浏览次数: 412
2017年6月,Google发表了一篇名为Attention Is All You Need(注意力是你需要的全部)的论文。
这篇论文由8名发量茂密的AI科学家联合撰写,他们在论文里创造性地提出了一种“注意力机制”,并基于此开发一个名叫Transformer(变形金刚)的深度学习模型——一位作者认为叫“注意力模型”过于无聊,就用玩梗的心态起了这个名字。
 8名作者大都离开Google,选择创业
从Transformer模型被提出的那一刻起,人工智能的历史进程被骤然加速了。研究者发现Transformer在自然语言处理(NLP)领域的效率奇高,相比传统RNN(循环神经网络)优势明显,于是很快便成为NLP研究者们推崇的首选模型。
Google的重大进展,却让OpenAI的工程师们彻夜难眠。OpenAI当年成立的初衷,就是打破Google在人工智能领域的垄断,而面对这只横空出世的“变形金刚”,他们做了一个重大决定:干脆就用Transformer这件敌人的武器,来跟Google正面硬刚。
2018年6月,在“变形金刚”诞生一周年之际,OpenAI推出了基于Transformer模型的GPT-1,其中GPT里面的“T”,就是Transformer的首字母。此后,OpenAI沿着这条路线把GPT-1持续迭代到本周刚发布的GPT-4,并让ChatGPT火遍了全球。
8名作者大都离开Google,选择创业
从Transformer模型被提出的那一刻起,人工智能的历史进程被骤然加速了。研究者发现Transformer在自然语言处理(NLP)领域的效率奇高,相比传统RNN(循环神经网络)优势明显,于是很快便成为NLP研究者们推崇的首选模型。
Google的重大进展,却让OpenAI的工程师们彻夜难眠。OpenAI当年成立的初衷,就是打破Google在人工智能领域的垄断,而面对这只横空出世的“变形金刚”,他们做了一个重大决定:干脆就用Transformer这件敌人的武器,来跟Google正面硬刚。
2018年6月,在“变形金刚”诞生一周年之际,OpenAI推出了基于Transformer模型的GPT-1,其中GPT里面的“T”,就是Transformer的首字母。此后,OpenAI沿着这条路线把GPT-1持续迭代到本周刚发布的GPT-4,并让ChatGPT火遍了全球。
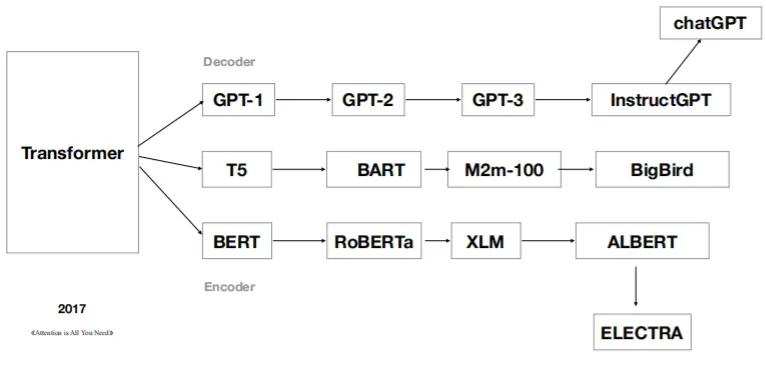 Transformer家族谱系,量子学派[7]
Transformer家族谱系,量子学派[7]
标杆旗帜一出,全球科技巨头就蜂拥而至,纷纷推出了自家基于Transformer的大模型,如Google的BERT,微软的Turing-NLG,英伟达的Megatron、国内华为的鹏程盘古、阿里的M6、百度的文心一言等大模型都是基于Transformer来构建。
更进一步,研究者发现Transformer不仅能够处理语言,处理图像能力也很猛,远胜于传统CNN(卷积神经网络)模型。2020年,Google科学家提出了Vision Transformer ( ViT )概念[1],给计算机视觉领域的人工智能也装上了火箭助推器。
到本文开始撰写时,Attention Is All You Need这篇论文已经被引用了68,147次,成为人工智能历史上被引数量第三高的论文。应该说,Transformer的出现扣动了此轮人工智能热潮的板机,你在朋友圈刷到的所有AI热点,几乎都跟这个“变形金刚”有关。
站在Transformer模型上,OpenAI成为全球最耀眼的明星,而发明人Google也让世界在AlphaGo之后再次敬畏起了它的实力,两家公司一度打起了大模型的军备竞赛,而全球其他科技巨头也不想只做围观者,要么已经躬身入局,要么正在摩拳擦掌。
其实,受Transformer启发,把它运用到炉火纯青并点燃另一场AI革命的公司还有一家,就是特斯拉。

借船:马斯克的“人工智能恐惧症”
在梳理特斯拉的AI轨迹之前,让我们先来了解一下伊隆·马斯克的“人工智能恐惧症”。
这个星球上唯一能让马斯克做噩梦的,不是贝索斯的光头,也不是薛定谔的刹车片,而是人工智能。2014年他就在推特上写道:“我们要对人工智能格外小心,它可能比核武器更危险。”在之后的一次访谈中,他又危言耸听道:“当人工智能成为不死的独裁者时,世界将永远无法挣脱(它的控制)。”
随后又强烈宣称“人类应该像监管食品、药物、飞机和汽车一样来监管人工智能。”
为何如此害怕?马斯克2018年在“西南偏南”大会上对话《西部世界》编剧乔纳森·诺兰时解释道[3]:我通常不提倡监管,而且倾向于减少这种枷锁,但是“人工智能把我吓坏了,它的能力比几乎任何人知道的都要强,而且进化速度是指数级的。”
 在《西部世界》里,马斯克的前妻Riley扮演一个高级AI
不过,马斯克一方面维持着“最恐人工智能的碳基生物”这一人设,一方面却在大干快上地投资AI。
2013年,马斯克个人投资了DeepMind;2015年他参与了OpenAI的众筹发起和Vicarious的B轮融资;2016年,马斯克又创办了脑机接口公司NeuraLink;而特斯拉也通过收购把DeepScale、GrokStyle、Perceptive Automata等人工智能公司纳入囊中。
特斯拉更是很早就开始布局人工智能。2013年特斯拉凭借Model S的热售市值突破100亿美元,马上开始筹划进军自动驾驶。在5月份马斯克跟Google创始人的一次对谈中这样讲:“飞机的自动驾驶仪(Autopilot)是一件很棒的东西,汽车也应该拥有它。”
在当时,“自动驾驶”对传统汽车厂商来说更像是一个科幻概念。1970年代全球汽车巨头们定义了DAS(驾驶员辅助系统),然后沿着这条路线谨慎推进,“自动驾驶”一方面大厂们不想干(会带来无穷的法律噩梦),另一方面也的确是干不了。
2014年,国际汽车工程师学会(SAE)把广义上的“自动驾驶”分成了6类。可以看到,传统车企在过去几十年基本上都在L0~L1级之间原地踏步,如果要达到L2级甚至更高,汽车就必须借助人工智能,而想要做到这一点,就要把汽车变得更像一台计算机,而非一个单纯的机械电子部件组合体。
在《西部世界》里,马斯克的前妻Riley扮演一个高级AI
不过,马斯克一方面维持着“最恐人工智能的碳基生物”这一人设,一方面却在大干快上地投资AI。
2013年,马斯克个人投资了DeepMind;2015年他参与了OpenAI的众筹发起和Vicarious的B轮融资;2016年,马斯克又创办了脑机接口公司NeuraLink;而特斯拉也通过收购把DeepScale、GrokStyle、Perceptive Automata等人工智能公司纳入囊中。
特斯拉更是很早就开始布局人工智能。2013年特斯拉凭借Model S的热售市值突破100亿美元,马上开始筹划进军自动驾驶。在5月份马斯克跟Google创始人的一次对谈中这样讲:“飞机的自动驾驶仪(Autopilot)是一件很棒的东西,汽车也应该拥有它。”
在当时,“自动驾驶”对传统汽车厂商来说更像是一个科幻概念。1970年代全球汽车巨头们定义了DAS(驾驶员辅助系统),然后沿着这条路线谨慎推进,“自动驾驶”一方面大厂们不想干(会带来无穷的法律噩梦),另一方面也的确是干不了。
2014年,国际汽车工程师学会(SAE)把广义上的“自动驾驶”分成了6类。可以看到,传统车企在过去几十年基本上都在L0~L1级之间原地踏步,如果要达到L2级甚至更高,汽车就必须借助人工智能,而想要做到这一点,就要把汽车变得更像一台计算机,而非一个单纯的机械电子部件组合体。
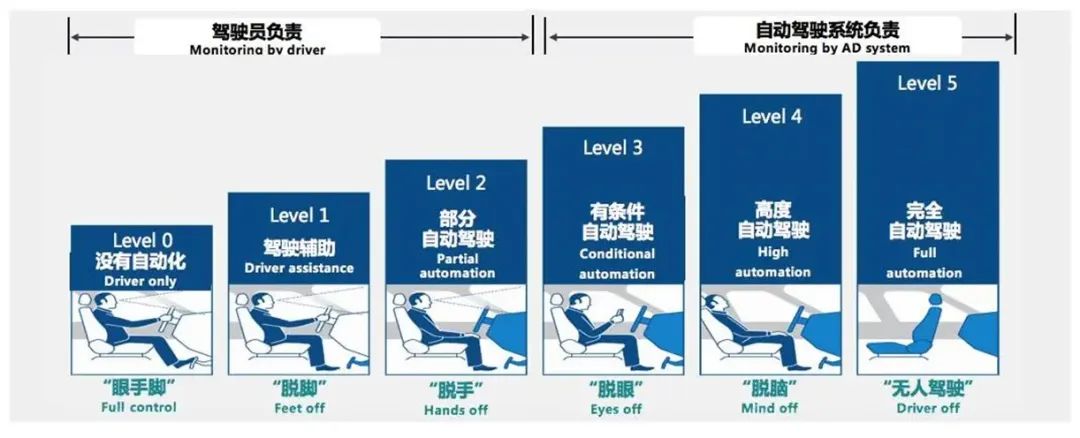 自动驾驶6个级别,未来智库[4]
而特斯拉在Model S上,就已经实现的电子电气架构革新,让汽车更像一台“四个轮子的计算机”。这种理念后来被前华为苏菁用大白话总结了出来:传统车厂认为车的基座是车,然后把计算机嵌进去;我们则认为汽车的基座是计算机,然后把车挂上去。
Modle S改电子电气架构初衷是为了降成本,比如减少又贵又沉的汽车线束,但新架构至少能让汽车的各部分听从“大脑”的统一指挥,等于为人工智能的落地搭了一套毛胚房(但还算不上精装修)。
毛胚房准备了,但要让AI真正“拎包入住”——实现L2级以上的“自动驾驶”,还需要什么东西?
