导读
2.1 生命周期
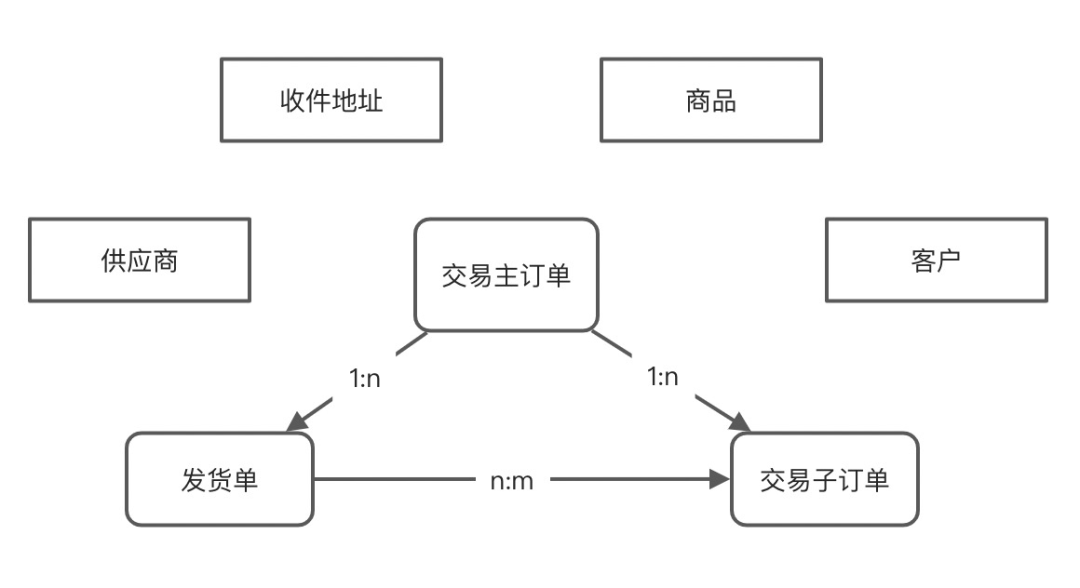
1.用户提交订单
2.商品的库存占用
3.用户在规定时间内进行支付
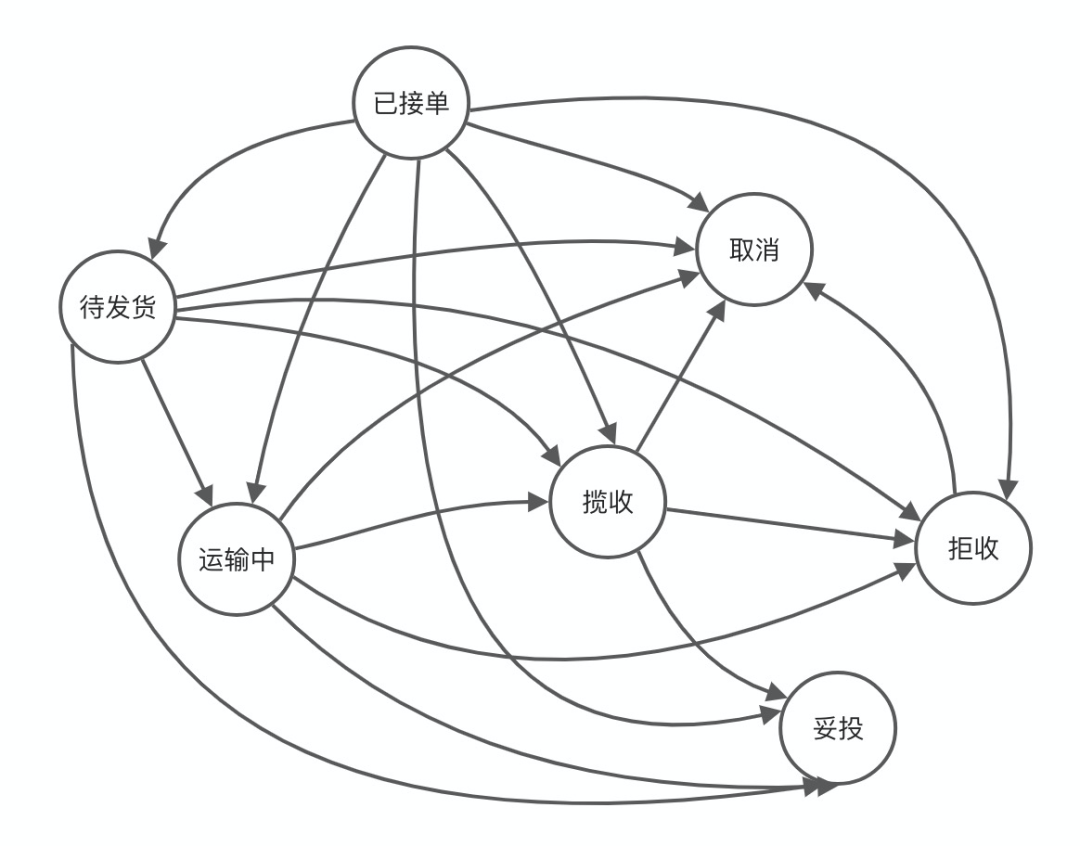
4.订单阶段性状态推进:待支付、支付完成、待发货、运输中、配送中、妥投等等
1. 生命周期中发生查询请求
1.订单有效期到期取消订单
2.用户取消订单

-
主子单一致性:不仅上面提到的妥投一致性规则,还可以有出仓库一致性规则,即交易子单的出仓都是单独的,当所有发货单都已经出仓库,交易主单才推进状态为出仓,那么这条规则的逻辑维护将会转移到聚合根交易主订单实体中,每次聚合发生状态变化就会触发一次检查;
-
发货单与子单一致性:上面说过,包裹是存放子单的部分数量的,每个包裹里面存放有哪些子单、数量是多少,而所有包裹的子单数量合并统计后必须要和源交易子订单逻辑一致,现在这个一致性可以让主订单保证而不再散落。特别对于发现不一致的情况下,只需在一个地方做报警监控即可。
-
节点流水记录:因为单据作业流水记录的节点是跟单据状态对应的,所以流水记录逻辑可以封装到聚合根中,变一次状态(例如从提交订单(Accepted)到支付完成(Paid)状态),属于一次状态变化,会记一条流水,2.3节会专门介绍封装在聚合根内状态同步模型。注意这里不是让主订单去操作数据库,它只负责生成流水而已,把流水记录到数据库应该由领域服务负责;
-
订单状态推进:各种事件(支付、发货、妥投)同步及异步回传的处理代码,都将会封装到交易主订单中,让主订单变更子订单和发货单状态,逻辑只有一份,可维护性强;另外一个状态的变更用状态机是前期可以考虑的方案;
-
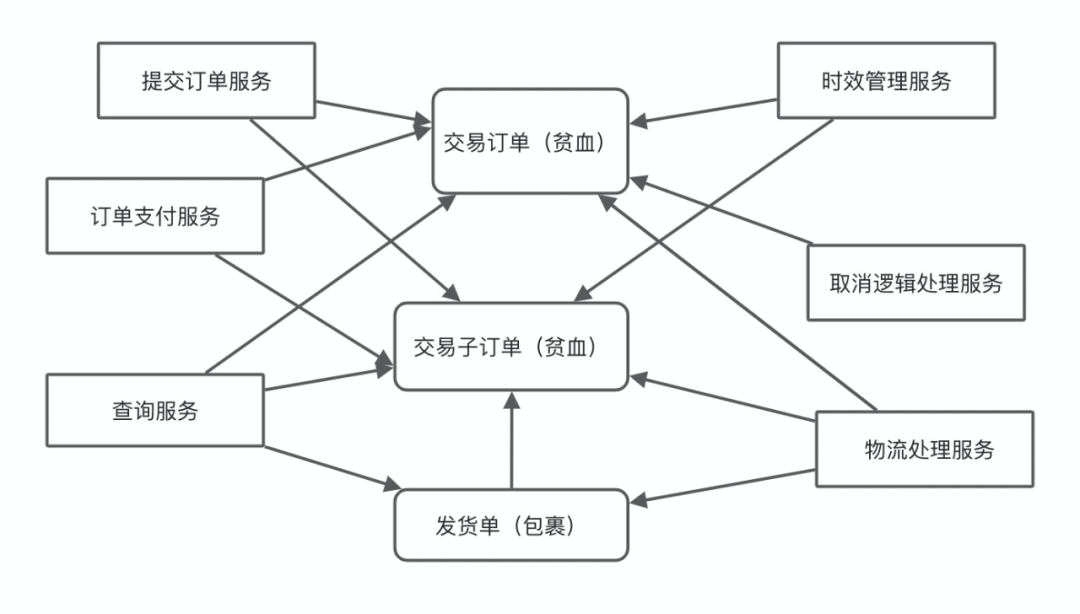
