-
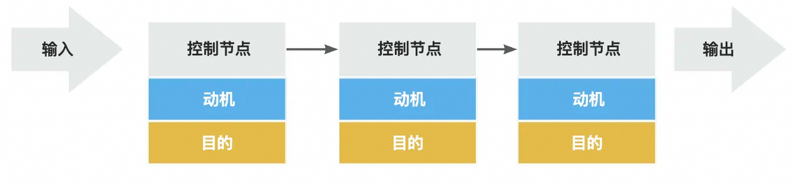
控制流描述目的或动机,对于控制流中的任意流程节点,其只关心该步骤的目的或者动机,与实现目的的过程没有关系,于此相反,控制节点反而是对一段过程的总结。
-
控制流与实现细节无关, 对于控制流中的任意流程节点,无论你如何实现它,流程节点的目的和意义都不会发生变化。例如对于用户详情查询控制流中的“查询用户基本信息”节点而言,无论你的实现细节是从缓存中查询还是从数据库中查询,其目的就是“输出用户信息交付给控制流下一流程节点”,不会随着存储源的变化而发生改变。
public class UserService {private UserInfoDAO userInfoDao;private UserDetailDAO userDetailDao;public User queryUserDetail(UserDO queryCondition) {String username = queryCondition.getUsername();String userId = queryCondition.getUserId();if (username == null) {throw new IllegalArgumentException("用户名不能为空");}if (userId == null) {throw new IllegalArgumentException("用户Id不能为空");}MapString, Object> param = new HashMap();param.put("username", username);param.put("userId", userId);UserDO userDO = userInfoDao.queryUserByCondition(param);if (userDO == null) {return null;}param = new HashMap();param.put("userId", userDO.getId());UserDetailDO userDetailDO = userDetailDao.queryUserDetailByCondition(param);if (userDetailDO == null) {throw new IllegalArgumentException("用户详情查询失败");}UserDetail userDetail = new UserDetail();userDetail.setAddress(userDetailDO.getAddress());userDetail.setNickName(userDetailDO.getNickName());userDetail.setPhone(userDetailDO.getPhone());return new User(userDO.getId(), userDO.getUsername(), userDetail)}}
上述用户信息查询代码是我在工作中遇到的一个真实的例子的简化改编,这种“流水账”似的代码在工程开发中比比皆是,造成代码流水账的原因往往是二次扩展时采取在代码的原有基础上进一步堆叠逻辑的方式,让方法的进一步熵增,逐渐混沌,导致一个方法几百上千行,失去维护价值。
描述目的与动机
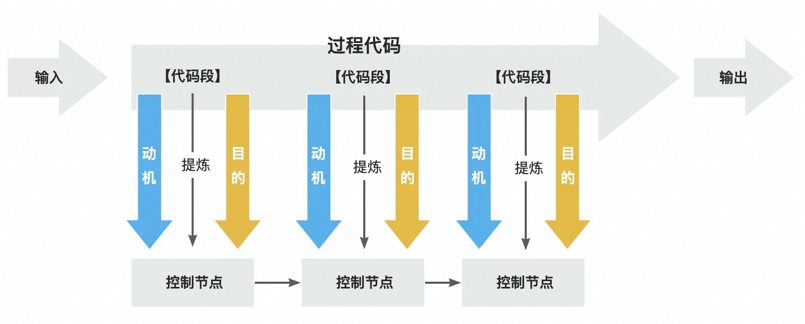
正向拆解
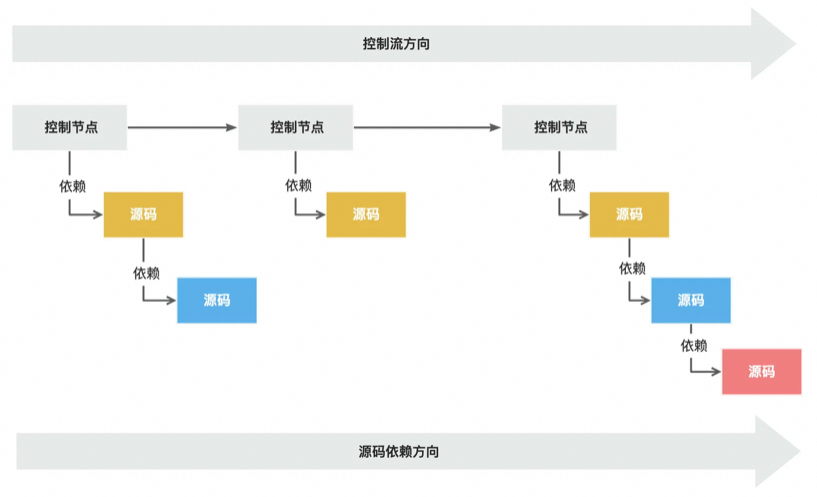
逆向还原
public class UserService {private UserInfoDAO userInfoDao;private UserDetailDAO userDetailDao;// ----------- 系统行为 -----------public User queryUserDetail(User queryCondition) {// 1. 参数校验validateQueryCondition(queryCondition);// 2. 查询用户基本信息UserDO userDO = queryUserInfo(queryCondition.getUsername(), queryCondition.getUserId());// 3. 查询用户详细信息UserDetailDO userDetailDO = queryUserDetail(userDO.getId());// 4. 校验查询结果validateQueryResult(userDetailDO);// 5. 