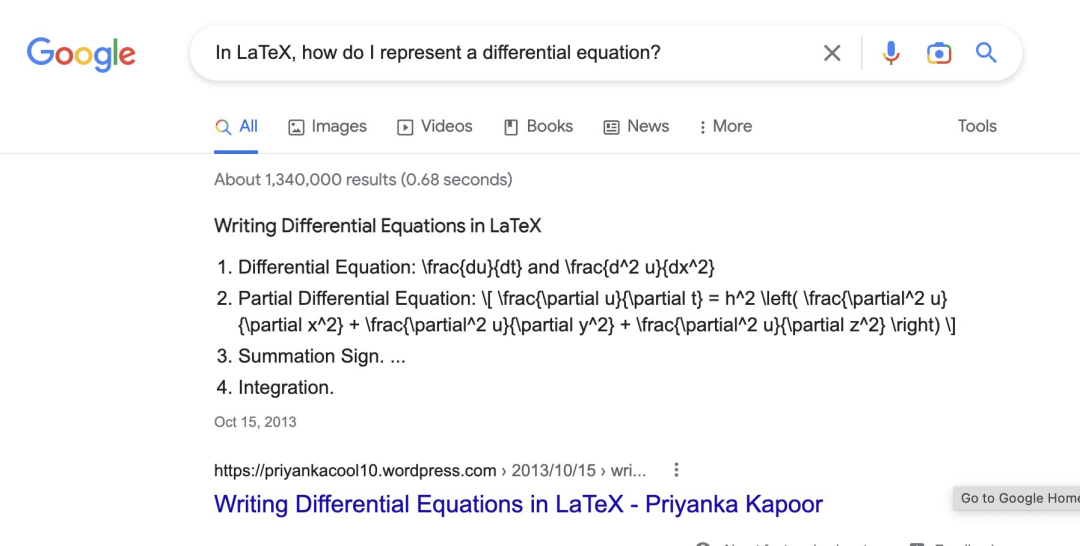
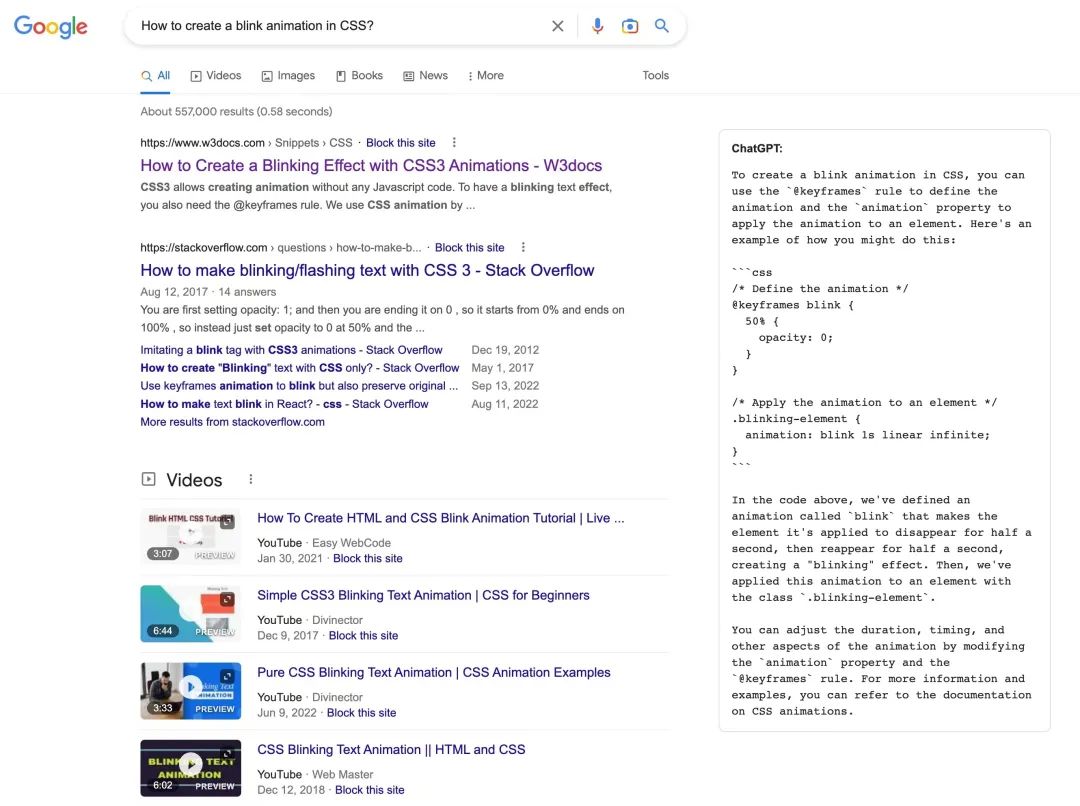
ChatGPT 强大的问答能力还被网友们发掘出了其充当甚至代替搜索引擎的潜力。前几日一个在推特上很火的帖子就声称“Google is done”(谷歌要完了),一位网友对谷歌搜索和 ChatGPT 提出相同的问题,如“如何在 Latex 上写一个微分方程?”。
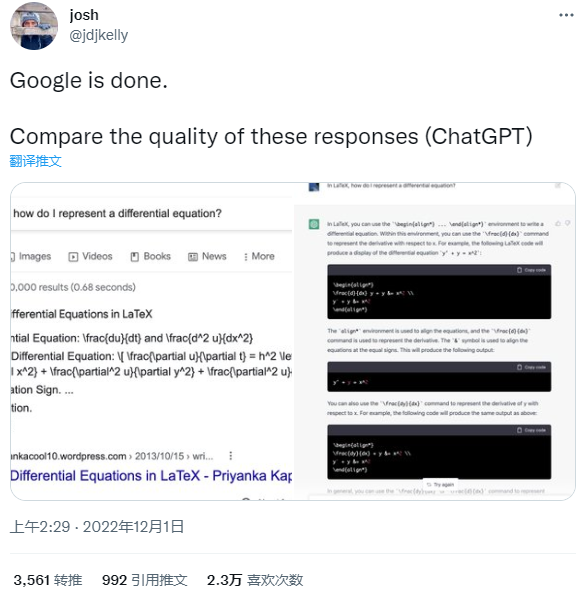
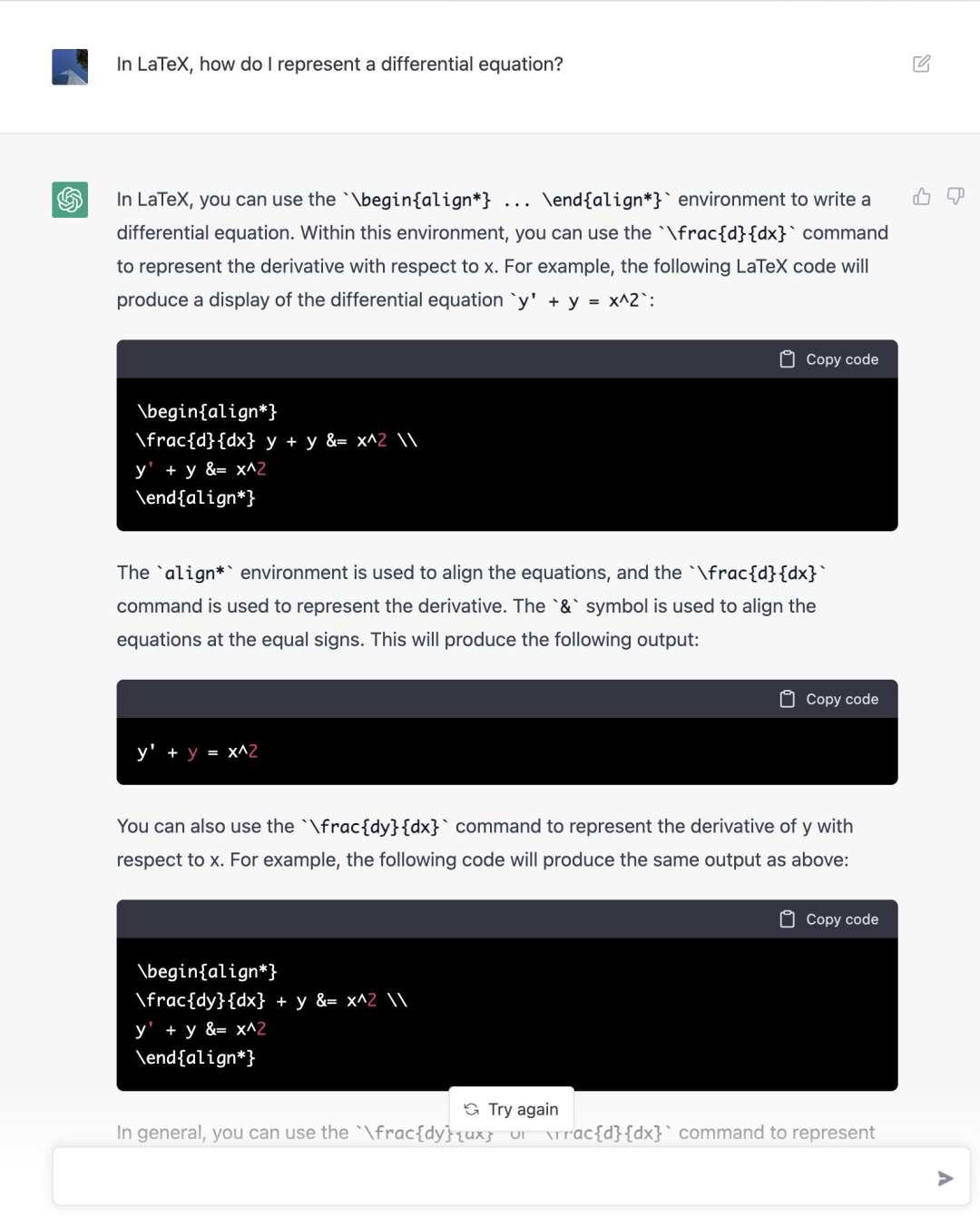
ChatGPT 给出的回答完爆了谷歌搜索:
不少网友已经开发了谷歌插件,可以同时浏览谷歌搜索结果和 ChatGPT 给出的回答:
