若将中国的AI发展看做是一本小说,你会发现,2023年用一页的篇幅,几近写完了曾经计算机视觉(CV)的三年:起风,落地,再到危机暗涌。
2022年末,太平洋对岸的ChatGPT石破天惊,拉开了名为AI大模型的全球竞速——热钱和人才集中涌向这个赛道。
这一年,中国模型层一共诞生了5家独角兽:智谱AI、MiniMax、百川智能、零一万物、月之暗面。无论是从头训,还是基于现成模型微调,国内约200个大模型加入“百模大战”,AI领域融资事件数比2022年增长了145%。
AI的技术突破,也为这个赛道吸纳了不少顶尖人才:来自国内外最高学府的知名学者教授下海,互联网老兵出山,谷歌、微软等海外大厂出身的华人回国。
但与热闹和振奋人心的技术突破相对的,是疲软的资本市场和紧缺的资源。美元基金的退出、英伟达芯片的禁运,倒逼AI企业内修功力、外寻新机:找场景快速落地,出海拓展商业机会。
从锤炼技术,到快速的商业化落地,也将更为抽象的问题摆到AI厂商面前:如何找准落地场景?如何实现数据飞轮?
从Copilot到AI Agent(智能体),热门概念和demo的不断涌现,让市场对AI的能力充满了想象。但较为残酷的现实是,囿于底层模型的能力,AI能落地的场景仍然有限。
从模型层相关的多模态、幻觉问题,到硬件层面的NPU(神经元计算处理器),AI产业上下游要解决的技术难点还有很多。对于应用厂商而言,则要根据技术现状将落地场景加以细分,或者找到具有独特价值的落地场景。
即便度过了机会和危机并存的2023,没人怀疑,2024年,AI依然会是舞台上的主角。
开年的“王炸”,依然来自OpenAI——北京时间2024年2月16日,OpenAI推出了可以生成60秒连贯流畅、超逼真的高清视频的视频生成模型Sora。对于不少视频模型的创业公司而言,“灭霸”OpenAI的开年响指并不好受。但业内更多人认为,视频等多模态模型,将在2024年创造新的商机。
而市场,也已经做好了迎接AI商业化的准备。经历三年疲软的消费市场,在2023年Q3终于复苏。在硬件层面,手机、PC等消费电子的销量回升有目共睹。在软件应用层面,根据移动市场分析平台data.ai的统计,2023年全球移动市场用户的支出同比增长了3%——截至2023年末,生成式AI应用的月用户支出也突破了1000万美元。
2023年下半年以来,出海淘金,也成了不少AI厂商拓展商业机会的方式。无论是在新环境中寻求资本,还是寻找具有更高付费能力和意愿的客户,不少国内的AI厂商提起出海,都给予36氪同样的答复:“Why not?”
2024年,关于大模型的机会、应用落地的方向、做ToB还是ToC、本地化还是出海,36氪总结了6大趋势。
语言日渐拥挤,视听乘风起势
即便模型层短时间内诞生了5家独角兽,但企名Pro的数据显示,2023年AI领域的融资总额比2022年少了4.5%,甚至还不到2021年的一半。
这意味着,热钱集中地涌向了少数团队背景和技术实力强大的公司。从资源分配的角度而言,后来者想要再挤进模型层创业,空间已经不多。
智谱AI CEO张鹏认为,从商业竞争的角度而言,2024年LLM赛道已经接近红海:“一,算力等资源紧张的问题还没有解决;二,从市场空间的角度而言,不需要重复造轮子;三,模型能力很大程度上依赖先发优势,积累用户反馈、行程数据,从技术迭代的角度,后来者很难跟上主流的水平。”
即便零一万物内部的模型训练研究显示,模型参数量还有很大的提高空间,在零一万物技术副总裁、Pretrain(预训练)负责人黄文灏看来,目前模型层的困难主要是在算力资源上:
“从GPT3.5到GPT4有大量的技术挑战要解决,算力资源限制会减少迭代试错的机会,大家都会选择确定性较高的路径,就错过了一些创新的机会。”
红海中,永恒不变的只有顶级人才的号召力。远识资本董事Yuca对36氪表示,基金不会把鸡蛋放在同个篮子里,OpenAI、微软、谷歌这些顶级公司的华人专家,还存在撬动国内资源的可能。
LLM赛道日渐拥挤,但3D、视听等多模态模型仍是一片蓝海。