我们通常认识的“自动驾驶”,就是汽车利用各种传感器,收集周围环境数据,然后汽车的大脑(核心是芯片)根据算法来解析这些数据,进而控制车辆行为。比如摄像头看到前方突然窜出一条狗,大脑解析后发出紧急刹车的指令,让汽车停下来。
在这个过程中,识别出前方窜出来的到底是一条德国牧羊犬,还是一只黑色垃圾袋,就需要一套“算法”了。这些算法,需要提前载入到汽车的“大脑”里,输入汽车各类传感器采集到的数据,然后作出实时的判断,进而控制汽车的行为。
汽车要在行驶过程中采集数据、加载算法、迅速作出判断,本身的计算性能也不能掉链子,尤其是高速行进时,决策晚1ms都可能会酿成大祸,如果“卡机”更是灾难。因此,汽车上搭载的芯片性能也不能糊弄,要有足够的算力。
而那些事先载入汽车大脑的算法从何而来?在早期,碳基程序员们用if-else语句来撰写算法,但在机器学习问世之后,科技公司们开始构建计算平台,汇聚了从终端提取和模拟生成的海量数据,在更高算力的芯片驱动下,不断训练,形成算法。
自动驾驶6个级别,未来智库[4]
而特斯拉在Model S上,就已经实现的电子电气架构革新,让汽车更像一台“四个轮子的计算机”。这种理念后来被前华为苏菁用大白话总结了出来:传统车厂认为车的基座是车,然后把计算机嵌进去;我们则认为汽车的基座是计算机,然后把车挂上去。
Modle S改电子电气架构初衷是为了降成本,比如减少又贵又沉的汽车线束,但新架构至少能让汽车的各部分听从“大脑”的统一指挥,等于为人工智能的落地搭了一套毛胚房(但还算不上精装修)。
毛胚房准备了,但要让AI真正“拎包入住”——实现L2级以上的“自动驾驶”,还需要什么东西?
我们通常认识的“自动驾驶”,就是汽车利用各种传感器,收集周围环境数据,然后汽车的大脑(核心是芯片)根据算法来解析这些数据,进而控制车辆行为。比如摄像头看到前方突然窜出一条狗,大脑解析后发出紧急刹车的指令,让汽车停下来。
在这个过程中,识别出前方窜出来的到底是一条德国牧羊犬,还是一只黑色垃圾袋,就需要一套“算法”了。这些算法,需要提前载入到汽车的“大脑”里,输入汽车各类传感器采集到的数据,然后作出实时的判断,进而控制汽车的行为。
汽车要在行驶过程中采集数据、加载算法、迅速作出判断,本身的计算性能也不能掉链子,尤其是高速行进时,决策晚1ms都可能会酿成大祸,如果“卡机”更是灾难。因此,汽车上搭载的芯片性能也不能糊弄,要有足够的算力。
而那些事先载入汽车大脑的算法从何而来?在早期,碳基程序员们用if-else语句来撰写算法,但在机器学习问世之后,科技公司们开始构建计算平台,汇聚了从终端提取和模拟生成的海量数据,在更高算力的芯片驱动下,不断训练,形成算法。
 图片来源:aionlinecourse
到这里,自动驾驶“四要素”就很明确了:1. 感知数据 2. 核心算法 3. 终端芯片 4. 计算平台。
但2013年的特斯拉还是一个名副其实的“小厂”,在四座大山面前基本上毫无积累,尤其是芯片和算法需要投入大量研发经费。马斯克此时的策略也很务实:造不如买。当时能进入特斯拉视野的供应商有且只有一家——以色列公司Mobileye。
Mobileye的名字包含“移动”和“眼睛”两个词,这家公司由号称“中东哈佛”的以色列希伯来大学教授Amnon Shashua于创建。自1999年成立之后,专注于开发自动/辅助驾驶技术,2014年在纽交所上市,2017年被英特尔以153亿美金的天价并购。
在上文提到的自动驾驶“四要素”中,Mobileye最擅长什么?核心算法。
跟近些年“算力论英雄”的情形不同,初期的自动/辅助驾驶对算力的要求并不高。与如今L4级自动驾驶动辄400 TOPS、L5级更是达到4000 TOPS的算力要求不同,L1级的自动驾驶所需算力甚至不到1 TOPS,L2级也仅仅是在2 TOPS附近徘徊。
L1级自动驾驶跟“自动驾驶”相隔十万八千里,基本上就是“驾驶员辅助”,比如自适应巡航、自动刹车、车道保持等功能,实现起来的确不用很强的计算能力,只需要廉价的摄像头雷达配合先进的图像识别算法,而这也正是Mobileye的强项。
在创立的前10年,Mobileye仅仅靠纯软件方案的视觉算法就实现了盈亏平衡。一直到2008年,Mobileye才推出了第一代自动驾驶芯片EyeQ1,由台积电代工,采用ARM内核和180nm工艺,而同期初代iPhone搭载的三星S5L8900芯片已经用上了90nm工艺。
到了2014年,Eye系列已经迭代至Q3,截至2013年年底,产品累计销量突破100万台。虽然Q3算力仍然是可怜的0.25 TOPS,但其捆绑销售的算法够香,对于急于上车智能驾驶、又苦于没有软件和算法开发能力的厂商来说,属于瞌睡遇到枕头。
图片来源:aionlinecourse
到这里,自动驾驶“四要素”就很明确了:1. 感知数据 2. 核心算法 3. 终端芯片 4. 计算平台。
但2013年的特斯拉还是一个名副其实的“小厂”,在四座大山面前基本上毫无积累,尤其是芯片和算法需要投入大量研发经费。马斯克此时的策略也很务实:造不如买。当时能进入特斯拉视野的供应商有且只有一家——以色列公司Mobileye。
Mobileye的名字包含“移动”和“眼睛”两个词,这家公司由号称“中东哈佛”的以色列希伯来大学教授Amnon Shashua于创建。自1999年成立之后,专注于开发自动/辅助驾驶技术,2014年在纽交所上市,2017年被英特尔以153亿美金的天价并购。
在上文提到的自动驾驶“四要素”中,Mobileye最擅长什么?核心算法。
跟近些年“算力论英雄”的情形不同,初期的自动/辅助驾驶对算力的要求并不高。与如今L4级自动驾驶动辄400 TOPS、L5级更是达到4000 TOPS的算力要求不同,L1级的自动驾驶所需算力甚至不到1 TOPS,L2级也仅仅是在2 TOPS附近徘徊。
L1级自动驾驶跟“自动驾驶”相隔十万八千里,基本上就是“驾驶员辅助”,比如自适应巡航、自动刹车、车道保持等功能,实现起来的确不用很强的计算能力,只需要廉价的摄像头雷达配合先进的图像识别算法,而这也正是Mobileye的强项。
在创立的前10年,Mobileye仅仅靠纯软件方案的视觉算法就实现了盈亏平衡。一直到2008年,Mobileye才推出了第一代自动驾驶芯片EyeQ1,由台积电代工,采用ARM内核和180nm工艺,而同期初代iPhone搭载的三星S5L8900芯片已经用上了90nm工艺。
到了2014年,Eye系列已经迭代至Q3,截至2013年年底,产品累计销量突破100万台。虽然Q3算力仍然是可怜的0.25 TOPS,但其捆绑销售的算法够香,对于急于上车智能驾驶、又苦于没有软件和算法开发能力的厂商来说,属于瞌睡遇到枕头。
 Mobileye EyeQ3芯片