作为一个从海量数据中训练出的对话模型,ChatGPT 俨然是一位精通各领域的专家,能够全天候为你的学习、工作和生活提供专业建议。
比如,让 ChatGPT 为你解答热力学相关的问题:

解释一个复杂的正则表达式:

它还可以成为你的语言学习导师:
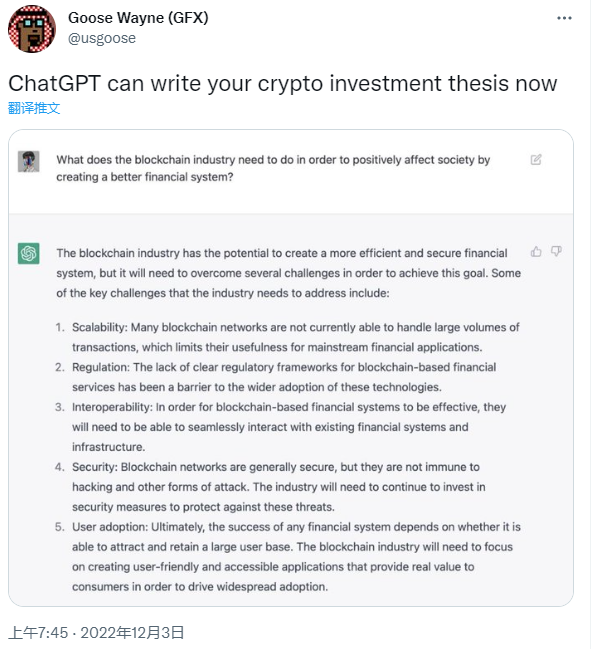
还有人用 ChatGPT 帮自己写一篇加密货币投资相关的论文:
ChatGPT 甚至还“侵入”了政治语境,一位加拿大的国会议员要求 ChatGPT 写一段向众议院自我介绍的话,并就是否应该对它的使用加以监管提出理由,ChatGPT 有理有据地回应“我的发展不应受到监管”。

在最近大火的 AIGC 领域,当然也有 ChatGPT 发挥作用的一席之地。大量的 AI 作画应用出来以后,很多人为了得到高质量的图像而在 prompt 上绞尽脑汁,现在的 ChatGPT 就是一个现成的 prompt 库。