月之暗面联合创始人周昕宇向36氪列举了不少模型有待突破的底层技术,其中不少与多模态有关,比如如何对多模态数据进行统一表示;如何用计算来突破数据的瓶颈;如何研发出更高效的多模态无损压缩神经网络架构。他认为,这些技术突破都可能成为2024年模型层公司的机会,但也可能需要更长时间才能取得突破。
多模态能力的突破,也将给大模型的整体能力带来超预期的提升。“由于大模型的泛化性,能力迭代往往是通用的、全面的提高,不会是单点的突破。”黄文灏告诉36氪,“无论是图片还是音频,多模态数据会和文字形成1+1>2的效果。”
不过,3D和视听生成技术在2023年的迭代速度之快,已让人瞥见2024年的商业化浪潮。以技术复杂的视频生成为例,2023年初,视频生成模型尚且只能将多个静止的图像拼接成几秒长的剪辑。但不到6个月,以Runway Gen2为代表的模型就能生成几秒长的电影级影片。
时间再来到同年11月,由4名华人创立的动画视频生成公司Pika,就释出了可以生成分钟级高质动画视频的产品。Pika的估值,也飙升至近2亿美元。
而仅仅再过了3个月,2024年2月16日,“灭霸”OpenAI又杀死了视频生成的游戏,发布可以生成60秒连贯高清视频的文生视频模型Sora。这也意味着,视频生成模型距离商用,已经近在咫尺。
LLM解决的是最基本的交流问题,而3D、视听等多模态则能让AI模型拥有超人类的感官,应用创新和模式创新的机会远多于LLM。
多模态技术能落地的场景,大致可以分成两类:一类是提供生产力工具,另一类则是提供新场景。
在工作和生产场景下,模型服务的商业模式已经较为成熟,但这也意味着入局者众多,竞争压力更大。企业的核心竞争力在于能否建立全流程服务,满足用户的细分需求,同时形成数据飞轮。
随着多模态技术的提升,不少人在智舱、物联网、XR等场景中看到了新机会。对于新场景的创业者而言,跑通商业模式的先决条件,则是寻找到具有独特价值的细分场景。
 模型“瘦身”,先场景后模型
但通用基座的红海,并不意味着模型层已经失去入局的空间。
一个明显的趋势是,随着应用落地的加速,不少中小模型厂商开始“瞄准钉子挥锤子”,先找到能落地的细分场景,再针对性地训练模型。
这一现象,与市场的反馈不无关系。应用落地的迫切性,让下游厂商比起更强大的通用性能,更关切模型调用的成本,以及在端侧部署的可能性。
由于模型推理需要消耗的算力巨大,来自底层的成本压力会层层传导至下游。以OpenAI为例,根据美国金融公司 Bernstein 的分析,如果ChatGPT的访问量达到谷歌浏览器的十分之一,OpenAI 初始需要的GPU价值高达481亿美元——这部分的成本也势必会分摊到下游的应用厂商。
降本最直接的方式,是减少模型的参数量。2023年下半年以来,不少拥有千亿级参数基座的模型厂商,都发布了十亿级参数的模型。比如百川智能发布了7B的语言模型,智谱AI和零一万物发布了6B的模型版本,用纯CPU就能将模型跑起来。
但光“瘦身”,不足以成为模型厂商的竞争力。其缘由在于,各家大模型的能力尚未产生明显差距。远识资本董事Yuca举了一个例子:在国外,所有应用厂商优先考虑的模型一定是GPT-4;但在国内,应用厂商挑不出一个出类拔萃的,一般会考虑把十几个主流模型都先试试。
“现在谈大模型的竞争力还为时尚早。”网易有道CEO周枫对36氪表示,“核心是要从应用中找到千亿级的市场机会,找到‘大模型原生’的产品形态是关键。”
他以有道的长项翻译场景为例,虽然有道自研的百亿参数模型“子曰”整体对话能力不如千亿参数的ChatGPT,但通过基于向量数据库的训练,“子曰”能够5秒翻译67页长论文。
即便认为“现在谈大模型的竞争力还为时尚早”的判断还有待商榷,智谱AI CEO张鹏在模型落地层面,表达了类似的观点:“落地阶段最重要的是找对场景,培养用户,形成数据飞轮。”
培养用户,越早越好。月之暗面联合创始人周昕宇告诉36氪,从新技术的扩散曲线来看,最早期的用户和开发者会带动更多的用户:“2023年可以吸取的经验教训是,应该更早点儿给用户去用,很多用户自己会探索大模型产品的边界,发现产品经理想不到的场景和应用。2024年,AI落地的重点是如何与用户一起成长。”
一个通过找对场景,顺利在模型层占有一席之地的典型案例,是估值达5.2亿美元的AI公司Perplexity。Perplexity通过将大模型和搜索引擎结合,开发出了类似于New Bing的对话式搜索引擎。