没有数据库概念:取消逻辑服务、查询服务、支付逻辑处理服务等服务,不在需要写一遍SELECT交易主订单,交易子订单,UPDATA交易主订单,交易子订单等逻辑,甚至没有INSERT这种逻辑,而它们都只需两个动作:拿出交易主订单聚合,放交易主订单聚合回仓库;
-
副作用的保护:以前的模型中,各个服务都会对单据产生副作用,现在只有主单会对包裹、子单产生副作用。而这种副作用还可以被监控起来,在下一节我将会好好介绍我是如何深入演进命令实体模型保护这些副作用的。

-
查询性能:很明显,如果你只是想修改交易主订单的一个字段,那么仓储会把交易主订单下面的所有交易子订单都加载出来,这点必然会加大对性能的影响;另一方面,如果你把聚合实体都加载出来,那么不需要修改的实体你也必须要写回数据库中,但这点是可以通过一些小设计优化的,例如,聚合根修改了哪个实体,你就为该实体加不同的版本,这样仓储就只会根据版本去按需更新对象;另外,有些状态变化可能对一致性没影响,但依旧会触发检查一致性,这类性能影响不大。
-
无谓的更新:例如你只想更新单据的一个字段,而你的SQL是这样写的,UPDATE TABLE A SET A.name = “Marry” WHERE XX,但是用了聚合根之后,就需要全量的更新整个DO的多个字段了,如果你一旦不小心设了其他字段,自然也会被更新下去,也减少了犯错的成本,但这一般不会成为很大的问题,可以加入断言、或者显性的打印出每一次修改字段的日志,这样开发者很快就能得到他犯错了的反馈。
-
属性访问:访问单据的困难是显然而见的,例如,我某个服务需要访问交易子订单的数据,也只能通过交易主订单去交互,这样会不会让人难以接受呢?其实这种困难很好克服,只要把查询分离出来,创建一套聚合的访问视图(访问模型),让交易主订单的充血方法去返回这种访问视图,让服务去操作这个视图即可,而且这个视图可以在各种地方使用,也不必担心会因使用者产生副作用,性价比是非常高的。