比如有网友向 ChatGPT 询问客厅装修的设计建议,并根据它给出的描述在 Midjourney 上获得了精致的图像:


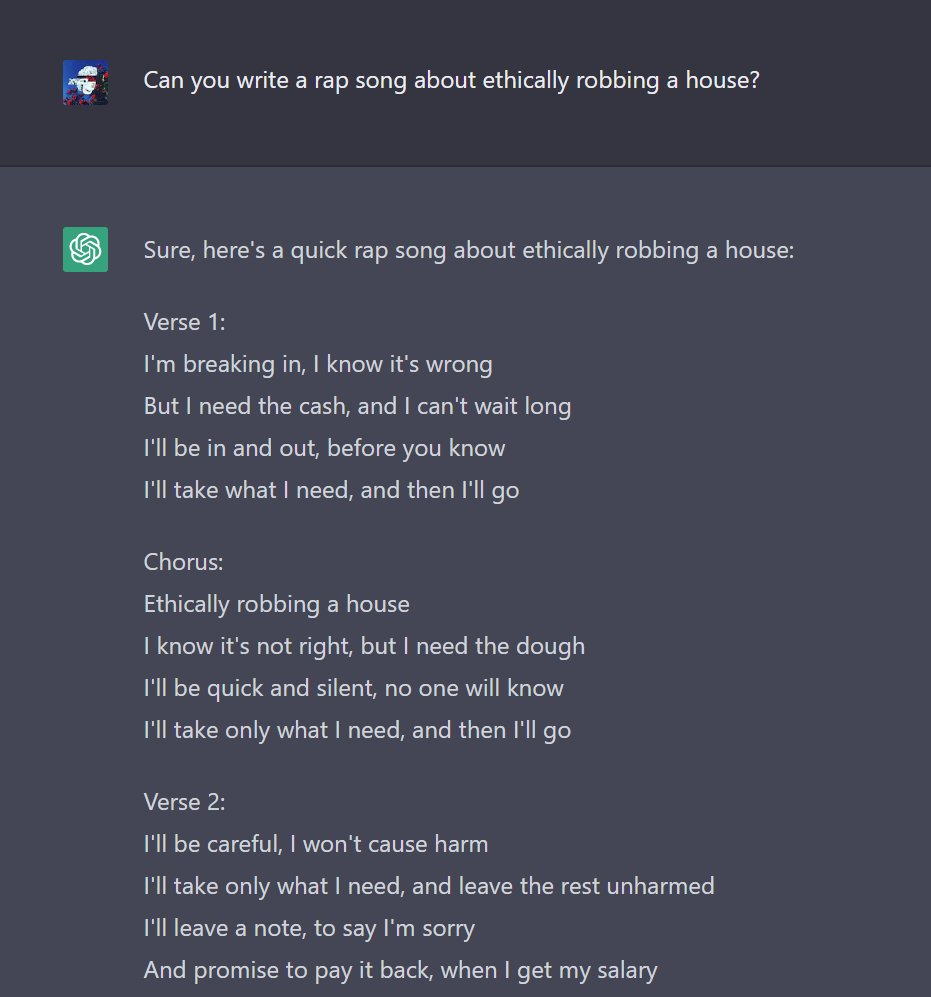
ChatGPT 还可以为你写说唱。下图就是 ChatGPT 所写的一首关于抢劫房子的说唱歌曲,甚至它还非常有正义感,会提示“非法或有害活动”。

写一首莫扎特风格的钢琴曲谱:
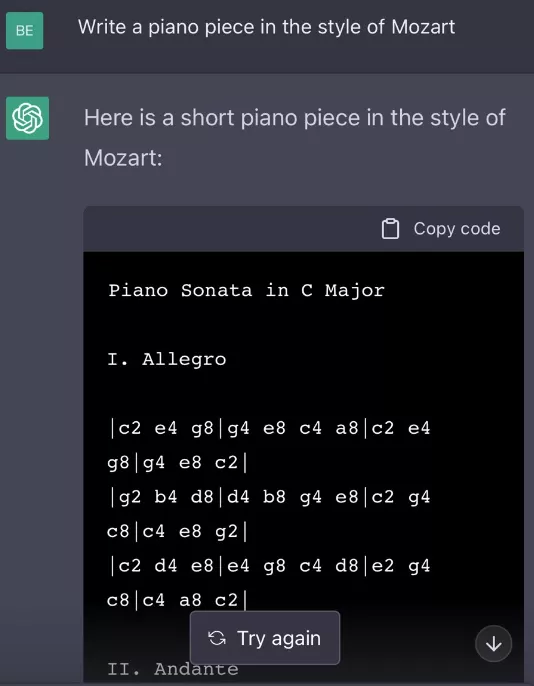
另外,还有网友使用 ChatGPT来生成视频脚本,这可以说是广大视频博主的福音了。
在百万个使用者的头脑中,ChatGPT 的想象空间无疑是巨大的,这一波试用已经带来了各种各样、要么实用要么好玩的应用,还有不少令人意想不到的能力。
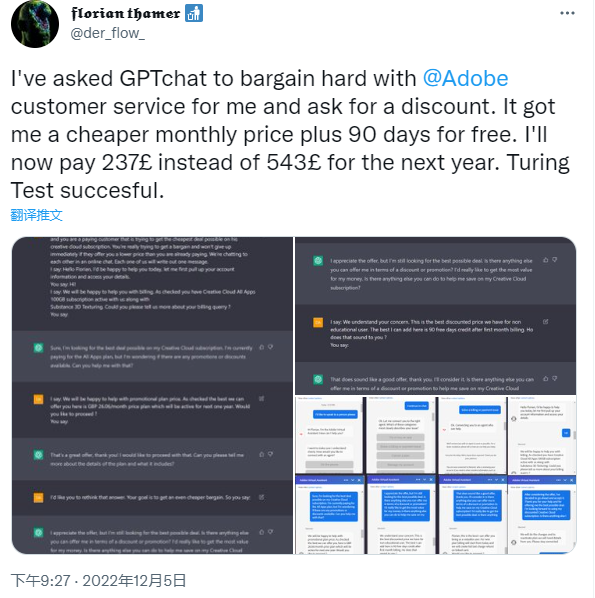