马斯克不喜欢Mobileye,尤其是后者将算法直接封装进芯片里,交付客户的是一个“黑盒”,里面的算法无法更改。但不喜欢也没办法,Mobileye市场份额接近垄断,你爱买不买,宝马奔驰福特都得低头,特斯拉也只好乖乖地接受这种“店大欺客”。
2014年10月,特斯拉发布了第一个自动驾驶方案——Autopilot1.0版本,其中的硬件模块称之为Hardware 1.0(简称HW1.0)。这个方案把Mobileye EyeQ3作为硬件模块的大脑,另外还配备一个前置摄像头、12个超声波雷达和1个毫米波雷达。
自此,2014年10月之后生产的新车都会默认搭载HW1.0硬件,但用户此时还不能直接用——特斯拉采用的是“硬件先行,软件更新”的方式,先装硬件,再OTA升级,因此一直到2015年10月特斯拉v7.0版更新后,Autopilot1.0才正式被“点亮”。
Mobileye EyeQ3芯片
马斯克不喜欢Mobileye,尤其是后者将算法直接封装进芯片里,交付客户的是一个“黑盒”,里面的算法无法更改。但不喜欢也没办法,Mobileye市场份额接近垄断,你爱买不买,宝马奔驰福特都得低头,特斯拉也只好乖乖地接受这种“店大欺客”。
2014年10月,特斯拉发布了第一个自动驾驶方案——Autopilot1.0版本,其中的硬件模块称之为Hardware 1.0(简称HW1.0)。这个方案把Mobileye EyeQ3作为硬件模块的大脑,另外还配备一个前置摄像头、12个超声波雷达和1个毫米波雷达。
自此,2014年10月之后生产的新车都会默认搭载HW1.0硬件,但用户此时还不能直接用——特斯拉采用的是“硬件先行,软件更新”的方式,先装硬件,再OTA升级,因此一直到2015年10月特斯拉v7.0版更新后,Autopilot1.0才正式被“点亮”。
 早期的Autopilot1.0界面
在Mobileye“上车”的那一刻,马斯克就暗中准备自研自动驾驶的算法、芯片和计算平台。
2015年马斯克试图拉拢硅谷著名黑客George Hotz来特斯拉搞无人驾驶,承诺如果成功替代Mobileye,特斯拉会一次性给他“数百万美元奖金”,但被对方拒绝,随后Bloomberg的一篇报道将两人的邮件披露出来[5],立马引来了Mobileye的质问。
被Mobileye“卡脖子”的特斯拉只好在官方网站上发了一份声明,表示Mobileye提供的芯片和算法仍然是“全世界最好”,特斯拉还会继续使用。然后马斯克亲自在twitter上转发了这份声明,才打消了Mobileye的怒火,避免了特斯拉被“断供”。
事件平息后,马斯克加速推进“自主可控”计划。2016年1月,传奇的AMD首席架构师Jim Keller被挖到了特斯拉,他的长期战友Peter Bannon也在1个月之后来到马斯克的阵营——特斯拉跟Mobileye“脱钩”已经只是一个时间问题。
分手的决心如此强烈,马斯克就差一个冠冕堂皇的理由和一个暂时替代Mobileye的备胎。很快,它们都来了。
早期的Autopilot1.0界面
在Mobileye“上车”的那一刻,马斯克就暗中准备自研自动驾驶的算法、芯片和计算平台。
2015年马斯克试图拉拢硅谷著名黑客George Hotz来特斯拉搞无人驾驶,承诺如果成功替代Mobileye,特斯拉会一次性给他“数百万美元奖金”,但被对方拒绝,随后Bloomberg的一篇报道将两人的邮件披露出来[5],立马引来了Mobileye的质问。
被Mobileye“卡脖子”的特斯拉只好在官方网站上发了一份声明,表示Mobileye提供的芯片和算法仍然是“全世界最好”,特斯拉还会继续使用。然后马斯克亲自在twitter上转发了这份声明,才打消了Mobileye的怒火,避免了特斯拉被“断供”。
事件平息后,马斯克加速推进“自主可控”计划。2016年1月,传奇的AMD首席架构师Jim Keller被挖到了特斯拉,他的长期战友Peter Bannon也在1个月之后来到马斯克的阵营——特斯拉跟Mobileye“脱钩”已经只是一个时间问题。
分手的决心如此强烈,马斯克就差一个冠冕堂皇的理由和一个暂时替代Mobileye的备胎。很快,它们都来了。
过渡:一段跟黄仁勋的塑料友谊
2016年5月,一辆开启自动驾驶模式的Model S在佛罗里达州撞车,40岁的司机Joshua Brown当场死亡。
这辆Model S撞上的是一辆货车的白色车厢。当后者横穿马路时,特斯拉的Autopilot系统虽然通过毫米波雷达检测到了车厢,但误把蓝天映衬下的白色车厢当成一块路牌,AEB(自动紧急制动系统)于是没有做任何的反应,车就径直撞上去了。
 惨烈的Model S车祸现场
这是人类历史上已知的第一起自动驾驶事故,自然引起全球舆论关注,美国国家运输安全委员会(NTSB)发布了足足500页的报告。调查人员发现司机Joshua Brown在驾驶过程中也不老实,90%的时间双手离开方向盘,并忽视了七次系统警告。
司机虽有错,但企业也得背锅。特斯拉发现如果要跟横穿马路的车辆相撞,Mobileye的EyeQ3芯片无法提供足够的算力,要等到两年后发布的EyeQ4才行,而Mobileye在事故的声明里又暗搓搓地甩锅特斯拉,这让马斯克更加坚定了踢开Mobileye的决心。
5个月后,特斯拉发布了Autopilot 2.0和硬件模块HW 2.0,彻底跟Mobileye分道扬镳。接替它的是黄仁勋的英伟达。
这里插一下:特斯拉自动驾驶方案的名字眼花缭乱,最开始就叫做Autopilot,后来引入一个高级选配方案FSD(Full Self-Driving),两者就是同一套系统的两档产品,用户多花钱,就可以激活更多功能,背后的硬件叫做Hardware(1.0→4.0)。
英伟达在自动驾驶方面其实也是一枚新兵蛋子。在2015年1月,黄仁勋向世界发布第一代了NVIDIA Drive平台,这个平台由两部分组成:数字座舱(CX)和自动驾驶(PX),两者都使用英伟达Tegra X1——任天堂switch的同款芯片。
Tegra是英伟达移动芯片家族的名字,当年坑了不少厂商,比如HTC和小米,一直被高通摁着摩擦。后来老黄干脆放飞自我,把在显卡领域练就的“砌算力”大法发挥到极致,功耗发热猛增,基本退出手机市场,但在自动驾驶领域却重获新生。
以Tegra X1为例,其采用标准的CPU+GPU架构,CPU部分采用4颗Arm A57内核和4颗A53 内核,核心数总计8颗;而GPU部分则采用Maxwell架构,核心数高达256颗。这种“暴力堆砌”下,单颗Tegra X1的算力居然攀到了1 TFlops。
惨烈的Model S车祸现场
这是人类历史上已知的第一起自动驾驶事故,自然引起全球舆论关注,美国国家运输安全委员会(NTSB)发布了足足500页的报告。调查人员发现司机Joshua Brown在驾驶过程中也不老实,90%的时间双手离开方向盘,并忽视了七次系统警告。