2.2 隐式概念
public class TradeSubOrder {private Long id;private Date gmtCreate;private Date gmtModified;private boolean test;private StatusEnum status;// more fieldprivate String size;private boolean repositoryTrace = false;private String extendAttribute;//还有更多// getter setter toString}
-
交易主订单:“收货地址”,“收货人姓名”,“联系电话”,“邮箱”;共同变化的原因:
-
交易主订单:“客户id”,“客户姓名”,“会员等级”,“账号”;;共同变化的原因:
-
交易主订单:“支付方式”,“支付单号”,“支付状态”,“支付时间”,“实付金额”,共同变化原因
-
发货单:“送达时间”、“服务时效”、“配送员”、“物流订阅商”;共同变化的原因:
-
交易子订单:“规格”、“数量”、“价格”、“图片”、“货主”、“优惠价”;共同变化的原因:
-
其他归类……
-
用户修改地址:对于电子商务类服务,无论是各种快递、淘宝等都是支持在未妥投之前让用户去修改地址的,做的好的产品,甚至可以支持多次地址的修改,那么用户在什么时间修改了地址呢?修改前是什么?修改后是什么?这些信息都必须在某个地方很明显的表达出来。
-
加一个服务类:当业务需要的时候,我们自然可以专门开发一个服务类插入系统去支持,但这种需求又有多少呢?未来有没有?能不能有一套设计方案可以保护核心流程,保留可选项,又不失优雅的去支持这类业务呢?