返回查询结果return buildUserResult(userDO.getId(), userDO.getUsername(), userDetailDO);}// ------------ 私有方法:步骤实现细节 -----------private void validateQueryCondition(User queryCondition) {String username = queryCondition.getUsername();String userId = queryCondition.getUserId();if (username == null) {throw new IllegalArgumentException("用户名不能为空");}if (userId == null) {throw new IllegalArgumentException("用户Id不能为空");}}private UserDO queryUserInfo(String name, String userId) {MapString, Object> param = new HashMap();param.put("username", name);param.put("userId", userId);UserDO userDO = userInfoDao.queryUserByCondition(param);if (userDO == null) {throw new IllegalArgumentException("用户详情查询失败");}return userDO;}private UserDetailDO queryUserDetail(String userId) {MapString, Object> param = new HashMap();param.put("userId", userId);return userDetailDao.queryUserDetailByCondition(param);}private void validateQueryResult(UserDetailDO userDetail) {if (userDetail == null) {throw new IllegalArgumentException("用户详情查询失败");}}private User buildUserResult(String id, String username, UserDetailDO userDetailDO) {UserDetail userDetail = new UserDetail();userDetail.setAddress(userDetailDO.getAddress());userDetail.setNickName(userDetailDO.getNickName());userDetail.setPhone(userDetailDO.getPhone());return new User(userDetail);}}
上述代码看似只是抽了几个方法抽象,实则不然,深挖这背后的动机,这其实隐含着解构过程的思想。为什么声明式编程比命令式编程更加具有优势,究其本质就是其面向目的而不是过程的宗旨,这不仅仅是避免了复杂的过程带来的副作用,而且增加了代码整体的可读性。而此处我们将过程细节进行分类封装于以目的命名的方法中,而在主流程中只留下各种以目的作为命名的方法的编排,使得系统行为的控制流程得以凸显,能够让代码读者迅速抓取整段代码各个部分的目的和动机。这其实和声明式编程的内核不谋而合。
藏在暗处的维护隐患
细节无关原则

public class UserService {private UserInfoQueryRepository userInfoQueryRepository;private UserDetailQueryRepository userDetailQueryRepository;private UserQueryValidator userQueryValidator;// ----------- 系统行为 -----------public User queryUserDetail(User queryCondition) {// 1. 参数校验validateQueryCondition(queryCondition);// 2. 查询用户基本信息User user = queryUserInfo(queryCondition.getUsername(), queryCondition.getPassword());// 3. 查询用户详细信息UserDetail userDetail = queryUserDetail(user.getId());// 4. 校验查询结果validateQueryResult(userDetail);// 5. 