不过,Perplexity的模型,最初是基于一些规模更小、推理更快的模型进行微调而来。直到最近,他们才开始训练自己的模型。
对于前期“套壳”的决定,Perplexity CEO Aravind Srinivas在播客节目中锐评:“成为一个拥有十万用户的套壳产品,显然比拥有自有模型却没有用户更有价值。”
模型“瘦身”,先场景后模型
但通用基座的红海,并不意味着模型层已经失去入局的空间。
一个明显的趋势是,随着应用落地的加速,不少中小模型厂商开始“瞄准钉子挥锤子”,先找到能落地的细分场景,再针对性地训练模型。
这一现象,与市场的反馈不无关系。应用落地的迫切性,让下游厂商比起更强大的通用性能,更关切模型调用的成本,以及在端侧部署的可能性。
由于模型推理需要消耗的算力巨大,来自底层的成本压力会层层传导至下游。以OpenAI为例,根据美国金融公司 Bernstein 的分析,如果ChatGPT的访问量达到谷歌浏览器的十分之一,OpenAI 初始需要的GPU价值高达481亿美元——这部分的成本也势必会分摊到下游的应用厂商。
降本最直接的方式,是减少模型的参数量。2023年下半年以来,不少拥有千亿级参数基座的模型厂商,都发布了十亿级参数的模型。比如百川智能发布了7B的语言模型,智谱AI和零一万物发布了6B的模型版本,用纯CPU就能将模型跑起来。
但光“瘦身”,不足以成为模型厂商的竞争力。其缘由在于,各家大模型的能力尚未产生明显差距。远识资本董事Yuca举了一个例子:在国外,所有应用厂商优先考虑的模型一定是GPT-4;但在国内,应用厂商挑不出一个出类拔萃的,一般会考虑把十几个主流模型都先试试。
“现在谈大模型的竞争力还为时尚早。”网易有道CEO周枫对36氪表示,“核心是要从应用中找到千亿级的市场机会,找到‘大模型原生’的产品形态是关键。”
他以有道的长项翻译场景为例,虽然有道自研的百亿参数模型“子曰”整体对话能力不如千亿参数的ChatGPT,但通过基于向量数据库的训练,“子曰”能够5秒翻译67页长论文。
即便认为“现在谈大模型的竞争力还为时尚早”的判断还有待商榷,智谱AI CEO张鹏在模型落地层面,表达了类似的观点:“落地阶段最重要的是找对场景,培养用户,形成数据飞轮。”
培养用户,越早越好。月之暗面联合创始人周昕宇告诉36氪,从新技术的扩散曲线来看,最早期的用户和开发者会带动更多的用户:“2023年可以吸取的经验教训是,应该更早点儿给用户去用,很多用户自己会探索大模型产品的边界,发现产品经理想不到的场景和应用。2024年,AI落地的重点是如何与用户一起成长。”
一个通过找对场景,顺利在模型层占有一席之地的典型案例,是估值达5.2亿美元的AI公司Perplexity。Perplexity通过将大模型和搜索引擎结合,开发出了类似于New Bing的对话式搜索引擎。
不过,Perplexity的模型,最初是基于一些规模更小、推理更快的模型进行微调而来。直到最近,他们才开始训练自己的模型。
对于前期“套壳”的决定,Perplexity CEO Aravind Srinivas在播客节目中锐评:“成为一个拥有十万用户的套壳产品,显然比拥有自有模型却没有用户更有价值。”
不过在未来,自训模型仍然会成为AI应用企业不可缺失的一环。“AI公司的核心竞争力会是模型、应用、infra‘三位一体’的能力。最大的应用公司必须掌握模型训练能力,模型的推理成本降低对应用是最大的提升。三者缺一不可。”零一万物技术副总裁、Pretrain(预训练)负责人黄文灏对36氪表示。
 可穿戴,家居……AI托举细分硬件
2024年,将是AI硬件元年——这一判断,已经出现在国内外不少厂商的年初展望中:
高通总裁兼CEO Cristiano Amon在接受媒体采访时表示,2024年将成为全球AI手机元年;联想集团CEO杨元庆将2024年视为“AI PC出货元年”;OPPO高级副总裁刘作虎在发布会上直言:“2024 年,不布局大模型的手机企业未来没戏。”
