导读

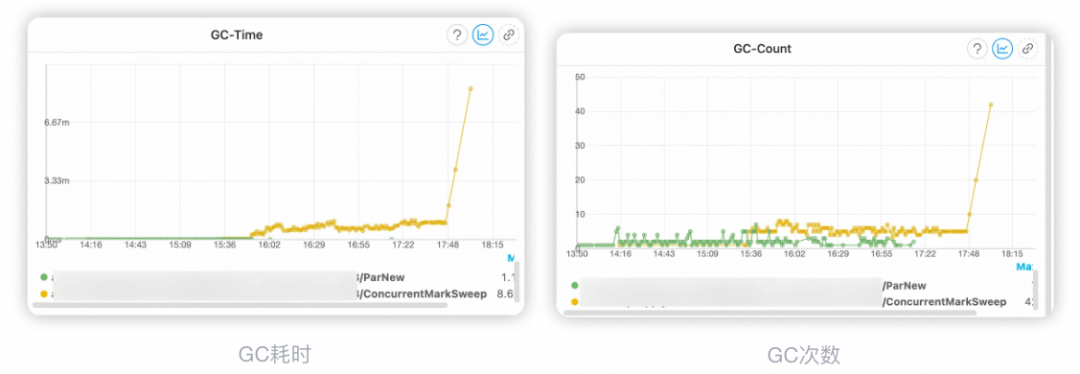
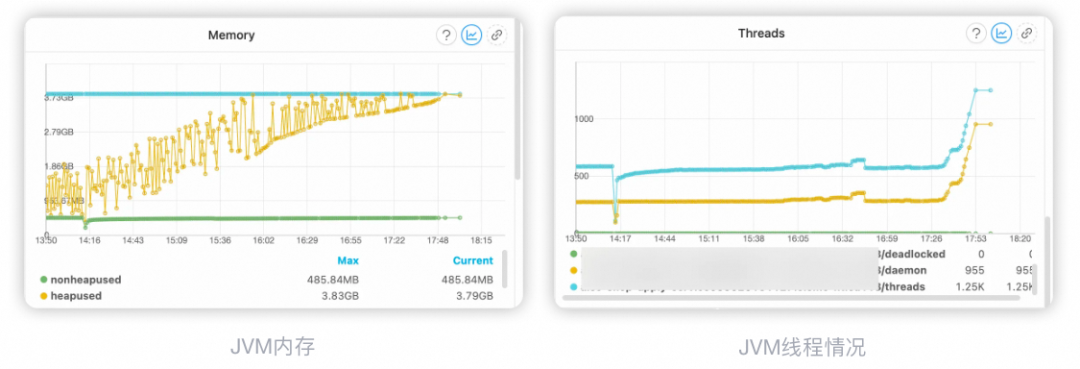
14:16 机器发布新代码 15:35 机器开始出现fullGC 15:50 机器fullGC耗时上升 17:48 对JVM进行dump操作,然后进行机器置换
1.有大量阻塞线程
1.1 排查过程
分析线程Dump文件
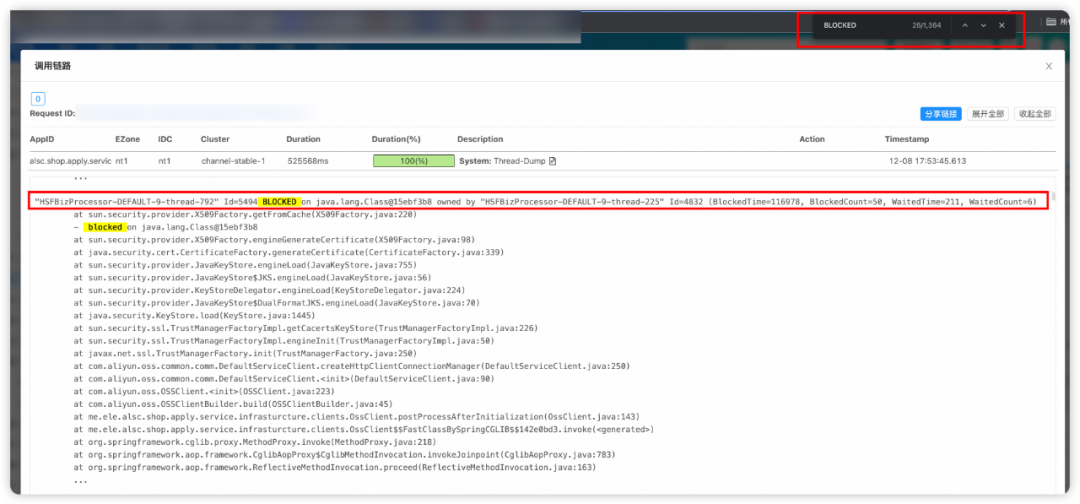
1.2 分析原因
public class OssClient implements BeanPostProcessor {private OSS ossClient = null;/*** 初始化OSS客户端**/public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {// 省略代码……// 以下是阻塞代码行ossClient = new OSSClientBuilder().build(ossProperty.getString("endpoint"),ossProperty.getString("accessKeyId"),ossProperty.getString("accessKeySecret"),configuration);// 省略代码……return bean;}}
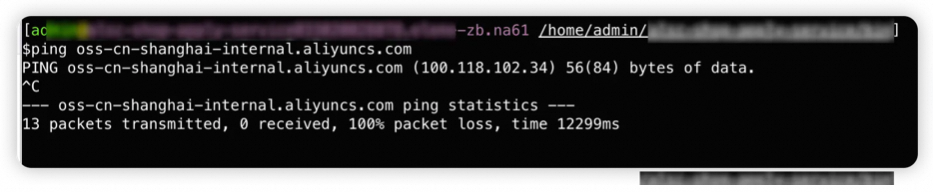
1.3 第一次问题解决
二、第二次报错系统监控现象
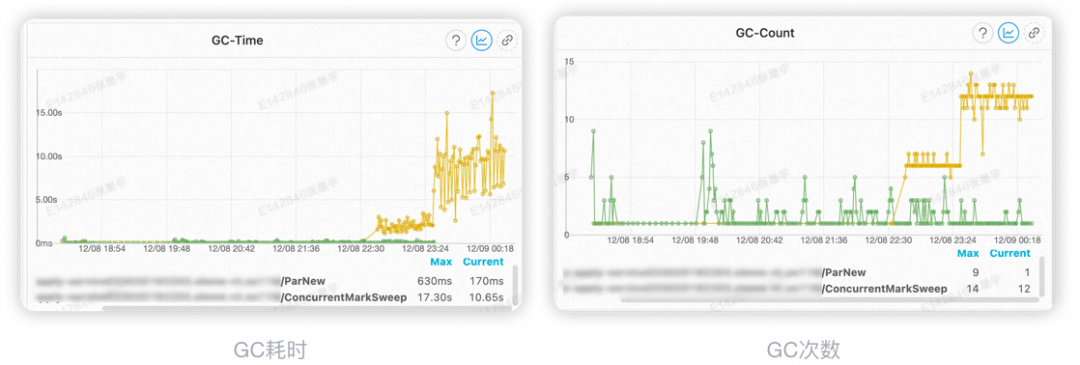