返回查询结果return new User(userDetail);}// ------------ 私有方法:步骤实现细节 -----------private void validateQueryCondition(User queryCondition) {userQueryValidator.validateQueryCondition(queryCondition);}private User queryUserInfo(String userId, String userName) {User user = userInfoQueryRepository.findUser(userId, userName);if (Objects.isNull(user)) {throw new IllegalArgumentException("用户详情查询失败");}return user;}private UserDetail queryUserDetail(String userId) {return userDetailQueryRepository.findByUserId(userId);}private void validateQueryResult(UserDetail userDetail) {userQueryValidator.validateUserDetail(userDetail);}}
这段代码里面我利用多态做了两件事:
-
将校验逻辑抽象为Validator接口,其背后的动机就是将系统中出现的所有校验逻辑内聚至一处单独管理,以此封装所有的校验细节并将细节脱离于控制流,提升系统核心流程的整洁度。但其实是否需要这样做见仁见智,很多时候过度设计并不见得是一件好事。在校验逻辑不会过于复杂且修改频率较低的情况下,保留控制流对于校验逻辑细节的强依赖其实无伤大雅。
-
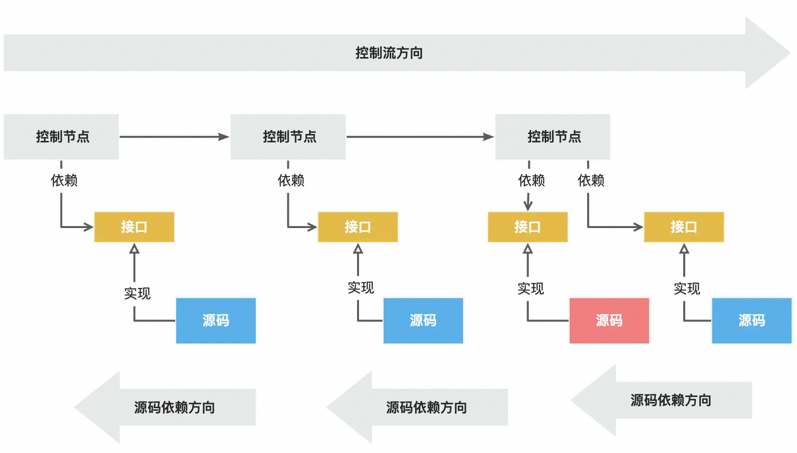
将DAO封装为Repository仓储层,其背后的动机相较于第一点其实更加复杂一点,除了IO逻辑内聚之外,更重要的是对设备无关原则的遵循。
为什么UNIX操作系统会将IO设备设计成插件形式呢,因为自20世纪50年代末期以来,我们学到了一个重要经验:程序应该与设备无关。这个经验从何而来呢?因为一度所有程序都是设备相关的,但是后来我们逐渐发现其实真正需要的事情是在不同的设备上实现同样的功能。 ——《架构整洁之道》
private UserDO queryUserInfo(String name, String userId) {MapString, Object> param = new HashMap();param.put("username", name);param.put("userId", userId);UserDO userDO = userInfoDao.queryUserByCondition(param);if (userDO == null) {throw new IllegalArgumentException("用户详情查询失败");}return userDO;}
以上代码将查询参数put到map中的操作就是在将领域信息翻译构建为关系型数据库的查询操作。

public interface UserInfoQueryRepository {/*** 根据userId、userName查询用户信息* @param userId user id* @param userName user name* @return user info*/User findUser(String userId, String userName);}public class UserInfoQueryMysqlRepository implements UserInfoQueryRepository {private UserInfoDao userInfoDao;private UserModelConverter modelConverter;public User findUser(String userId, String userName) {MapString, Object> param = new HashMap();param.put("username", userName);param.put("userId", userId);UserDO userDO = userInfoDao.queryUserByCondition(param);if (userDO == null) {throw new IllegalArgumentException("用户详情查询失败");}return modelConverter.convert(userDO);}}