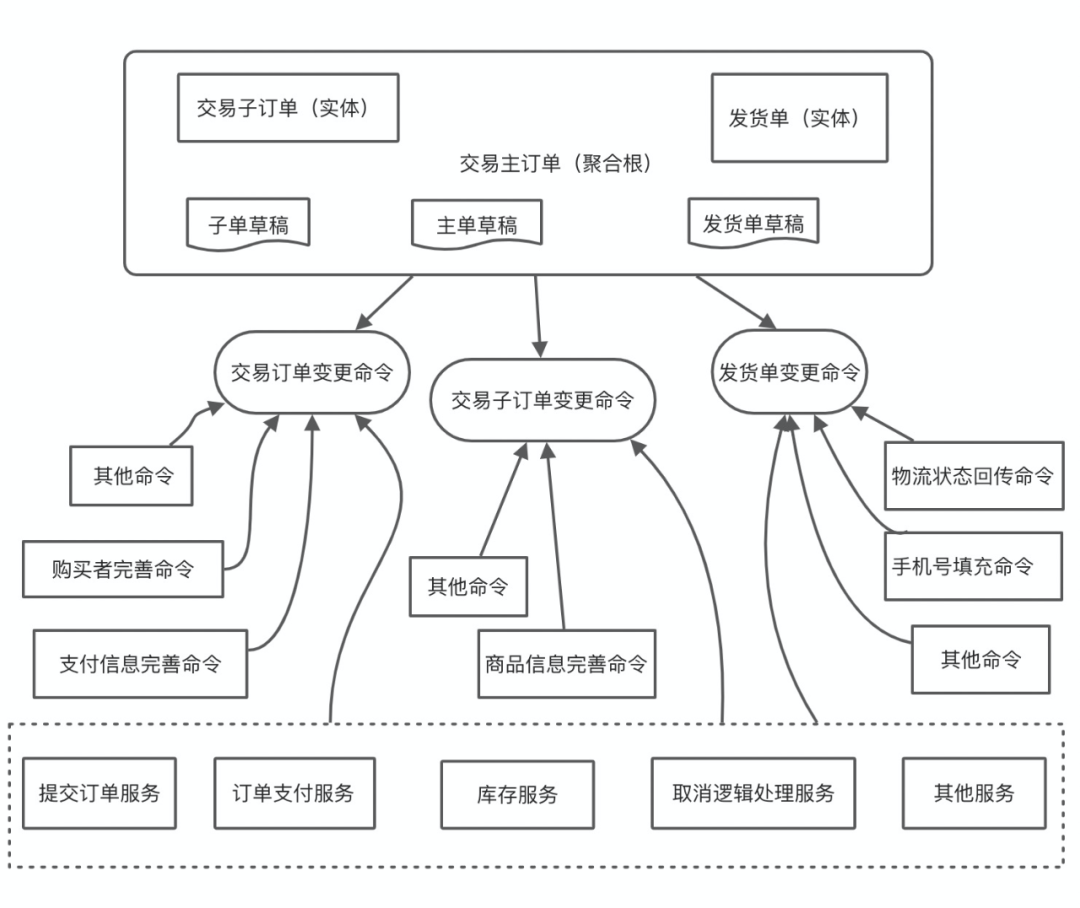
2.2.2 概念突破:命令实体

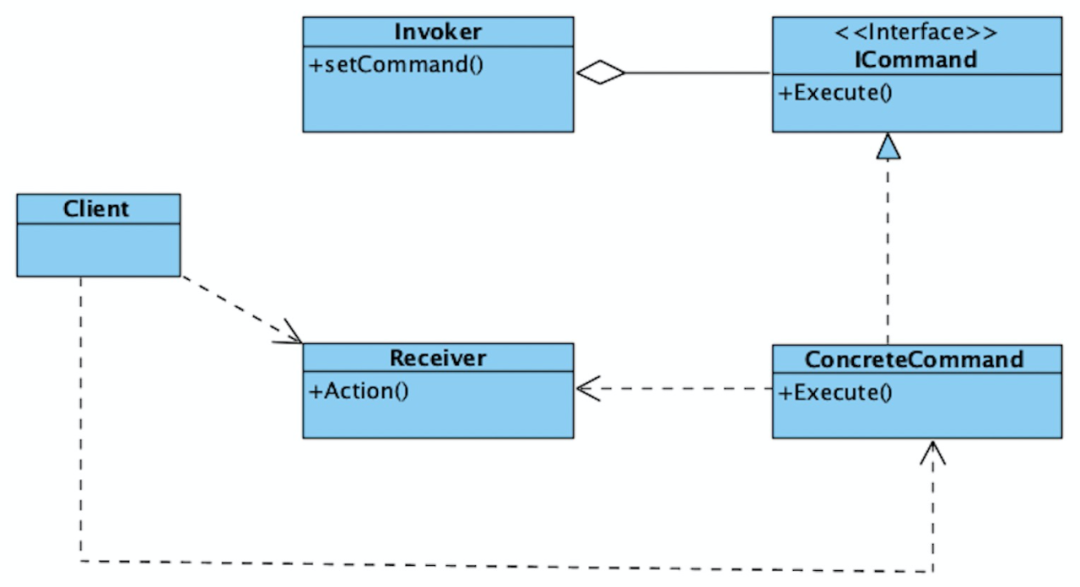
public class SubmitOrderUsercase{public void sumit(Request request) {TradeMainOrder mainOrder = getMainOrder();//获取命令的具体实现IPhoneNumberCompleteCommand command = getCommand(request,IPhoneNumberCompleteCommand.class);//聚合根执行手机号完善命令mainOrder.execute(command);// ......//获取命令的具体实现IDiscountCalculateCommand command = getCommand(request,IDiscountCalculateCommand.class);//聚合根执行折扣计算命令mainOrder.execute(command);// ......}public IPhoneNumberCompleteCommand getCommand(Request request,Class clazz){// 业务配置好的,什么场景用什么命令.......}}
public interface TradeSubOrderChangeCommand {String getSubOrderId();void execute(TradeSubOrderDraft subOrder);}
public class TradeMainOrder{public void onCommand(TradeSubOrderChangeCommand command) {if (!tradeSubOrderDict.isEmpty()) {TradeSubOrder subOrder = findSubOrder(command.getSubOrderId());// 变更前的快照代码command.execute(subOrder);// 变更后的对比逻辑代码,记录字段变化个数、时间record();// ......makeStateConsistent();} else {log.error("子单变更命令执行失败,子单列表为空,{}", EagleEye.getTraceId());}}public void onCommand(TradeOrderChangeCommand command) {// 变更前的快照代码command.execute(this);// 变更后的对比逻辑代码,记录字段变化个数、时间record();// ......makeStateConsistent();}}
