(一) 本文目的
(二) 基本原则
-
正文部分不会放具体概念或者知识性质的内容。JVM内存模型会放在扩展阅读部分; -
正文部分会放排查思路和排查建议,涉及到变更或者命令行实操的部分会放在扩展阅读部分; -
正文部分使用的排查工具会满足下列两项规则之一:阿里云Paas服务产品或者开箱即用。需要安装的tool或者agent相关材料会放在扩展阅读部分; -
正文排查判断流程会按照step一步步的向下走。争取做到思路连贯; -
步骤中需要逻辑判断或者深入分析的部分会使用GPT来帮助解答分析,实在没法简化的部分会放在扩展阅读部分;
(三) 限定范围
Step1 : 收到问题
Step 1.1 基本信息收集
1.目前的现象是什么:是内存居高不下,内存缓慢增加还是进程突然Dump掉?
Step 1.2 依赖上面信息作出基本判断:
-
业务增加导致的内存增加,往阿里云弹性能力方向引导;
-
业务未变,近期未有变更,内存增长是周期性,偶发性。基于现象有基本判断,后续可以围绕基本判断推进排查;
-
周期性增加:往定时任务方向排查;
-
偶发性增长:首先考虑的是在不影响业务情况下的现场复现,后续往这个方向引导;
-
缓慢持续性增长:都有可能,跳转Step2判断来源;
-
快速止损:业务有损情况下首先需要推荐快速止损方案;
-
切流下线,通过目前使用的服务发现组件(Nacos,Consul or Eureka) 将问题机器快速下线。如果判断是变更造成的需要灰度回滚;
-
机器重启或者手动触发FullGC(跳转扩展阅读->Jcmd)。快速回收内存,减少服务影响;
-
在变更前保留现场;
Step 1.3 保留现场:
1. heapdump文件
#jmap命令保存整个Java堆(在你dump的时间不是事故发生点的时候尤其推荐)jmap -dump:format=b,file=heap.bin
#jmap命令只保存Java堆中的存活对象, 包含live选项,会在堆转储前执行一次Full GCjmap -dump:live,format=b,file=heap.bin#jcmd命令保存整个Java堆,Jdk1.7后有效jcmdGC.heap_dump filename=heap.bin #在出现OutOfMemoryError的时候JVM自动生成(推荐)节点剩余内存不足heapdump会生成失败-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heap.bin#编程的方式生成使用HotSpotDiagnosticMXBean.dumpHeap()方法#在出现Full GC前后JVM自动生成,本地快速调试可用-XX:+HeapDumpBeforeFullGC或 -XX:+HeapDumpAfterFullGC
2. 当前JVM的启动参数
ps -ef|grep java示例:结果类似下文
$ps -ef|grep javaadmin 101775 1 4 2023 ? 13:32:54 /opt/taobao/java/bin/java -server -Xms9g -Xmx9g -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:MaxDirectMemorySize=1g -XX:SurvivorRatio=10 -XX:SoftRefLRUPolicyMSPerMB=1000 -XX:+UnlockExperimentalVMOptions -Xss256k -XX:+UseG1GC -XX:MaxGCPauseMillis=150 -XX:G1HeapWastePercent=5 -XX:G1NewSizePercent=10 -XX:G1MaxNewSizePercent=30 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1MixedGCCountTarget=64 -XX:MaxHeapFreeRatio=15 -XX:MinHeapFreeRatio=5 -Dsun.rmi.dgc.server.gcInterval=2592000000 -Dsun.rmi.dgc.client.gcInterval=2592000000 -XX:ParallelGCThreads=4 -Xloggc:/home/admin/logs/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/admin/logs/java.hprof -Djava.awt.headless=true -Dsun.net.client.defaultConnectTimeout=3000 -Dsun.net.client.defaultReadTimeout=3000 -Dfile.encoding=UTF-8 -Dproject.name=primushubcenter -Dschedulerx.console.domain=vpc-schedulerx2.cn-hangzhou.aliyun-inc.com -Drocketmq.namesrv.domain=jmenv.cn-hangzhou.aliyun-inc.com -Drocketmq.namesrv.domain.subgroup=nsaddr -Daddress.server.domain=jmenv.cn-hangzhou.aliyun-inc.com -Dhsf.server.ip=10.1.0.149 -javaagent:/home/admin/primushubcenter/ArmsAgent/arms-bootstrap-1.7.0-SNAPSHOT.jar org.springframework.boot.loader.JarLauncher --server.port=7001 --management.port=7002 --management.info.build.mode=full --spring.profiles.active=production --logging.path=/home/admin/primushubcenter/logs --logging.file=/home/admin/primushubcenter/logs/application.log --startup.at=1702966471667