不少硬件厂商,将AI大模型视作消费电子低迷三年后的一根“救命稻草”。但厂商们将AI从云端转移至终端设备,有着更为现实的考量——在大模型和终端的适配标准尚未建立之时,押注下一个入口型智能硬件,争先建立继IOS、安卓、Windows之后AI OS(操作系统)。
比如1月10日,荣耀发布了新一代AI系统MagicOS 8.0,用“端云协同”作为AI生态的卖点。在CES(国际电子消费展)上,联想透露预计在2024年内发布“智能终端AI OS(操作系统)”。“Windows老家”微软,也宣布将AI助手Copilot键引入Windows 11 PC,并将其描述为“AI PC的第一步”。
但无论是PC、手机,还是汽车,这些具有复杂软硬件生态的智能终端,与大模型的结合仍然差一口气。
其一,被赋予“高效率、低能耗”厚望的硬件“大脑”——NPU(神经网络处理器)芯片,仍处于研发初期。大模型接入智能终端后,能耗和运行效率问题依然难以解决。
其二,囿于大模型能力和硬件不统一的适配协议,AI在智能终端上能落地的场景仍然有限。面壁智能CTO曾国洋告诉36氪,终端标准协议的建立,是全球软硬件厂商之间的博弈,很难预判胜者是谁。
相对地,瞄准垂直场景的设备,在结合AI模型后反而迅速开辟了市场。
在作为“科技市场风向标”的北美,AI硬件迅速崛起的消费趋势已经证明了这一点。
比如在CES 2024首秀的橙色盒子Rabbit R1,可以代理人类完成对手机的操作。发售首日,第一批的1万台机子就迅速售罄。在北美电子产品购物平台ebay上,甚至有人加价几百美元,靠拍卖Rabbit R1谋利。
可穿戴,家居……AI托举细分硬件
2024年,将是AI硬件元年——这一判断,已经出现在国内外不少厂商的年初展望中:
高通总裁兼CEO Cristiano Amon在接受媒体采访时表示,2024年将成为全球AI手机元年;联想集团CEO杨元庆将2024年视为“AI PC出货元年”;OPPO高级副总裁刘作虎在发布会上直言:“2024 年,不布局大模型的手机企业未来没戏。”
不少硬件厂商,将AI大模型视作消费电子低迷三年后的一根“救命稻草”。但厂商们将AI从云端转移至终端设备,有着更为现实的考量——在大模型和终端的适配标准尚未建立之时,押注下一个入口型智能硬件,争先建立继IOS、安卓、Windows之后AI OS(操作系统)。
比如1月10日,荣耀发布了新一代AI系统MagicOS 8.0,用“端云协同”作为AI生态的卖点。在CES(国际电子消费展)上,联想透露预计在2024年内发布“智能终端AI OS(操作系统)”。“Windows老家”微软,也宣布将AI助手Copilot键引入Windows 11 PC,并将其描述为“AI PC的第一步”。
但无论是PC、手机,还是汽车,这些具有复杂软硬件生态的智能终端,与大模型的结合仍然差一口气。
其一,被赋予“高效率、低能耗”厚望的硬件“大脑”——NPU(神经网络处理器)芯片,仍处于研发初期。大模型接入智能终端后,能耗和运行效率问题依然难以解决。
其二,囿于大模型能力和硬件不统一的适配协议,AI在智能终端上能落地的场景仍然有限。面壁智能CTO曾国洋告诉36氪,终端标准协议的建立,是全球软硬件厂商之间的博弈,很难预判胜者是谁。
相对地,瞄准垂直场景的设备,在结合AI模型后反而迅速开辟了市场。
在作为“科技市场风向标”的北美,AI硬件迅速崛起的消费趋势已经证明了这一点。
比如在CES 2024首秀的橙色盒子Rabbit R1,可以代理人类完成对手机的操作。发售首日,第一批的1万台机子就迅速售罄。在北美电子产品购物平台ebay上,甚至有人加价几百美元,靠拍卖Rabbit R1谋利。
 Rabbit R1
Rabbit R1
事实证明,只要抓住用户的痛点,再垂直的场景都能带来巨大的财富。
比如AI+戒指——售价349美元(约2507.31元)的AI戒指Gen3,主打健康检测,其母公司OuraRing估值高达25.5亿美元;
AI+跑鞋——由AI驱动的跑鞋Moonwalker,能够在不改变正常步行方式的情况下将步行速度提高250%,即便预售价高达999美元(约7177.09元),在Kickstarter上也有570人参与众筹,募款额达到目标金额(9万美元)的近6倍;