19:48 机器发布新代码 22:30 机器开始出现fullGC 23:30 机器fullGC耗时上升 00:30 对JVM进行dump操作,然后进行机器置换
2.1 排查过程
分析线程Dump文件
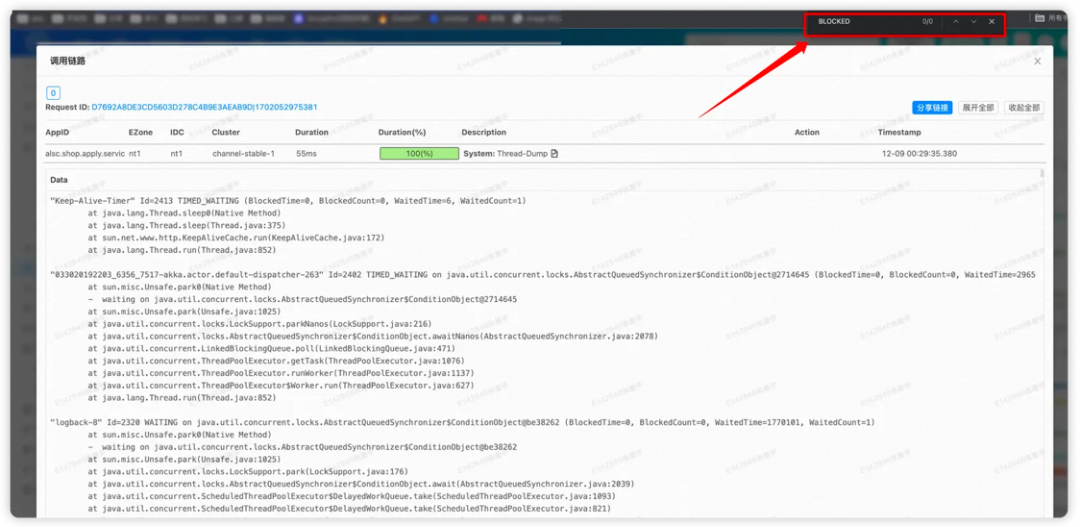
1.阻塞线程确实是由于OSS跨单元拒绝访问导致的
分析GC Dump文件
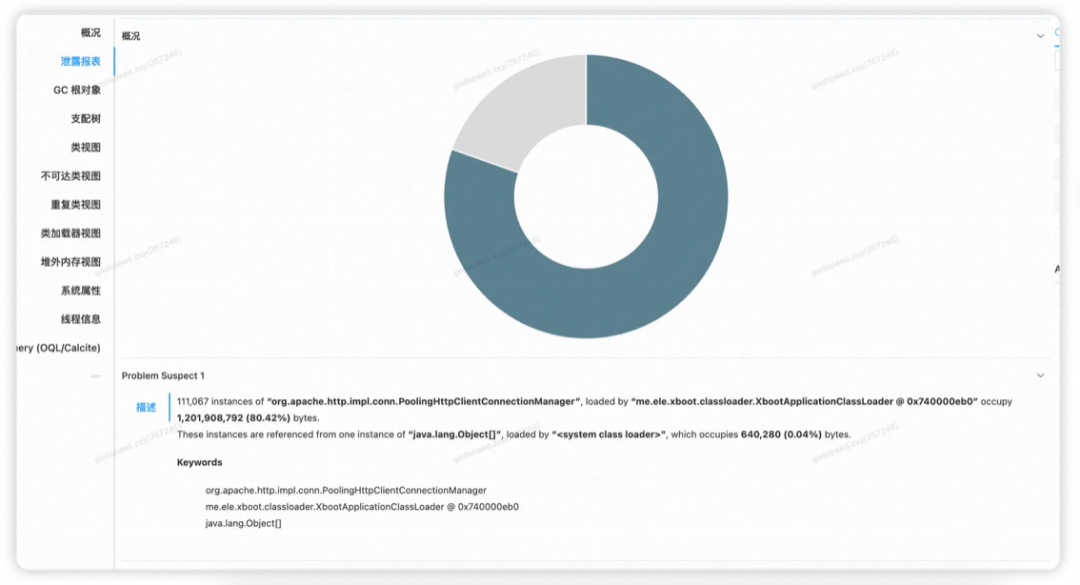
这里显示有11万个org.apache.http.impl.conn.PoolingHttpClientConnectionManager实例,占用了80.42%的堆内存,但是这个类并不是我直接引入的,那么一定是有间接依赖,生成了大量该类对象。
另外,通过类名,能判断这个对象是和网络请求有关系,而我这个应用上需要网络请求的地方有几处: 1.访问DB 2.访问Redis 3.访问OSS 4.进行HSF调用

2.2 分析原因
public class OssClient implements BeanPostProcessor {private OSS ossClient = null;/*** 初始化OSS客户端**/public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {// 省略代码……// 一下是阻塞代码行ossClient = new OSSClientBuilder().build(ossProperty.getString("endpoint"),ossProperty.getString("accessKeyId"),ossProperty.getString("accessKeySecret"),configuration);// 省略代码……return bean;}}