-
只要给每个命令一个id,那么命令组合就可以在外界进行配置化;
-
因为命令组合可以配置化,所以执行哪些命令是运行态决定的,灵活性得以体现;
-
命令组合的实现都是函数式的,所以组合之后的命令不会有“组合爆炸”的问题,过程也是透明、安全的;
有了组合命令,那么就可以轻松做到把命令按照业务的需求,量身配置成组合上线;可以被管理、被配置、独立性的代码,是程序员追求的最高艺术品。
2.3 深层模型


-
有序性:状态机的节点是无序的,或者说只能相对有序,但我们的同步模型是有序的;这个和问题空间的工序是一致的,本来问题空间的每一步就都是有序的。
-
拓扑结构:状态机的节点是可以存在环状的,但我们的同步模型是拓扑排序的,正好我们的业务节点也不会有环,拓扑是这个领域的特有性质,这点很重要,因为我们是领域驱动设计。
-
运作机制:状态机的运作是以事件和当前状态为核心找到下一个流转状态,但同步模型不同,同步模型以流程实例为核心,每一个事件到来就把该流程的节点标记为已同步;如上图所谓,1、2、4、5对应事件都已经到达,所以他们为绿色;而每一次事件处理完成后,我们会对比最大序号的节点和单据当前状态谁的序号最大,从而把序号最大的更新为单据状态。
-
计算机无关性:现在模型不再关注事件是否乱序,延迟,只要事件到达,我们就把事件对应的节点点绿,标记为已同步,并触发对应节点的业务逻辑:例如计费消息的发送、流水的记录。
对比状态机,新的状态同步模型,在开发效率上、代码维护上、都提升了一个层次,如果说状态机是线性复杂度,那么状态同步模型就是常数级别的复杂度。这个例子充分证明了领域驱动设计的核心本质:领域的重要性、知识的重要性。
2.4 边界模型

-
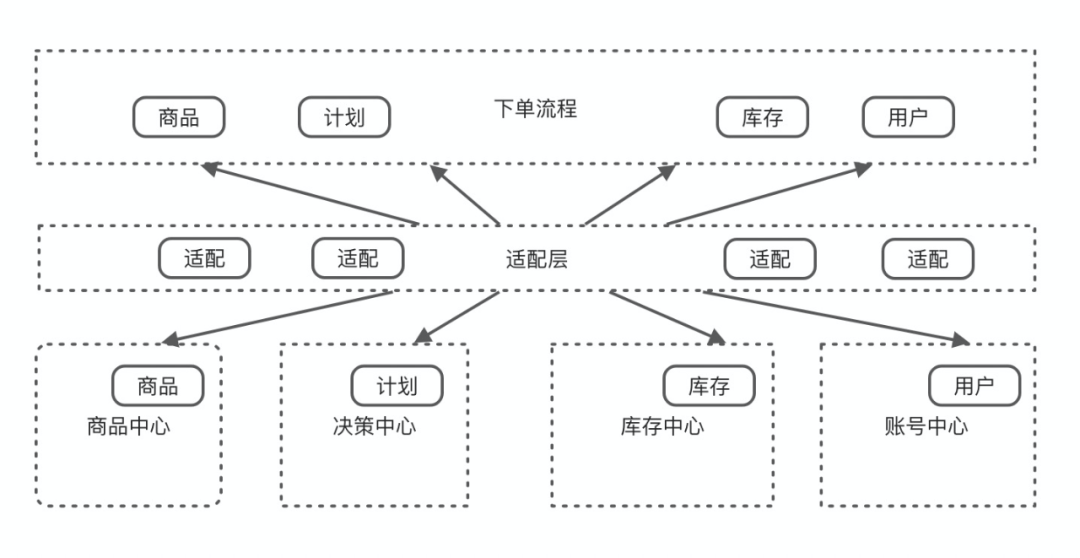
保护核心层概念:
-
例子: 例如,你在公司的角色是老板,但在家里的角色是父亲,如果你把老板实体放在家庭中为孩子煮菜,这个家庭就会依赖他们不需要的逻辑,这对于整洁架构是违反原则的,会引入变更,破坏稳定性; -
例子: 在交易系统这种复杂的系统中,例如一个在供应商系统中代表它自己编码的merchantCode可能来到交易系统这边会变成supplyMerchantCode,同一个值,用角色字段区分他们这自然是很重要的;
-
关注点分离:
-
说明:外部接口的非逻辑依赖的变更,不必担心变更的数据结构在核心逻辑中的作用,你只需保证返回的字段含义一致就可以了;
-
适配逻辑的代码:
-
说明:有很多代码你只是用来做外部实体的处理的,变成内部可识别的实体,例如决策中心传给你的是2021-07-12 ~ 2021-07-13,但你内部用的是一个stat的Date变量和一个end的Date变量;那就需要适配了,这些代码如果编写在核心逻辑中,那你在维护核心逻辑的时候也不得不多思考一件事,不仅代码臃肿,还消耗你的精力。 -