以上代码将系统的用户信息查询诉求抽象为了repository的方法,规定的入参和出参,以此在仓储层留落领域信息,如果需要通过关系型数据库实现用户信息查询功能,就应该实现该仓储层接口,于此封装存储过程的源码细节,而不是直接将源码细节耦合在系统核心领域中。这样的话后期如果我们需要扩展用户信息的IO方式,比如从缓存中获取,可以非常轻松的进行扩展并替换核心领域中的存储来源。
public class UserInfoQueryRepositoryImpl implements UserInfoQueryRepository {/*** mysql store*/private UserInfoQueryMysqlRepository userInfoQueryMysqlRepository;/*** local cache store*/private UserInfoQueryLocalCacheRepository userInfoQueryLocalCacheRepository;/*** redis store*/private UserInfoQueryRedisRepository userInfoQueryRedisRepository;public User findUser(String userId, String userName) {// 1. 在各存储源中查询用户信息User user = findUserFromMultilevelCache(Arrays.asList(userInfoQueryLocalCacheRepository,userInfoQueryRedisRepository,userInfoQueryMysqlRepository), userId, userName);// 2. 校验查询结果validateResult(user);// 3. 返回结果return user;}private User findUserFromMultilevelCache(Listrepositories, String userId, String userName) { for (UserInfoQueryRepository repository : repositories) {User user = repository.findUser(userId, userName);if (Objects.nonNull(user)) {return user;}}return null;}private void validateResult(User user) {if (Objects.isNull(user)) {throw new IllegalArgumentException("结果查询失败");}}}
控制流对于过程的解构其实就是一个递归的过程,逐步将长流程解构为一个个独立存在,保证可扩展性的流程子节点。
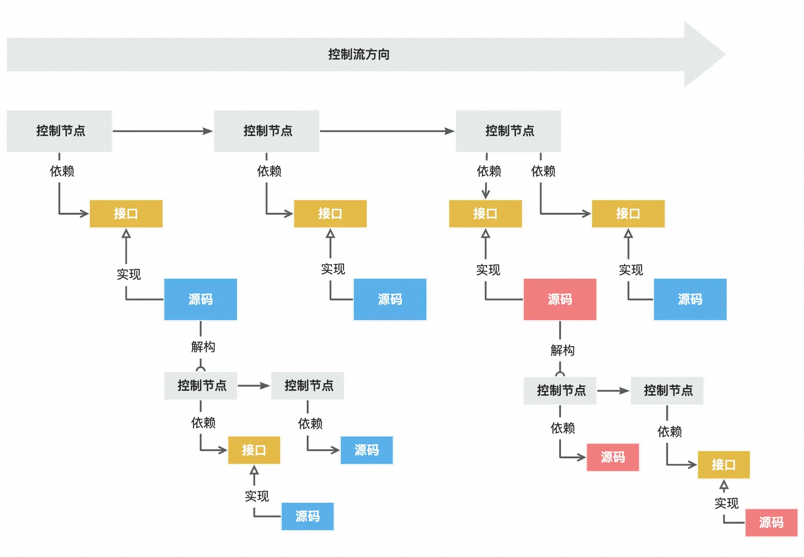
public class UserService {private ProcessorFactory processorFactory;private ProcessorChainBuilder processorChainBuilder;private ChainInvoker chainInvoker;// ----------- 系统行为 -----------public User queryUserDetail(User queryCondition) {ProcessorChainprocessorChain = processorChainBuilder .process(processorFactory.get("queryConditionValidateProcessor")).process(processorFactory.get("queryUserInfoProcessor")).process(processorFactory.get("queryUserDetailProcessor")).process(processorFactory.get("queryResultValidateProcessor")).build();return chainInvoker.invoke(queryCondition, processorChain);}}
当然,还有更多更好的编排方式,比如基于xml配置化或者页面可视化配置。
-
过程堆叠模式 -
基于目的和动机描述的控制流模式 -
基于目的和动机描述并且细节无关的控制流模式 -
基于流程编排的控制流模式
0 条评论