司机虽有错,但企业也得背锅。特斯拉发现如果要跟横穿马路的车辆相撞,Mobileye的EyeQ3芯片无法提供足够的算力,要等到两年后发布的EyeQ4才行,而Mobileye在事故的声明里又暗搓搓地甩锅特斯拉,这让马斯克更加坚定了踢开Mobileye的决心。
5个月后,特斯拉发布了Autopilot 2.0和硬件模块HW 2.0,彻底跟Mobileye分道扬镳。接替它的是黄仁勋的英伟达。
这里插一下:特斯拉自动驾驶方案的名字眼花缭乱,最开始就叫做Autopilot,后来引入一个高级选配方案FSD(Full Self-Driving),两者就是同一套系统的两档产品,用户多花钱,就可以激活更多功能,背后的硬件叫做Hardware(1.0→4.0)。
英伟达在自动驾驶方面其实也是一枚新兵蛋子。在2015年1月,黄仁勋向世界发布第一代了NVIDIA Drive平台,这个平台由两部分组成:数字座舱(CX)和自动驾驶(PX),两者都使用英伟达Tegra X1——任天堂switch的同款芯片。
Tegra是英伟达移动芯片家族的名字,当年坑了不少厂商,比如HTC和小米,一直被高通摁着摩擦。后来老黄干脆放飞自我,把在显卡领域练就的“砌算力”大法发挥到极致,功耗发热猛增,基本退出手机市场,但在自动驾驶领域却重获新生。
以Tegra X1为例,其采用标准的CPU+GPU架构,CPU部分采用4颗Arm A57内核和4颗A53 内核,核心数总计8颗;而GPU部分则采用Maxwell架构,核心数高达256颗。这种“暴力堆砌”下,单颗Tegra X1的算力居然攀到了1 TFlops。
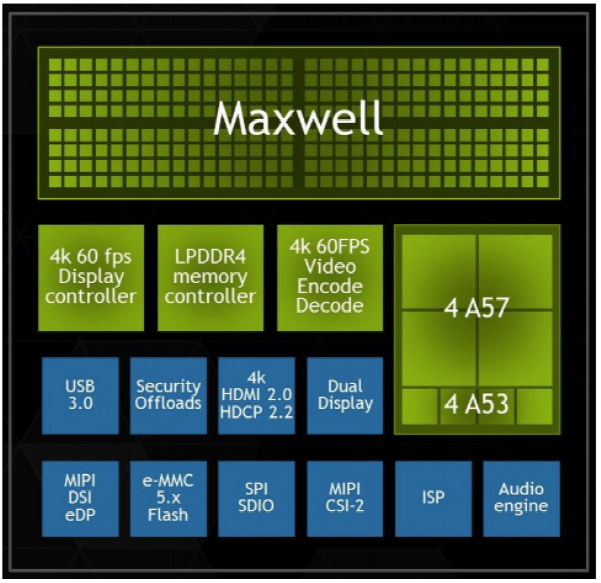 Tegra X1 图片来源:英伟达
1 TFlops是什么概念呢?TFlops指的是“每秒万亿次浮点运算能力”,1996年英特尔帮美国能源部Sandia国家实验室制造了一台名叫“ASCI Red”的超级计算机,占地1600平方英尺耗电500千瓦,用来模拟核弹头,它的算力就是1.06 TFlops。
英伟达的“算力大法”,正好是自动驾驶由L1向L2、L3演进时急需的东西。
比如L1级的“单车道定速巡航”功能下,车载芯片只需要处理有限的数据量,但一旦进化到L2级别的“自动变道”,车辆不仅要识别车道和周围车辆,还要实时算出最优变道决策,算力需求提升了一个数量级。相比单纯地用CPU来提供算力,英伟达“CPU+GPU”模式能更好地匹配自动驾驶的需求。
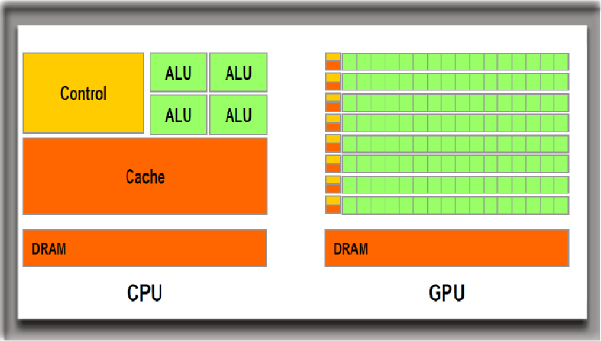
为什么?简单说,CPU(中央处理器)和GPU(图形处理器)均由控制单元(Control)、运算单元(ALU)、存储单元(DRAM)、缓存(Cache)等几个部分构成,两者区别主要在于各个单元的数量配比,尤其是运算单元的数量配比。
运算单元是芯片数据计算的中心,由算术逻辑部件(ALU)组成,ALU即大家口中的“核”,所谓8核CPU指的便是有8个计算单元。为图像处理和矩阵计算而生的GPU,与CPU的最大差别在于可以暴力叠加成千上万个ALU进行并行运算。
简单类比,CPU像一位数学系教授,能力全面,GPU则像他手下的一年级本科生,偏科严重,只会算数。教授平时擅长统筹全局,发号施令,他自己虽然也会算数,甚至抵得上两三个本科生,但显然比不过100个本科生叠加在一起的“算力”。
当GPU遇到人工智能后,开始大放异彩。2006年,英伟达推出基于GPU的CUDA开发平台,开发者可以通过这一平台,使用C语言编写程序以解决复杂的计算问题,换言之,原本只用做3D渲染的GPU变得更加通用,可执行的任务更加多样。
2009年,斯坦福大学的Raina、Madhavan及吴恩达在一篇论文中论述了GPU在深度学习方面相对CPU的大幅优势[6],将AI训练时间从几周缩短至几小时。这篇论文为人工智能的硬件实现指明了方向。GPU大大加速了AI从论文走向现实的过程。
因此,特斯拉从Mobileye切换到英伟达不仅是换供应商这么简单,而是把人工智能硬件实现的利器——GPU装上了车,等于把“毛胚房”换成了“精装房”,实现了AI算法的拎包入住,同时也把“电动车”和“人工智能”两大时代主题连接在了一起。
特斯拉在2016年10月发布的HW 2.0硬件平台,包含8个摄像头、1个毫米波雷达、12个超声波雷达,以及英伟达DRIVE PX2定制主板,主板上面搭载了Tegra X2 CPU和升级为Pascal架构的GPU,算力是10 TOPS,大概是Mobileye EyeQ3的整整40倍。
“新女友”看起来貌美如花,但特斯拉为了这次分手其实付出了不小的代价。
HW 2.0的硬件性能虽然优越,但软件上却是短板,特斯拉内部团队和英伟达在算法上都还达不到Mobileye的水准。比如一直道HW 2.0发布的3个月后,特斯拉才把自适应巡航控制、前方碰撞预警和方向盘自动转向等基本功能给匆忙地做出来。
因此,虽然特斯拉自2016年10月后出厂的车都标配了HW 2.0,但一直到2017年上半年才把Autopilot 1.0的功能都实现出来。因此有用户调侃道:“搭载了更强劲硬件的新车车主们等了足足半年,总算可以享受跟老车主一样的辅助驾驶功能了。”
但顶着客户流失的风险,特斯拉也要把Mobileye换成英伟达。除了感情因素之外,更重要的是NVIDIA Drive是一个开放平台,自由度很高,特斯拉可以一边在英伟达的平台上练手,一边积累自己的软件和算法能力,为最后的自研铺平道路。
对“渣男”来说,所有的“现任”都将是“前任”。在拥抱英伟达的同时,特斯拉的自研究也在紧锣密鼓地进行着。
Tegra X1 图片来源:英伟达
1 TFlops是什么概念呢?TFlops指的是“每秒万亿次浮点运算能力”,1996年英特尔帮美国能源部Sandia国家实验室制造了一台名叫“ASCI Red”的超级计算机,占地1600平方英尺耗电500千瓦,用来模拟核弹头,它的算力就是1.06 TFlops。
英伟达的“算力大法”,正好是自动驾驶由L1向L2、L3演进时急需的东西。
比如L1级的“单车道定速巡航”功能下,车载芯片只需要处理有限的数据量,但一旦进化到L2级别的“自动变道”,车辆不仅要识别车道和周围车辆,还要实时算出最优变道决策,算力需求提升了一个数量级。相比单纯地用CPU来提供算力,英伟达“CPU+GPU”模式能更好地匹配自动驾驶的需求。
为什么?简单说,CPU(中央处理器)和GPU(图形处理器)均由控制单元(Control)、运算单元(ALU)、存储单元(DRAM)、缓存(Cache)等几个部分构成,两者区别主要在于各个单元的数量配比,尤其是运算单元的数量配比。
运算单元是芯片数据计算的中心,由算术逻辑部件(ALU)组成,ALU即大家口中的“核”,所谓8核CPU指的便是有8个计算单元。为图像处理和矩阵计算而生的GPU,与CPU的最大差别在于可以暴力叠加成千上万个ALU进行并行运算。