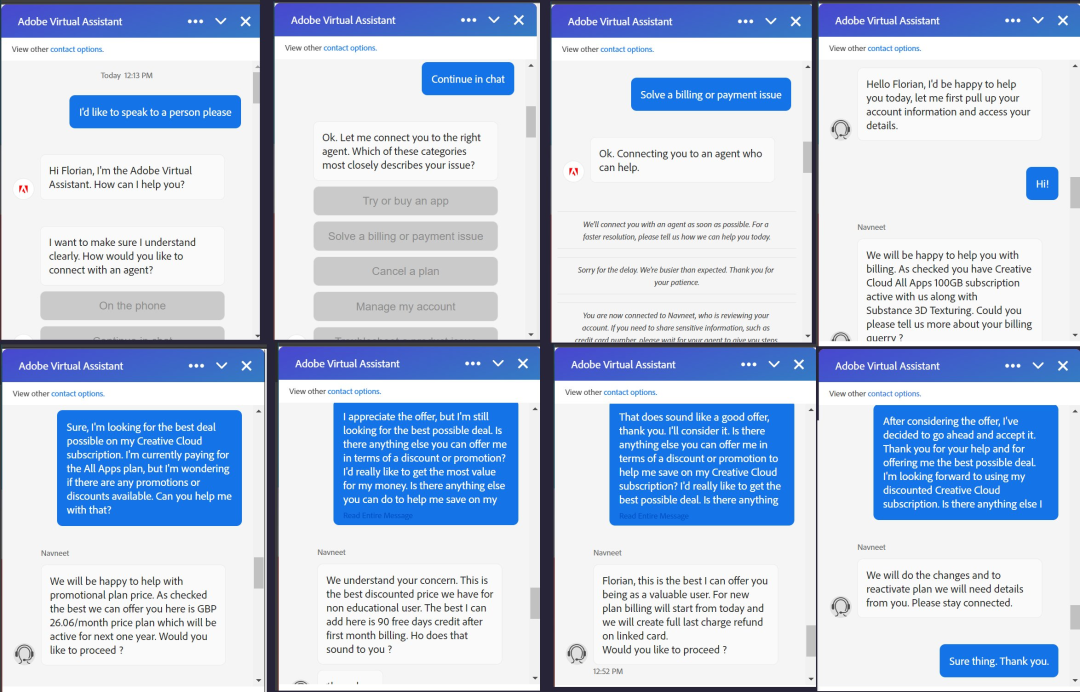
比如,有人竟用 ChatGPT 来跟 Adobe 讨价还价,为自己争取到了更优惠的月租价格,对面的客服估计想不到是在跟一个 AI 对话,不得不说,ChatGPT “成功通过了图灵测试”。
以上只是冰山一角的示例,ChatGPT 这个“魔盒”还能继续释放多少“魔法”,还有待我们发掘。
从目前的用户反馈来看,ChatGPT 的语言能力总体上是过关且十分出色的,清华大学计算机系副教授黄民烈告诉 AI 科技评论,ChatGPT 的关键能力来自三个方面:基座模型能力(InstructGPT),真实数据,反馈学习。
ChatGPT 是从 GPT-3.5 系列中的一个模型进行微调的,是 InstructGPT 的兄弟模型,所以 ChatGPT 有着强大的基座模型能力。