AI+徽章——得到微软和OpenAI投资的Humane,推出了一款内嵌GPT的AI别针AI Pin,主打通过手势交互调用通讯、搜索、播放音乐等不同功能,预定量已经超过450万台。
#AI Pin的搜索功能
以北美为鉴,不少业内人士认为,健康监测、家庭陪伴等被北美市场验证的场景,在2024年会马上在国内被复制。
而在具有中国特色的场景中,最被看好的则是学习和翻译。
回答的准确率,以及情绪价值的提供,一直是大众对AI教学、翻译能力的主要质疑点。但真金实银是最真实的市场反馈:接入“星火大模型”后,讯飞学习机、智能办公本、翻译机等产品在双十一全周期内销售额同比增长126%;网易有道首款搭载大模型功能的有道词典笔X6 pro,产品首发日销量超4万台,开学季销售额超1亿元。
在远识资本董事Yuca看来,在学习场景下,中国用户天然处于已经被教育好的状态:学习硬件的用户画像主要为中小学生群体,这一群体的特征是乐于接受AI科技等新鲜事物,且对授课方式敏感度不高。在知识类数据库(比如教材、真题)较为透明的情况下,AI的准确率也得以保证,甚至稳定性高于人类教师。
而AI翻译产品可辐射的用户,比学生更广。Yuca认为,随着旅游市场复苏、签证门槛放低,跨国交流成为刚需。随着AI能力的发展,耳机等不同形态的翻译设备也将率先走进口音/特定声音识别能力、同传速度这两个战场。
“个性化分析和指导、引导式学习、全学科知识整合。”谈及AI能给学习硬件带来的新机会,网易有道CEO周枫认为有三点。在教育场景中,这些功能的提升原被认为只有人才能做到,而随着多模态能力的提升、Agent的发展,大模型在细分场景中更具有“拟人”的能力。
 留住用户,拼全流程服务
2023年,不少AI应用快速起高楼,又迅速如昙花一现:
提供文案、图片生成等AI营销工具的Jasper,在2022年底估值一度高达15亿美元,拥有100万总用户和7万付费用户。但仅过了半年,Jasper用户量锐减,面向员工的股票估值打了8折,并开启裁员;
在国内红极一时的AI写真生成应用“妙鸭相机”,高峰期排队人数高达4000-5000人,等待时间要十几个小时。但根据七麦数据,上线不到4个月,伴随着创始人的离职,妙鸭相机在IOS“社交”应用榜单上的排名,从榜首一路下滑到60开外。
不少AI应用都难以逃脱“倒U型”用户量曲线的魔障。其核心原因有二:底层技术没有壁垒,同质化产品易复制;服务链条短,用户难以对工具生态产生依赖。
留住用户,拼全流程服务
2023年,不少AI应用快速起高楼,又迅速如昙花一现:
提供文案、图片生成等AI营销工具的Jasper,在2022年底估值一度高达15亿美元,拥有100万总用户和7万付费用户。但仅过了半年,Jasper用户量锐减,面向员工的股票估值打了8折,并开启裁员;
在国内红极一时的AI写真生成应用“妙鸭相机”,高峰期排队人数高达4000-5000人,等待时间要十几个小时。但根据七麦数据,上线不到4个月,伴随着创始人的离职,妙鸭相机在IOS“社交”应用榜单上的排名,从榜首一路下滑到60开外。
不少AI应用都难以逃脱“倒U型”用户量曲线的魔障。其核心原因有二:底层技术没有壁垒,同质化产品易复制;服务链条短,用户难以对工具生态产生依赖。
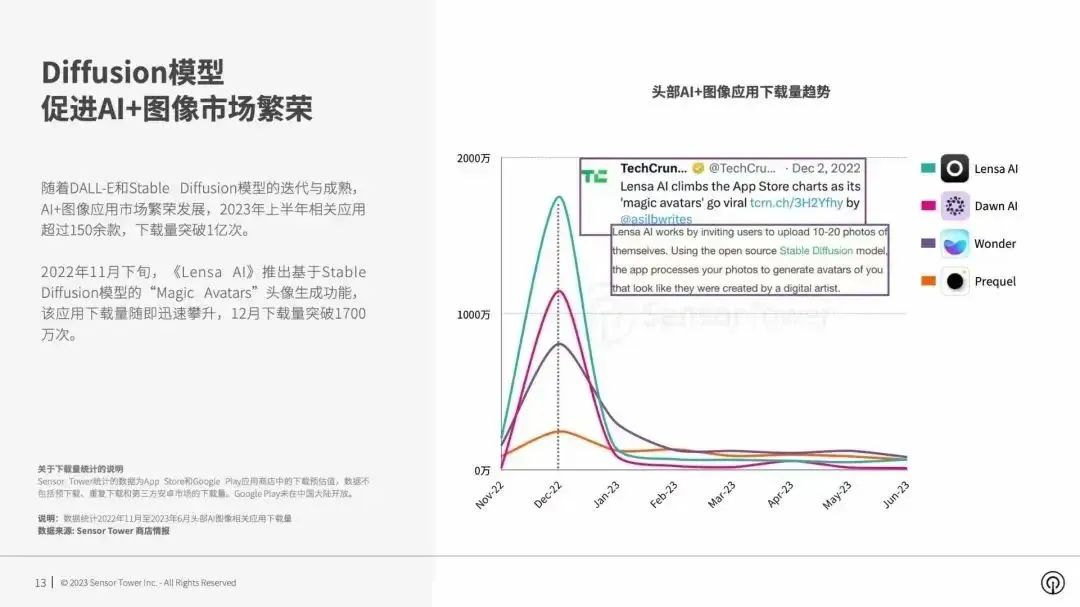 海外头部AI图像生成应用下载趋势,图源:Sensor Tower
“像妙鸭一样的AI软件应用,可以通过巧妙的营销或者获客方式快速起量。但想要维持用户增长,超越美图、Photoshop这样的产品,核心在于妙鸭们能否将服务,快速迭代到全流程的水平。”远识资本董事Yuca向36氪举了个例子:
妙鸭相机通过更精细的AI写生生成技术,快速聚集了一波用户。但妙鸭的服务链条仅限于照片生成,具有修图、编辑等需求的用户,又会回到美图和Photoshop的服务生态。
AI应用的用户留存思路,本质上与任何产品的发展并无二致:找到一个解决刚需的场景,完善全流程的服务链条,不断迭代更新IP,拓展使用场景。