简单类比,CPU像一位数学系教授,能力全面,GPU则像他手下的一年级本科生,偏科严重,只会算数。教授平时擅长统筹全局,发号施令,他自己虽然也会算数,甚至抵得上两三个本科生,但显然比不过100个本科生叠加在一起的“算力”。
当GPU遇到人工智能后,开始大放异彩。2006年,英伟达推出基于GPU的CUDA开发平台,开发者可以通过这一平台,使用C语言编写程序以解决复杂的计算问题,换言之,原本只用做3D渲染的GPU变得更加通用,可执行的任务更加多样。
2009年,斯坦福大学的Raina、Madhavan及吴恩达在一篇论文中论述了GPU在深度学习方面相对CPU的大幅优势[6],将AI训练时间从几周缩短至几小时。这篇论文为人工智能的硬件实现指明了方向。GPU大大加速了AI从论文走向现实的过程。
因此,特斯拉从Mobileye切换到英伟达不仅是换供应商这么简单,而是把人工智能硬件实现的利器——GPU装上了车,等于把“毛胚房”换成了“精装房”,实现了AI算法的拎包入住,同时也把“电动车”和“人工智能”两大时代主题连接在了一起。
特斯拉在2016年10月发布的HW 2.0硬件平台,包含8个摄像头、1个毫米波雷达、12个超声波雷达,以及英伟达DRIVE PX2定制主板,主板上面搭载了Tegra X2 CPU和升级为Pascal架构的GPU,算力是10 TOPS,大概是Mobileye EyeQ3的整整40倍。
“新女友”看起来貌美如花,但特斯拉为了这次分手其实付出了不小的代价。
HW 2.0的硬件性能虽然优越,但软件上却是短板,特斯拉内部团队和英伟达在算法上都还达不到Mobileye的水准。比如一直道HW 2.0发布的3个月后,特斯拉才把自适应巡航控制、前方碰撞预警和方向盘自动转向等基本功能给匆忙地做出来。
因此,虽然特斯拉自2016年10月后出厂的车都标配了HW 2.0,但一直到2017年上半年才把Autopilot 1.0的功能都实现出来。因此有用户调侃道:“搭载了更强劲硬件的新车车主们等了足足半年,总算可以享受跟老车主一样的辅助驾驶功能了。”
但顶着客户流失的风险,特斯拉也要把Mobileye换成英伟达。除了感情因素之外,更重要的是NVIDIA Drive是一个开放平台,自由度很高,特斯拉可以一边在英伟达的平台上练手,一边积累自己的软件和算法能力,为最后的自研铺平道路。
对“渣男”来说,所有的“现任”都将是“前任”。在拥抱英伟达的同时,特斯拉的自研究也在紧锣密鼓地进行着。

自研:吃着碗里的,看着锅里的
当马斯克开始搞AI时一定会有感触:相比于制造业,美国的AI和芯片人才实在是太多了。
跟从1980年代开始就逐步外迁的制造业不同,美国在计算机科学的三大应用领域——互联网、软件、芯片设计上一直保有雄厚的人才储备。以ACM图灵奖获得者为代表的顶尖科学家在高校、产业和研究机构里突破前沿,而数不清的高级工程师则在Google、苹果、微软、Intel等Top公司之间频繁流转。
特斯拉2015年筹备自研无人驾驶时,已是科技圈的当红炸子鸡,马斯克有资本从硅谷大厂里撬走各路牛人和大神。从2015年至今,特斯拉无人驾驶团队的架构历经多次调整,人员也熙来攘往,但无论是硬件还是软件,马斯克挑选的各个团队负责人,基本上都是世界最顶级的科学家或工程师。
我们可以从几个大牛的简历中窥探到特斯拉Autopilot团队极高的人才密度:AMD K7/K8/Zen架构的开拓者Jim Keller、苹果芯片团队的核心成员Pete Bannon、Swift编程语言的发明人Chris Lattner、OpenAI首席科学家Andrej Karpathy……

特斯拉团队(左起):硬件总监及Dojo负责人Ganesh Venkataramanan;工程总监Milan Kovac;人工智能总监Andrej Karpathy;软件总监Ashok Elluswamy;总忽悠师Elon Musk ,2021 Tesla AI Day
这里重点提一下Andrej Karpathy。这位出生于1986年的小哥是斯洛伐克人,15岁随父母移民加拿大,2015年获得斯坦福大学博士,导师是计算机大神李飞飞,在读博期间他已经是人工智能届的超级明星,毕业后直接参与创办了OpenAI。
2017年,他被马斯克厚着脸皮挖到了特斯拉,而从2017年到2022年,Andrej Karpathy一直担任特斯拉人工智能总监,并直接向马斯克汇报,直到2022年离职重返OpenAI。客观地说,他是特斯拉人工智能团队的最重要的缔造者之一。
 发量相对浓密时期的Andrej Karpathy
而在顶峰时,特斯拉Autopilot团队拥有300多名顶级工程师(不包括1000多名数据标注员),其中200人专攻软件,100人专攻硬件和芯片,马斯克在一次采访中说[8]:这些精英“人家随便去哪儿都能找到工作,没有谁是他们真正的老板。”
在硅谷人才和自身光环的加持下,特斯拉不准备去抄英伟达和Mobileye的作业,那他们想怎么干?
自动驾驶的具体实现非常复杂,而且作为一门崭新的科学,新技术、新路线、新突破层出不穷,但沿着我们前文提到自动驾驶的“四要素”(1. 感知数据 2. 核心算法 3. 终端芯片 4. 计算平台)来出发,基本上就能理清马斯克规划的庞大蓝图。
首先,在“感知数据”方面,特斯拉选择了“纯视觉感知”方案,放弃了逐渐成熟的激光雷达、毫米波雷达等非视觉传感器。这一做法在业内独树一帜,难度相比其他主流方案直接拉高了一个数量级,在业界也引起热烈的讨论甚至争议。
发量相对浓密时期的Andrej Karpathy
而在顶峰时,特斯拉Autopilot团队拥有300多名顶级工程师(不包括1000多名数据标注员),其中200人专攻软件,100人专攻硬件和芯片,马斯克在一次采访中说[8]:这些精英“人家随便去哪儿都能找到工作,没有谁是他们真正的老板。”
在硅谷人才和自身光环的加持下,特斯拉不准备去抄英伟达和Mobileye的作业,那他们想怎么干?
自动驾驶的具体实现非常复杂,而且作为一门崭新的科学,新技术、新路线、新突破层出不穷,但沿着我们前文提到自动驾驶的“四要素”(1. 感知数据 2. 核心算法 3. 终端芯片 4. 计算平台)来出发,基本上就能理清马斯克规划的庞大蓝图。
首先,在“感知数据”方面,特斯拉选择了“纯视觉感知”方案,放弃了逐渐成熟的激光雷达、毫米波雷达等非视觉传感器。这一做法在业内独树一帜,难度相比其他主流方案直接拉高了一个数量级,在业界也引起热烈的讨论甚至争议。
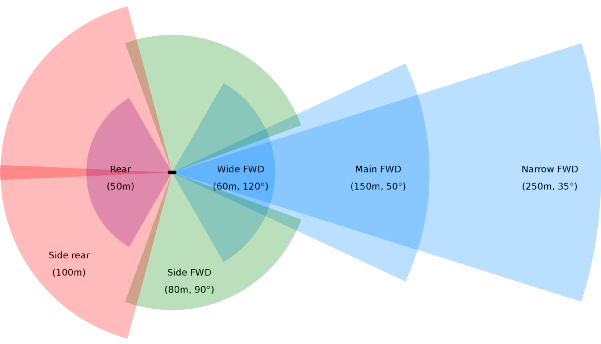 特斯拉8个摄像头覆盖范围
特斯拉8个摄像头覆盖范围
自动驾驶领域大多数专家都认为“纯视觉”方案不可取,不少用户也颇有微词,认为在技术不成熟的情况下就放弃雷达是对用户安全的不负责任。马斯克对这些批评置若罔闻,并公开嘲讽业界对高精度地图和激光雷达等方案的依赖。