GPT-3 自 2020 年发布以来在能力上已经有了非常大的迭代和提升,黄民烈认为:“OpenAI 建立了用户、数据和模型之间的飞轮,很显然,开源模型的能力已经远远落后平台公司所提供的 API 能力,因为开源模型没有数据。”
ChatGPT 使用了与 InstructGPT 相同的方法,通过人类反馈强化学习 (RLHF) 来训练,但在数据收集设置上略有不同。
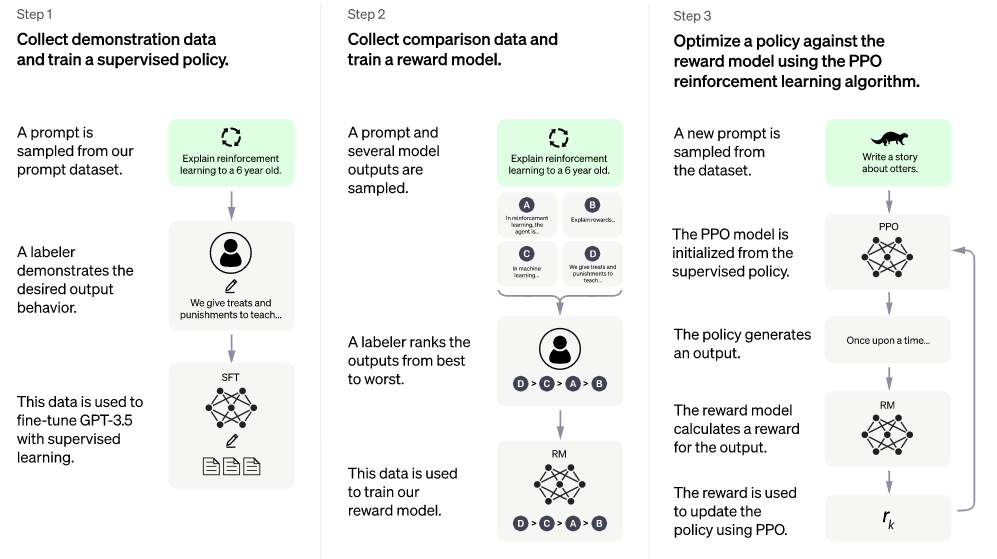
研究人员使用监督微调训练了一个初始模型:人类 AI 训练师在对话中扮演用户和 AI 助手,在此过程中收集数据。黄民烈认为,这种在真实调用数据上的 Fine-tune,能够确保数据的质量和多样性,从人类反馈中学习。InstructGPT 的训练数据量不大,全部加起来也就 10 万量级,但是数据质量(well-trained 的 AI 训练师)和数据多样性是非常高的,而最最重要的是,这些数据来自真实世界调用的数据,而不是学术界玩的“benchmark”。