找场景和IP迭代,可以被视作产品不同发展阶段的流量入口。比如在《芭比》电影上映期间,AI写真小程序“45 AI”,靠首发芭比模板在两天内聚集了2万多用户,美图秀秀等老牌美图软件也紧随其后上线芭比模板。而春节将至,ChatMind、MiniMax等团队也快速在AI社交产品上,针对年轻人更新了亲戚拜年的闯关场景。
对不少产品来说,找到合适的流量入口不难,但用全流程服务和更广的场景承接流量并不简单。
例如,线上服务,需要从满足单点功能,延伸到涵盖使用前、中、后的全流程,比如针对想要体验写真生成的用户,企业还要满足他们后续修图、美颜的需求。当线上服务场景已经涵盖全流程,就要考虑往线下场景延伸,比如将AI功能嵌入多形态的硬件设备中。
海外头部AI图像生成应用下载趋势,图源:Sensor Tower
“像妙鸭一样的AI软件应用,可以通过巧妙的营销或者获客方式快速起量。但想要维持用户增长,超越美图、Photoshop这样的产品,核心在于妙鸭们能否将服务,快速迭代到全流程的水平。”远识资本董事Yuca向36氪举了个例子:
妙鸭相机通过更精细的AI写生生成技术,快速聚集了一波用户。但妙鸭的服务链条仅限于照片生成,具有修图、编辑等需求的用户,又会回到美图和Photoshop的服务生态。
AI应用的用户留存思路,本质上与任何产品的发展并无二致:找到一个解决刚需的场景,完善全流程的服务链条,不断迭代更新IP,拓展使用场景。
找场景和IP迭代,可以被视作产品不同发展阶段的流量入口。比如在《芭比》电影上映期间,AI写真小程序“45 AI”,靠首发芭比模板在两天内聚集了2万多用户,美图秀秀等老牌美图软件也紧随其后上线芭比模板。而春节将至,ChatMind、MiniMax等团队也快速在AI社交产品上,针对年轻人更新了亲戚拜年的闯关场景。
对不少产品来说,找到合适的流量入口不难,但用全流程服务和更广的场景承接流量并不简单。
例如,线上服务,需要从满足单点功能,延伸到涵盖使用前、中、后的全流程,比如针对想要体验写真生成的用户,企业还要满足他们后续修图、美颜的需求。当线上服务场景已经涵盖全流程,就要考虑往线下场景延伸,比如将AI功能嵌入多形态的硬件设备中。
在用户留存层面,2023年能带给2024年的经验教训是:靠一个强大的AI功能并不能一劳永逸。毕竟,人类专业摄影师也难求一稿包过,根据用户的需求后期精修才是常态。
 用To C的思维,做To B服务
2023年,大模型落地很快产生了To B和To C的分野。
选择To B场景,大多离不开企业基因和商业化两个原因。智谱AI CEO张鹏谈及选择To B的原因,是公司成立初期已经原始积累了一批企业客户资源,“To B是商业化能够比较快跑起来的途径”。
选择To B或是To C,也有产品迭代和建立数据飞轮的考量。作为为数不多坚定To C的大模型公司,月之暗面的理由是:迭代效率。月之暗面CEO杨植麟曾在公开采访中表示,这是一个“以终为始”的选择,月之暗面的“终”是探索智能边界,做个性化,反推适合的人才结构、产品策略的“始”,就是To C。
“从长远来看,成功的商业策略应当是To B与To C并重,构建起既能满足企业和组织需求,又能贴近广大消费者的产品和服务生态体系。”零一万物技术副总裁、Pretrain(预训练)负责人黄文灏告诉36氪。在他看来,To B和To C业务对模型迭代能力的影响各有侧重。
“通常来说,To B业务因其专业性强、定制化需求多等特点,在企业服务方面已经相对成熟。To B业务收集数据的速度虽然较慢,但所处理的数据通常更为结构化、质量更高,对于特定行业知识的学习与积累有着不可替代的优势。”黄文灏表示,“而To C业务,由于用户基数大、交互频繁且应用场景多元化,确实更容易形成数据飞轮效应。同时,由于消费者对新技术接受度高,创新扩散速度快,从而吸引更多的新用户,形成良性循环。”
然而在模型落地的实际过程中,不少厂商发现,To C和To B的边界正在逐渐模糊。
智谱AI CEO张鹏告诉36氪,大模型To B和以往的To B服务模式并不同。以往的B端服务,主要满足的是来自企业的业务流程标准化的需求。但大模型的智能能力提升后,企业对To B服务的需求,扩展到了工作提效、员工助手、知识培训等聚焦于个体服务的场景。
“即便是做业务相关的AI Agent,最终的用户是员工个体,服务的其实还是C端群体。”张鹏解释。