其次,在“核心算法”方面,简单来说就是特斯拉通过8个摄像头采集的2D图像,使用复杂的感知神经网络架构进行加工,构建出一个能够表征真实世界的3D向量空间,这个空间里拥有自动驾驶决策场景里所需要的几乎所有信息,比如车道、行人、建筑物等。
 从8个摄像头到3D向量空间,2021 Tesla AI Day
基于这个3D向量空间,特斯拉设计了一个HydraNet架构——Hydra是希腊神话中“九头蛇”的名字,意思是这套架构共享一个数据“躯干”(BackBone),为1000多个任务的“头”(Head)提供支持,比如物体检测、交通灯识别、车道线预测等。
这些任务的算法大都由云端的计算平台在吞噬了巨大数据量后训练而来。因此,特斯拉的自动驾驶其实不存在“核心算法”的概念,搭载在汽车终端上的是一个复杂的基于神经网络的系统,由无数个模块组合而成,宛如一座巨大的迷宫。
第三,在“终端芯片”方面,由于需要实时构建庞大的3D向量空间,每一辆开启FSD的特斯拉汽车都需要极强的算力来消化海量数据。马斯克的应对思路非常清晰:招募团队,自己从头开始研发自动驾驶的终端芯片,替代掉英伟达的方案。
这里需要区分的是:我们通常说的车载核心芯片通常有两类,一类是给智能座舱提供算力的芯片,这一类特斯拉基本都外购成熟的消费级CPU,历代车型用过英伟达Tegra3(2012-2018)、Intel A3950(2018-2021)和AMD 的Ryzen(2021-至今)。
另一类则是给自动驾驶提供算力的芯片,算力要求更高,Mobileye和英伟达Drive PX2提供的是这类,特斯拉要自研的也是这类。思路大致是:在“CPU+GPU”的基础架构上再增添专门的AISC(专用集成电路),来解决潜在的算力瓶颈。
最后,在“计算平台”方面,特斯拉之前是购买英伟达的板卡来搭建数据中心,但既然决定要自研车载终端芯片,干脆把训练算法的计算平台也一并自研。2019年4月,马斯克在特斯拉Autonomy Day上首次公布了超级计算机Dojo的研发计划。
综合来看,马斯克试图吃透无人驾驶的每一个环节,这是一个充满野心和疯狂的计划。
特斯拉跟英伟达“分手”实属必然。一方面马斯克笃信“纯视觉”方案,试图跟其他厂商拉开差距,英伟达的通用硬件方案就无法满足需求了;另一方面,Drive PX2的售价高达10000美元+,这对成本敏感体质的马斯克来说是一个难以安眠的数字。
英伟达对特斯拉其实相当有诚意,除了在定价方面给予了很大折扣之外,黄仁勋还在社交媒体上晒出自己的特斯拉座驾以及和马斯克的合照,让人仿佛梦回2005年苹果与Intel的世纪牵手。但特斯拉基本上也在重复苹果抛弃Intel的故事。
从8个摄像头到3D向量空间,2021 Tesla AI Day
基于这个3D向量空间,特斯拉设计了一个HydraNet架构——Hydra是希腊神话中“九头蛇”的名字,意思是这套架构共享一个数据“躯干”(BackBone),为1000多个任务的“头”(Head)提供支持,比如物体检测、交通灯识别、车道线预测等。
这些任务的算法大都由云端的计算平台在吞噬了巨大数据量后训练而来。因此,特斯拉的自动驾驶其实不存在“核心算法”的概念,搭载在汽车终端上的是一个复杂的基于神经网络的系统,由无数个模块组合而成,宛如一座巨大的迷宫。
第三,在“终端芯片”方面,由于需要实时构建庞大的3D向量空间,每一辆开启FSD的特斯拉汽车都需要极强的算力来消化海量数据。马斯克的应对思路非常清晰:招募团队,自己从头开始研发自动驾驶的终端芯片,替代掉英伟达的方案。
这里需要区分的是:我们通常说的车载核心芯片通常有两类,一类是给智能座舱提供算力的芯片,这一类特斯拉基本都外购成熟的消费级CPU,历代车型用过英伟达Tegra3(2012-2018)、Intel A3950(2018-2021)和AMD 的Ryzen(2021-至今)。
另一类则是给自动驾驶提供算力的芯片,算力要求更高,Mobileye和英伟达Drive PX2提供的是这类,特斯拉要自研的也是这类。思路大致是:在“CPU+GPU”的基础架构上再增添专门的AISC(专用集成电路),来解决潜在的算力瓶颈。
最后,在“计算平台”方面,特斯拉之前是购买英伟达的板卡来搭建数据中心,但既然决定要自研车载终端芯片,干脆把训练算法的计算平台也一并自研。2019年4月,马斯克在特斯拉Autonomy Day上首次公布了超级计算机Dojo的研发计划。
综合来看,马斯克试图吃透无人驾驶的每一个环节,这是一个充满野心和疯狂的计划。
特斯拉跟英伟达“分手”实属必然。一方面马斯克笃信“纯视觉”方案,试图跟其他厂商拉开差距,英伟达的通用硬件方案就无法满足需求了;另一方面,Drive PX2的售价高达10000美元+,这对成本敏感体质的马斯克来说是一个难以安眠的数字。
英伟达对特斯拉其实相当有诚意,除了在定价方面给予了很大折扣之外,黄仁勋还在社交媒体上晒出自己的特斯拉座驾以及和马斯克的合照,让人仿佛梦回2005年苹果与Intel的世纪牵手。但特斯拉基本上也在重复苹果抛弃Intel的故事。
 黄仁勋在社交媒体上分享自己的Model X
黄仁勋可能低估了特斯拉的决心和实力,在2018年8月的一次业绩电话会议中,一位分析师问及特斯拉自研芯片的影响时,黄仁勋先是谈了一下自研芯片的难度,然后说:“如果他们没搞出结果,给我打电话,我会很乐意帮忙的。”
电话会议结束后,马斯克立即在twitter上回应,措辞的塑料友谊感十足:“Nvidia制造了很棒的硬件,高度尊重黄总的公司。”同时又很司马昭地表示:“我们的硬件需求是很独特的,需要跟我们的软件紧密匹配。”
黄仁勋在社交媒体上分享自己的Model X
黄仁勋可能低估了特斯拉的决心和实力,在2018年8月的一次业绩电话会议中,一位分析师问及特斯拉自研芯片的影响时,黄仁勋先是谈了一下自研芯片的难度,然后说:“如果他们没搞出结果,给我打电话,我会很乐意帮忙的。”
电话会议结束后,马斯克立即在twitter上回应,措辞的塑料友谊感十足:“Nvidia制造了很棒的硬件,高度尊重黄总的公司。”同时又很司马昭地表示:“我们的硬件需求是很独特的,需要跟我们的软件紧密匹配。”
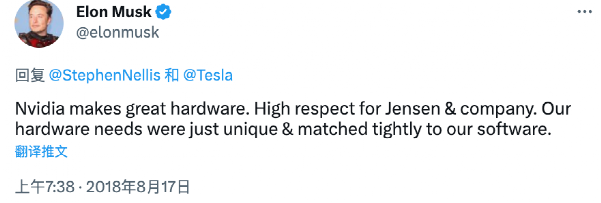
2018年是特斯拉Autopilot自研的冲刺节点:人工智能总监Andrej Karpathy领导团队通过大型神经网络来训练算法;硬件大神Jim Keller和接班人Pete Bannon主持终端FSD芯片的研发;元老级高管David Lau则带领近百人的团队改善数据采集和车机交互……
特斯拉能不能交出一张满意答卷?不仅英伟达想知道,全世界想抄作业的人也都在等待着。
答案:特斯拉是汽车公司,还是AI公司?