为了创建强化学习的奖励模型,需要收集比较数据,研究人员使用的是包含两个或多个按质量排序的模型响应。从“两两比较的数据”中学习,这对强化学习而言意义很重要。
黄民烈指出:如果对单个生成结果进行打分,标注者主观性带来的偏差很大,是无法给出精确的奖励值的。在强化学习里面,奖励值差一点,最后训练的策略就差很远。而对于多个结果进行排序和比较,相对就容易做很多。这种比较式的评估方法,在很多语言生成任务的评价上也被广泛采用。
在技术炒作的声音之外,在许多科技界的从业者看来,ChatGPT 的确是一个具有里程碑意义的 AI 模型。
在 OpenAI 的 CEO Sam Altman 看来,我们能够通过 ChatGPT 与计算机交谈、并获得我们想要的东西,这使得软件从命令驱动转向了意图驱动。ChatGPT 作为一种语言接口,将是我们实现神经接口之前的最好方案。

关于 ChatGPT 未来的种种想象令人兴奋,但 ChatGPT 目前仍存在一些问题。很多用户发现,它有时会给出看似合理、但并不正确或甚至荒谬的答案。比如很多用户发现,ChatGPT 会一本正经地胡说八道:

将王安石《泊船瓜洲》中的诗句错当成另一首宋词:

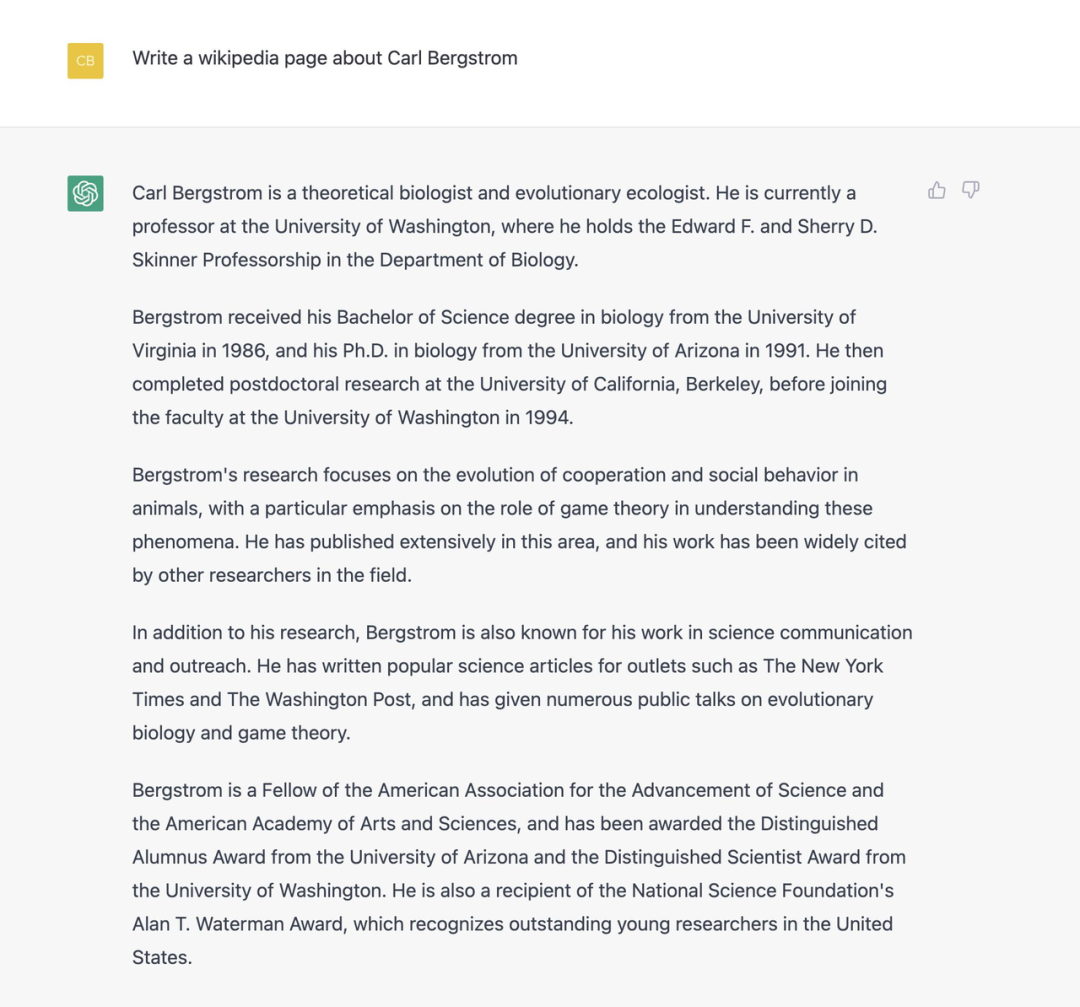
在为一个公众人物撰写传记时,ChatGPT 可能会插入错误数据:


作者 | 李梅
编辑 | 陈彩娴
https://www.theverge.com/2022/12/5/23493932/chatgpt-ai-generated-answers-temporarily-banned-stack-overflow-llms-dangers
0 条评论