什么叫做To C思维?在月之暗面联合创始人周昕宇看来,“用户会为对自己有帮助的产品直接买单。”与传统To B倡导服务的标准化不同,To C服务需要满足不同用户的个性化需求。甚至于,To C产品需要根据用户的使用习惯进行不断迭代,个性化的迭代会贯穿用户完整的使用周期。
不过,对于To B模型厂商而言,想要长久盈利,就必须提供标准化服务。
远识资本董事Yuca认为,国内数字化预算主要集中在大客户手中。目前对大模型厂商而言,服务大客户的定制化服务利润最高,但付出人力时间成本高,回款周期长,且只有极少部分大客户能够承担。
不少To B模型厂商,开始寻找能实现个性化服务的标准技术路径。比如,国内外已有不少厂商在To B大模型服务中引入RAG(检索增强生成)流程,实现对企业的个性化服务。RAG就好似大模型与企业私有数据库之间的“传声筒”,随着私有数据库的更新,相应的模型服务也会随之更迭。
用To C的思维,做To B服务
2023年,大模型落地很快产生了To B和To C的分野。
选择To B场景,大多离不开企业基因和商业化两个原因。智谱AI CEO张鹏谈及选择To B的原因,是公司成立初期已经原始积累了一批企业客户资源,“To B是商业化能够比较快跑起来的途径”。
选择To B或是To C,也有产品迭代和建立数据飞轮的考量。作为为数不多坚定To C的大模型公司,月之暗面的理由是:迭代效率。月之暗面CEO杨植麟曾在公开采访中表示,这是一个“以终为始”的选择,月之暗面的“终”是探索智能边界,做个性化,反推适合的人才结构、产品策略的“始”,就是To C。
“从长远来看,成功的商业策略应当是To B与To C并重,构建起既能满足企业和组织需求,又能贴近广大消费者的产品和服务生态体系。”零一万物技术副总裁、Pretrain(预训练)负责人黄文灏告诉36氪。在他看来,To B和To C业务对模型迭代能力的影响各有侧重。
“通常来说,To B业务因其专业性强、定制化需求多等特点,在企业服务方面已经相对成熟。To B业务收集数据的速度虽然较慢,但所处理的数据通常更为结构化、质量更高,对于特定行业知识的学习与积累有着不可替代的优势。”黄文灏表示,“而To C业务,由于用户基数大、交互频繁且应用场景多元化,确实更容易形成数据飞轮效应。同时,由于消费者对新技术接受度高,创新扩散速度快,从而吸引更多的新用户,形成良性循环。”
然而在模型落地的实际过程中,不少厂商发现,To C和To B的边界正在逐渐模糊。
智谱AI CEO张鹏告诉36氪,大模型To B和以往的To B服务模式并不同。以往的B端服务,主要满足的是来自企业的业务流程标准化的需求。但大模型的智能能力提升后,企业对To B服务的需求,扩展到了工作提效、员工助手、知识培训等聚焦于个体服务的场景。
“即便是做业务相关的AI Agent,最终的用户是员工个体,服务的其实还是C端群体。”张鹏解释。
什么叫做To C思维?在月之暗面联合创始人周昕宇看来,“用户会为对自己有帮助的产品直接买单。”与传统To B倡导服务的标准化不同,To C服务需要满足不同用户的个性化需求。甚至于,To C产品需要根据用户的使用习惯进行不断迭代,个性化的迭代会贯穿用户完整的使用周期。
不过,对于To B模型厂商而言,想要长久盈利,就必须提供标准化服务。
远识资本董事Yuca认为,国内数字化预算主要集中在大客户手中。目前对大模型厂商而言,服务大客户的定制化服务利润最高,但付出人力时间成本高,回款周期长,且只有极少部分大客户能够承担。
不少To B模型厂商,开始寻找能实现个性化服务的标准技术路径。比如,国内外已有不少厂商在To B大模型服务中引入RAG(检索增强生成)流程,实现对企业的个性化服务。RAG就好似大模型与企业私有数据库之间的“传声筒”,随着私有数据库的更新,相应的模型服务也会随之更迭。
2024年,To B模型厂商抓住金字塔尖的大客户依然重要,Yuca补充,“不同ToB行业有极高的行业壁垒,如何切入高行业壁垒的大客户也是需要思考的问题”。但位于塔身的广大客群,是目前To B模型厂商立身的富矿。
 出海,淘金