2021年8月19日,当Andrej Karpathy在特斯拉AI Day上展示Transformer时,全世界的友商都瞪大了眼睛。
如前文所述,特斯拉“纯视觉”方案的第一步,就是把8个摄像头采集的图像提取特征,融合成一个统一的三维向量空间。这个idea很符合“第一性原理”,是基础中的基础,但实现起来极难,传统的基于2D图像的CNN卷积根本解决不了问题。
 极其复杂的3D向量空间
特斯拉的做法是用上了新鲜出炉的Transformer。在开头我们讲过,Transformer不仅处理自然语言在行,处理计算机视觉同样是神器,在Google和OpenAI都工作过的Andrej Karpathy自然不会放过,在第一时间就带领团队将其用在3D向量空间的创建上了。
这是一个巨大的突破。客观说只有解决了这个问题,特斯拉才有抛弃激光雷达的底气。
具体实现的方法,感兴趣的读者可以详读参考文献[15]。特斯拉率先使用Transformer之后,全球同行们纷纷跟随。应该说,Transformer除了把GPT大模型送到全球聚光灯之下外,它还在每一台具备自动/辅助驾驶功能的汽车里默默发挥着作用。
当然,Transformer模型也只是特斯拉自动驾驶算法系统的一个“零部件”,跟它一起发挥作用的还有无数新老技术。而且要注意:人工智能是一门日行千里、甚至在不断加速的科学,今天的“神器”到了明天,可能就会被更好的算法和模型替代掉。
Karpathy的展示只是特斯拉“全栈自研”的一小部分,由于不同团队进度的差异,面纱是逐步被揭开的。
首先亮相的其实是硬件。2019年4月,特斯拉终于发布了“自主可控”的自动驾驶硬件平台HW 3.0。全球科技圈对此期盼已久:老车主们重点关注能否免费升级,友商们纷纷掏出放大镜准备认真“学习”,而对冲基金和类似System Plus这样的咨询公司则迅速行动,在第一时间对HW 3.0进行了拆解。
极其复杂的3D向量空间
特斯拉的做法是用上了新鲜出炉的Transformer。在开头我们讲过,Transformer不仅处理自然语言在行,处理计算机视觉同样是神器,在Google和OpenAI都工作过的Andrej Karpathy自然不会放过,在第一时间就带领团队将其用在3D向量空间的创建上了。
这是一个巨大的突破。客观说只有解决了这个问题,特斯拉才有抛弃激光雷达的底气。
具体实现的方法,感兴趣的读者可以详读参考文献[15]。特斯拉率先使用Transformer之后,全球同行们纷纷跟随。应该说,Transformer除了把GPT大模型送到全球聚光灯之下外,它还在每一台具备自动/辅助驾驶功能的汽车里默默发挥着作用。
当然,Transformer模型也只是特斯拉自动驾驶算法系统的一个“零部件”,跟它一起发挥作用的还有无数新老技术。而且要注意:人工智能是一门日行千里、甚至在不断加速的科学,今天的“神器”到了明天,可能就会被更好的算法和模型替代掉。
Karpathy的展示只是特斯拉“全栈自研”的一小部分,由于不同团队进度的差异,面纱是逐步被揭开的。
首先亮相的其实是硬件。2019年4月,特斯拉终于发布了“自主可控”的自动驾驶硬件平台HW 3.0。全球科技圈对此期盼已久:老车主们重点关注能否免费升级,友商们纷纷掏出放大镜准备认真“学习”,而对冲基金和类似System Plus这样的咨询公司则迅速行动,在第一时间对HW 3.0进行了拆解。
 HW3.0和HW2.5(HW2.0的简单升级)板卡对比图
HW3.0一共包含4746个零件,其中两颗刻有Tesla标记的银色FSD芯片最引人瞩目。这款芯片是特斯拉硬件自研的最大成果,由三星在得克萨斯州奥斯汀的工厂代工,采用14nm FinFET工艺,面积大约为260平方毫米,集成了60亿晶体管。
随后,在2019年8月的IEEE的Hot Chips会议(高性能处理器顶会)上,特斯拉芯片负责人Pete Bannon(Jim Keller已离职)展示了FSD的内部结构,可以看到特斯拉没有采用英伟达通常的CPU+GPU架构,而是采用高度定制的CPU+GPU+ASIC架构。
HW3.0和HW2.5(HW2.0的简单升级)板卡对比图
HW3.0一共包含4746个零件,其中两颗刻有Tesla标记的银色FSD芯片最引人瞩目。这款芯片是特斯拉硬件自研的最大成果,由三星在得克萨斯州奥斯汀的工厂代工,采用14nm FinFET工艺,面积大约为260平方毫米,集成了60亿晶体管。
随后,在2019年8月的IEEE的Hot Chips会议(高性能处理器顶会)上,特斯拉芯片负责人Pete Bannon(Jim Keller已离职)展示了FSD的内部结构,可以看到特斯拉没有采用英伟达通常的CPU+GPU架构,而是采用高度定制的CPU+GPU+ASIC架构。
 特斯拉第一代FSD芯片架构
这里的ASIC指的便是占据整块芯片最大面积的两颗神经网络处理单元(NNA),即NPU。每颗NPU核的峰值性能可以达到每秒36.86万亿次运算(TOPS),功耗却只有7.5W。与之相比,GPU内核只提供0.6TOPS的算力,成为配角。
我们之前把CPU比做数学系教授,把GPU比做一年级本科生,那NPU就是CPU手下的在读博士,无需手把手指导,就能快速的进行卷积运算和矩阵乘法运算。简单来说就是:NPU成为提供算力输出的主力,CPU和GPU退居辅助位置。
HW3.0平台上配备了两颗FSD芯片,相互校对,相互冗余,整个系统的算力就是144TOPS,是前一代HW 2.5的7倍多(20TOPS)。而凭借颠覆性的架构设计,整个系统的功耗降低到了220W,功耗比则从0.067TOPS/W跃升至0.65TOPS/W。
FSD芯片让特斯拉实现了芯片的“独立自主”,此时离他们第一次购买Mobileye的产品只过去了短短5年。
而围绕自动驾驶“四要素”,特斯拉的突破还在继续。在2021年8月19日举行的特斯拉AI Day上,除了人工智能总监Andrej Karpathy详细阐述了基于视觉的神经网络方案外,”计算平台“的突破成果也被展示出来,即特斯拉Dojo ExaPOD超级计算机。
Dojo ExaPOD由120个训练模块组成,每一个训练模块包含25块特斯拉自研的D1芯片,总芯片数量达到了3000块。D1芯片由台积电代工,采用7nm工艺,3000块D1芯片叠加起来,直接让Dojo以1.1 EFLOP的算力成为全球第五大算力规模的计算机。
特斯拉第一代FSD芯片架构
这里的ASIC指的便是占据整块芯片最大面积的两颗神经网络处理单元(NNA),即NPU。每颗NPU核的峰值性能可以达到每秒36.86万亿次运算(TOPS),功耗却只有7.5W。与之相比,GPU内核只提供0.6TOPS的算力,成为配角。
我们之前把CPU比做数学系教授,把GPU比做一年级本科生,那NPU就是CPU手下的在读博士,无需手把手指导,就能快速的进行卷积运算和矩阵乘法运算。简单来说就是:NPU成为提供算力输出的主力,CPU和GPU退居辅助位置。
HW3.0平台上配备了两颗FSD芯片,相互校对,相互冗余,整个系统的算力就是144TOPS,是前一代HW 2.5的7倍多(20TOPS)。而凭借颠覆性的架构设计,整个系统的功耗降低到了220W,功耗比则从0.067TOPS/W跃升至0.65TOPS/W。
FSD芯片让特斯拉实现了芯片的“独立自主”,此时离他们第一次购买Mobileye的产品只过去了短短5年。
而围绕自动驾驶“四要素”,特斯拉的突破还在继续。在2021年8月19日举行的特斯拉AI Day上,除了人工智能总监Andrej Karpathy详细阐述了基于视觉的神经网络方案外,”计算平台“的突破成果也被展示出来,即特斯拉Dojo ExaPOD超级计算机。
Dojo ExaPOD由120个训练模块组成,每一个训练模块包含25块特斯拉自研的D1芯片,总芯片数量达到了3000块。D1芯片由台积电代工,采用7nm工艺,3000块D1芯片叠加起来,直接让Dojo以1.1 EFLOP的算力成为全球第五大算力规模的计算机。
 Dojo负责人Ganesh展示D1芯片,2021 AI Day
客观评价,特斯拉毕竟是芯片领域的“新兵”,自研的芯片未必真的能媲美半导体巨头,尤其是研发Dojo的成本比从英伟达直接买还要高。但考虑到特斯拉在几乎时零基础的情况下挤进了AI芯片第一梯队,这份成绩单还是足够优秀的。
自此“自己动手,丰衣足食”,马斯克对“四要素”的全链条掌控已经基本成型:
采用“纯视觉方案”,核心算法基于深度神经网络,在云端由自己研发的Dojo超级计算机进行训练,终端上自研的FSD芯片实时处理周围环境数据,识别对象,预测行为,作出判断,最后控制车辆动作,实现自动或半自动的“智能驾驶”。
为了加快自动驾驶的成熟速度,特斯拉在2020年10月启动了FSD Beta的内测,面向的人群是一小部分愿意把现实世界的行驶数据上传给特斯拉来进行算法训练和干山的车主,而采集到的大量数据则会被喂给“云端”的超级计算机来训练模型和算法。
大量花了15000美元选配FSD服务的车主愿意“自带干粮”给特斯拉充当“无人驾驶测试员”。2021年有2000多位车主参加了FSD Beta的内测;到2022年10月,这一数字飙升到了16万;之后FSD Beta向北美地区全部开放,参与车主数量达到36万。
Dojo负责人Ganesh展示D1芯片,2021 AI Day