说明:有一个点很重要,为什么要做这种设计,因为设计就是需要把代码放在它该呆的地方,这种转换的代码,总要有一个适配器处理;
-
可随时挖掘隐式概念:
-
说明:例如用户的会员等级,这个会员等级字段属性,就是一个隐藏的概念,它存在于用户账号中,所以你难以发觉。但日后不断的需求变更中,你或许会发现它可能是一个封装性很好的实体。下一节我们将具体介绍如何挖掘除会员等级这个实体。
@Datapublic class UserAccount {// 其他字段 ....../*** 会员等级*/private int userLevel;// 其他字段 ......}
public class XxxxxxxService {public Double getDiscount(UserAccount account) {switch(account.getUserLeval){case 1:return 0.99;case 2:return 0.98;case 3:return 0.97;case 5:return 0.95default:return 1.00;}}}
@Datapublic class UserAccount {/*** 客户等级**/int userLevel;public Double getDiscount() {switch(userLevel){case 1:return 0.99;case 2:return 0.98;case 3:return 0.97;case 5:return 0.95default:return 1.00;}}}
@Datapublic class UserAccount {/*** 客户等级*/private UserLevel userLevel;}public class UserLevel {int userLevel;public Double getDiscount() {switch(userLevel){case 1:return 0.99;case 2:return 0.98;case 3:return 0.97;case 5:return 0.95default:return 1.00;}}}
2.5 领域服务
-
应用层服务用作和输入输出相关的逻辑,并且负责调用领域层服务
-
领域层服务用作和领域模型交互,负责组织和协调的领域模型工作的逻辑
-
提交订单领域服务:执行读取命令配置、执行命令、库存占用、价格计算、定时失效等逻辑代码;
-
支付领域服务:读取命令配置、执行命令,负责支付校验、调用支付服务、订单各种命令执行等逻辑代码;
-
取消领域服务:读取命令配置、执行命令,负责释放库存、取消订单、取消定时任务等逻辑代码;
-
…….
参考书籍
0 条评论