如今,出海成了不少国内AI厂商无奈又为之振奋的抉择。
出海,淘金
如今,出海成了不少国内AI厂商无奈又为之振奋的抉择。
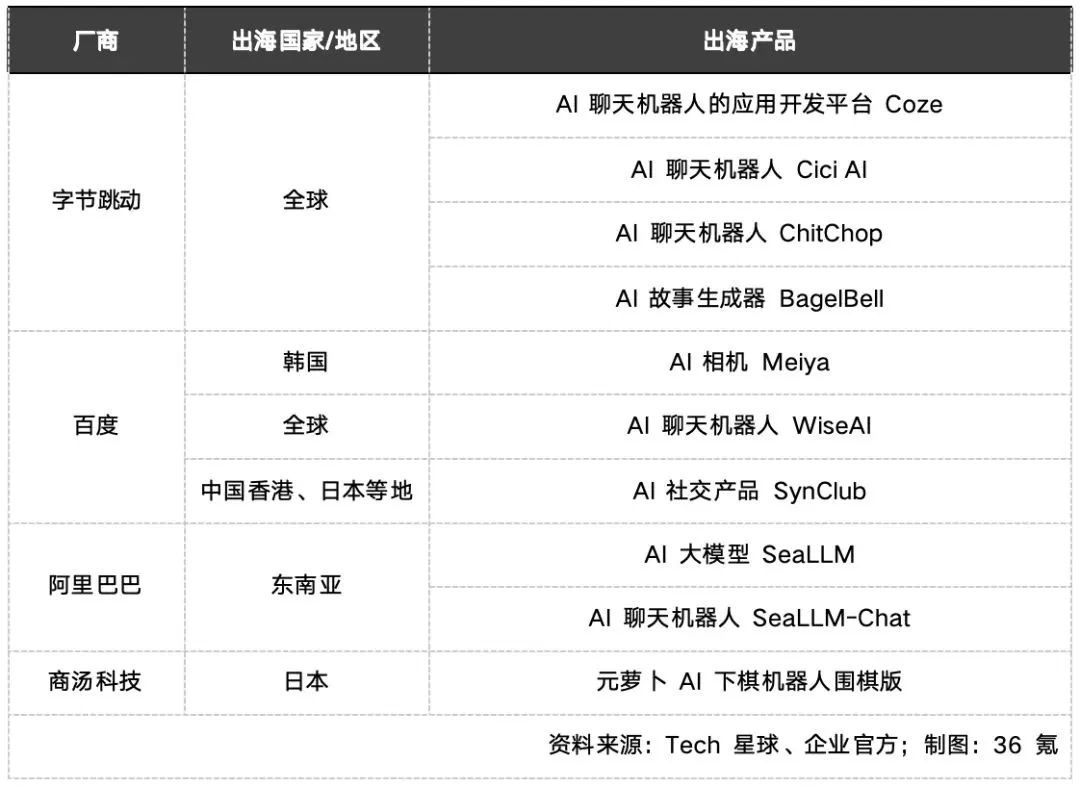 中国互联网公司的海外AI产品
中国互联网公司的海外AI产品
在美元基金退出、芯片供应受阻的大背景下,AI厂商在国内融资、训练模型的难度骤增。据不完全统计,在国内,2023年上半年融到钱的大模型企业大概有20多家,但下半年数量骤减至不到1/2——钱早已涌向了少数大模型的早期玩家,后来者的处境并不乐观。
站在基金的角度,远识资本董事Yuca告诉36氪,由于时局并不明朗、IPO充满不确定性,基金更在意如何在IPO前顺利退出,并且从中获利:“海外市场收并购相对国内成熟,出海项目存在收并购可能性较国内高很多,相比走IPO的独木桥,对基金来说退出更容易一些。”
相较于国内,海外,尤其是北美,企业之间的收并购更为常见。据数据分析公司GlobalData统计,在2016年到2020年期间,苹果一共收购了25家AI公司,谷歌收购了14家,微软收购了12家。
被这些大厂收购后,创业者依然能够选择二次创业。比如,曾为苹果员工的Adam Menges,在创办的两家公司分别被微软和Niantic收购后,他又加入了AI设计初创企业Visual Electric,获得了红杉的投资。
而出海更令人振奋的原由,莫过于海外有着近中国14倍规模的AI市场。IDC的报告显示,2022年中国AI软件市场规模为307亿元,全球则为640亿美元(约4606.4亿元)。
同时,在全球成本差异不大的前提下,由于付费能力和付费意识的差异,同样产品在海外的利润率将高得多。以Apple Music为例,同样的音乐服务,美国的订阅费是10美元/月(约71.93元/月),是中国订阅费(10元/月)的7倍。
至于模型服务,智谱AI CEO张鹏认为,海外客户对标准化的接受程度更高,但国内客户更倾向于选择定制化,这导致模型服务在国内的ROI(投资回报率)并不高。不少受访者的观点是,只要能和OpenAI、微软等大厂形成服务或者价格上的差异化优势,出海对于To B模型厂商而言能够拓展更多商业机会。
此外,一个不得不承认的事实是,国内大模型与GPT-4的客观差距仍然存在。但目前,GPT-4等部分高性能模型无法进入国内市场。在海外,依托于更高性能的模型底座,AI厂商能够实现更多的应用创新和模式创新。
在与国外厂商技术差距可控的前提下,中国AI厂商出海的天然优势,则在于对渠道和价格的把控能力。
对于AI软件厂商,尤其是To C应用而言,经受国内社交+电商+视频三位一体的复杂获客渠道的捶打,面对国外以亚马逊、Instagram等独立平台为主的渠道生态,就从容了许多。“能在国内这么卷的渠道环境中杀出来的,在国外一定不会差。”一名在北美的AI创业者对36氪判断。
对于AI硬件厂商而言,极致性价比依然是收割海外客户的利器。即便全球供应链正在往东南亚转移,但核心部件的生产技术专利仍然把握在中国厂商手中。AI硬件厂商能够通过供应链优势,在海外市场把握定价权。
不过,厂商们也要清楚地认识到,海外市场与国内市场存在不小的差异,这会全方位地影响产品定位、UI设计、训练数据、团队建设。将本地化产品或者团队1:1复刻到海外,结局大多是水土不服、铩羽而归。
比如对于AI绘画软件,国内用户偏爱国风模板,但海外用户则更偏爱漫威和3D。在国内,To B的AI公司需要建立相当规模的工程化团队,以满足客户的定制化需求,但在标准化接受程度高的海外,AI公司反而要放更多精力在底层技术打磨,以及建立高水平的销售团队上。
如今,一批国内大厂已经用AI瞄准了海外市场,而不少AI初创企业的出海财富故事,也已在业内流传:
由西南财经大学计算机教授段江创立的AI图片编辑软件Fotor,在全球超过5000个AI应用中,2023年9、10两月访问量排名23,月活高达千万;MiniMax旗下的海外AI聊天软件Talkie,自2023年8月发布以来,就长期位于美国Google Play娱乐应用下载榜前10。
可以预见的是,成功探路的案例越多,AI出海的队伍将在2024年愈发壮大。


0 条评论