客观评价,特斯拉毕竟是芯片领域的“新兵”,自研的芯片未必真的能媲美半导体巨头,尤其是研发Dojo的成本比从英伟达直接买还要高。但考虑到特斯拉在几乎时零基础的情况下挤进了AI芯片第一梯队,这份成绩单还是足够优秀的。
自此“自己动手,丰衣足食”,马斯克对“四要素”的全链条掌控已经基本成型:
采用“纯视觉方案”,核心算法基于深度神经网络,在云端由自己研发的Dojo超级计算机进行训练,终端上自研的FSD芯片实时处理周围环境数据,识别对象,预测行为,作出判断,最后控制车辆动作,实现自动或半自动的“智能驾驶”。
为了加快自动驾驶的成熟速度,特斯拉在2020年10月启动了FSD Beta的内测,面向的人群是一小部分愿意把现实世界的行驶数据上传给特斯拉来进行算法训练和干山的车主,而采集到的大量数据则会被喂给“云端”的超级计算机来训练模型和算法。
大量花了15000美元选配FSD服务的车主愿意“自带干粮”给特斯拉充当“无人驾驶测试员”。2021年有2000多位车主参加了FSD Beta的内测;到2022年10月,这一数字飙升到了16万;之后FSD Beta向北美地区全部开放,参与车主数量达到36万。
 一名北美用户正在使用FSD Beta,2022年
海量的数据投喂给日夜不停的超级计算机,带来了自动驾驶的快速迭代。在2022年的AI Day上,特斯拉给出了一组数据:采集了480万段数据,训练了75778个神经网络模型,其中有281个模型被实际用到特斯拉车上,推动FSD迭代了35个版本。
在披露这些数据前,马斯克在开场白中讲了一句话:基本上我认为,我们是人工智能在现实世界应用的无可争议的领导者。
在ChatGPT火爆全球之后,这句话的可信度显然打了不小的折扣。不过从2013年开始,特斯拉用了9年就吃透了人工智能的玩法,把AI搬上了数百万台汽车,从算法、芯片再到计算平台全部实现自研,基本上领先所有的竞争对手,包括卖铲子的英伟达。
一名北美用户正在使用FSD Beta,2022年
海量的数据投喂给日夜不停的超级计算机,带来了自动驾驶的快速迭代。在2022年的AI Day上,特斯拉给出了一组数据:采集了480万段数据,训练了75778个神经网络模型,其中有281个模型被实际用到特斯拉车上,推动FSD迭代了35个版本。
在披露这些数据前,马斯克在开场白中讲了一句话:基本上我认为,我们是人工智能在现实世界应用的无可争议的领导者。
在ChatGPT火爆全球之后,这句话的可信度显然打了不小的折扣。不过从2013年开始,特斯拉用了9年就吃透了人工智能的玩法,把AI搬上了数百万台汽车,从算法、芯片再到计算平台全部实现自研,基本上领先所有的竞争对手,包括卖铲子的英伟达。
 马斯克曾在微博称特斯拉的AI实力被“低估”
马斯克曾在微博称特斯拉的AI实力被“低估”
当然,争议始终伴随着特斯拉。一方面,L4级的自动驾驶难度过高,大量厂商被卡在L2级~L3级这一地带,即使特斯拉的FSD更新到v11版本,也仍然没有摆脱“Beta”的后缀。在今年2月初,特斯拉更是宣布召回了36万辆配备有FSD的汽车。
另一方面,特斯拉在营销”自动驾驶“时的激进也少不了被口诛笔伐,马斯克在推销自家的自动驾驶技术方面不仅接地气,而且接地府,吹牛、撕逼、PUA同行、期货当现货卖……无所不用其极。这种”表演“,有时候反而会让人忽略了特斯拉的真正实力。
但众所周知,特斯拉汽车在全球的热卖,目前跟自动驾驶关系不是很大,尤其在中国,FSD开通率只有可怜的2%不到,全球范围也只有10%~20%的水平。用户选择特斯拉汽车,更多的是因为品牌光环以及其在设计、制造、价格方面的优势。
而特斯拉之所以持续投资人工智能,除了本身自动驾驶是一大营销卖点外,还有一个原因:人工智能将是未来20年人类最重要的科技主线。
电动车产业虽然坐拥风口,但本质上仍然是制造业,效率曲线的改善会逐步趋缓。比如,动力电池的容量不会每年翻一番,一体化压铸的成本也不会每年下降50%,特斯拉在制造环节的优势在渡过红利期之后,迟早会被更卷的厂商追上。
但人工智能却像火箭一样在加速,并极有可能引爆一场像工业革命一样的浪潮。如果特斯拉能够从一家单纯的汽车公司,变成一家拥有两大落地场景(汽车和机器人)的人工智能公司,那么今天投入的每一分钱,未来都将是跟竞争者的巨大优势。
不过特斯拉在AI领域的狂飙,常常被一些戏谑性的场景所冲淡。2022年10月,被业界期待已久的Tesla Bot发布,但三名吃力抬着机器人上台的壮汉让场面一度尴尬。两个月后ChatGPT引爆全球,Tesla Bot彻底成为全球AI狂欢的背景板。
 被工作人员“抬”上来的Tesla Bot
OpenAI用ChatGPT告诉我们:人工智能的发展总是呈现非线性的,一旦“奇点”临近,爆发就会以难以想象的速度来临。谁都不敢妄言特斯拉测试两年多的FSD Beta不会在不远的未来取得突破,这台装了FSD芯片的机器人,也是一样。
从这角度出发,特斯拉这台电线裸露的Bot,是不是越看越像《复联2》的奥创或者施瓦辛格?
被工作人员“抬”上来的Tesla Bot
OpenAI用ChatGPT告诉我们:人工智能的发展总是呈现非线性的,一旦“奇点”临近,爆发就会以难以想象的速度来临。谁都不敢妄言特斯拉测试两年多的FSD Beta不会在不远的未来取得突破,这台装了FSD芯片的机器人,也是一样。
从这角度出发,特斯拉这台电线裸露的Bot,是不是越看越像《复联2》的奥创或者施瓦辛格?

尾声:向老乡预警,给硅基带路
在2003年上映的电影《终结者3》里,毁灭人类的超级计算机——天网的算力是60 TFlops。
二十年过去了,游戏玩家手上的一张RTX 4090显卡,就能达到100 TFlops,相当于1.67个天网;一张英伟达A100的算力(FP16)能够达到156TFlops,相当于2.6个天网,而ChatGPT背后的数据中心里,至少有2万张英伟达A100和性能更强的H100。
 《终结者3》里启动的SkyNet,2000年
人类在科技树的某一个枝桠上“狂飙”时,想象力可能都无法跟不上步伐。现在是2023年,Google发表那篇阐述“注意力机制”的论文,距今只有5年;AlphaGo击败李世石,距今只有7年;而OpenAI这家公司成立,距今也才不到8年时间。
特斯拉研发无人驾驶的时间线,跟人工智能这门科学在近10年的突飞猛进密不可分的,而人工智能的演进速度会越来越快。OpenAI创始人Sam Altman刚提了一个新的理论:新的摩尔定律将会开启,宇宙中的智能生命每隔18个月将会翻一倍。
《终结者3》里启动的SkyNet,2000年
人类在科技树的某一个枝桠上“狂飙”时,想象力可能都无法跟不上步伐。现在是2023年,Google发表那篇阐述“注意力机制”的论文,距今只有5年;AlphaGo击败李世石,距今只有7年;而OpenAI这家公司成立,距今也才不到8年时间。
特斯拉研发无人驾驶的时间线,跟人工智能这门科学在近10年的突飞猛进密不可分的,而人工智能的演进速度会越来越快。OpenAI创始人Sam Altman刚提了一个新的理论:新的摩尔定律将会开启,宇宙中的智能生命每隔18个月将会翻一倍。

在特斯拉投资者日公布的Master Plan 3(宏愿3)中,马斯克预期特斯拉未来每年能够生产2000万辆车——这也意味着,每年把2000万个拥有极强算力的硅基生命送到碳基人类的千家万户,同时这些终端的“智力”正在昼夜不停地进化。
电影《教父》里柯里昂说过说:离自己的朋友要近,离自己的敌人要更近。马斯克显然明白无法阻挡洪流,索性为硅基的崛起助力。至于这种“助力”,究竟是碳基通往自由之路上的砖石,还是绞刑架上的绳索,马斯克可能管不了那么多了。
一边向碳基老乡预警,一边给硅基皇军带路,马老师已经做出了自己的选择。我们呢?
(全文完,总长1.2万字,感谢您的耐心阅读。本文撰写得到了ChatGPT的大力协助,特此鞠躬。)
参考资料
[1]. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale, 2020
[2]. Elon Musk @twittter,2014-2018
[3]. South by Southwest Tech Conference, 2018
[4]. 汽车自动驾驶发展路径和产业链全景图, 未来智库
[5]. George Hotz Is Taking on Tesla by Himself, Bloomberg
[6]. Large-scale Deep Unsupervised Learning using Graphics Processors
[7]. Tesla AI Day, 2021-2022
[8]. 一个时代有一个时代的计算架构,量子位
[9]. 与时间赛跑,特斯拉Autopilot进化史,汽车之心
[10]. AI Chips: Challenges and Opportunities
[11]. ChatGPT幕后的真正大佬,量子学派
[12]. Meet The ‘Jedi Engineers’ Responsible For Tesla Autopilot
[13].新能源汽车的联发科时刻,远川研究所
[14]. 鸿蒙座舱是怎样炼成的,饭统戴老板
[15]. Deep Understanding Tesla FSD: Vector Space,Jason Zhang
来源|远川汽车评论(ID:yuanchuanqiche)



0 条评论