排查原因过程中,有一篇文章给了我答案,下面是这篇文章给的OOM原因的解释:
每次new OSSClient的时候,都会往List中放入HttpClientConnectionManager,但是没有主动调用OSSClient的shutdown的方法,所以List只会增大不会变小。反观我们的代码,每次接口调用都会创建一个OSSClient对象,但却在使用完之后,没有调用OSSClient的shutdown方法,导致未调用IdleConnectionReaper的removeConnectionManager方法,使得IdleConnectionReaper中静态列表存储的PoolingHttpClientConnectionManager实例数据一直会增长,一直都不会被回收,最终带来的结果就是OOM。
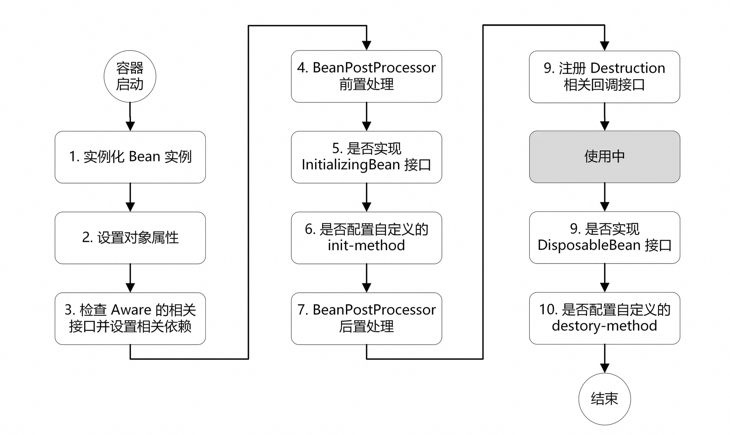
2.3 最终问题解决
public class OssClient implements InitializingBean {private OSS ossClient = null;/*** 初始化OSS客户端**/public void afterPropertiesSet() throws Exception {// 省略代码……// 以下是阻塞代码行ossClient = new OSSClientBuilder().build(ossProperty.getString("endpoint"),ossProperty.getString("accessKeyId"),ossProperty.getString("accessKeySecret"),configuration);// 省略代码……}}

0 条评论