这段命令包含了很多JVM参数,下面一条一条来解析:-server:JVM运行在server模式,这种模式下JIT编译器会进行更多的优化,但是启动和编译速度会慢一些。因为这是一个持久运行的服务,所以这个选项是正确的。-Xms9g -Xmx9g:初始化堆内存和最大堆内存都设为9G,这种设置可以避免JVM因为频繁的扩张和收缩堆空间导致的性能开销。考虑到机器内存是24G,这个设定是合理的。-XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m:设置元空间的初始大小和最大大小均为512M。元空间用于存储类的元数据,对于大型应用,这个值可能需要增大。-XX:MaxDirectMemorySize=1g:设定直接内存的最大值为1G。直接内存并不是Java Heap,而是在Java Heap之外的,且不受JVM垃圾收集影响的内存区域,主要用于NIO的缓冲。-XX:SurvivorRatio=10:设置新生代中Eden区与Survivor区的大小比值。这个值决定了新生代中多少空间被用作Eden区和Survivor区。-XX:SoftRefLRUPolicyMSPerMB=1000:设置软引用对象的空闲生存时间。每个软引用对象会有一个时间戳,JVM会根据这个时间戳和上次GC后的间隔时间来决定是否回收软引用对象。-XX:+UnlockExperimentalVMOptions:解锁试验阶段的JVM选项,对于生产环境,应慎用此参数。-Xss256k:设置每个线程的栈大小为256K,这个值需要根据程序的线程需求来设定。-XX:+UseG1GC:使用G1垃圾收集器。-XX:MaxGCPauseMillis=150:设置G1GC的最大停顿时间,单位是毫秒。-XX:G1HeapWastePercent=5:设置G1GC在mixed GC之后,堆中可以浪费的最大空间百分比。-XX:G1NewSizePercent=10 -XX:G1MaxNewSizePercent=30:设置新生代堆的最小大小和最大大小百分比。-XX:InitiatingHeapOccupancyPercent=35:设置当堆占用率达到这个百分比后,就开启并发GC。-XX:G1MixedGCCountTarget=64:设置混合GC的目标次数。-XX:MaxHeapFreeRatio=15 -XX:MinHeapFreeRatio=5:设置堆空间空闲比例的上限和下限。-Dsun.rmi.dgc.server.gcInterval=2592000000 -Dsun.rmi.dgc.client.gcInterval=2592000000:设置RMI系统的GC间隔。-XX:ParallelGCThreads=4:设置并行GC时的线程数。这个值和具体的CPU核数有关,一般来说,这个值设置为和CPU核数相同是比较合适的。-Xloggc:/home/admin/logs/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/admin/logs/java.hprof:这些参数是关于GC日志和堆转储的设置。-Djava.awt.headless=true:运行在无头模式,适合服务器环境。-Dsun.net.client.defaultConnectTimeout=3000 -Dsun.net.client.defaultReadTimeout=3000:设置默认的连接超时和读取超时时间。-Dfile.encoding=UTF-8:设置文件编码为UTF-8。在这些参数中,大部分的设定都是合理的。不过有一个参数可能需要调整,那就是-XX:ParallelGCThreads=4,因为你的机器有12核,所以这个参数可以设置为12,这样可以充分利用CPU资源进行垃圾收集。另外,元空间的大小也可能需要根据实际情况进行调整。如果你的应用有大量的类或者大量的动态生成类,可能需要增大元空间的大小。
3. GC日志
# Java8及以下-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:# Java9及以上-Xlog:gc*::time
4. 内存栈
jstack> jstack.log #jstack生成,推荐 jcmdThread.print > jstack.log #jcmd生成
5. Linux日志(用于分析VM 层面 OOM情况)
sudo dmesg|grep -i kill|less或者grep /var/log/kern.log* -ie kill

6. JAVA日志(有具体的OOM信息最好)
#/path/to/your/logfile 替换为 日志地址grep "java.lang.OutOfMemoryError" /path/to/your/logfile#如果日志文件是压缩文件(如.log.gz),你可以使用zgrep命令zgrep "java.lang.OutOfMemoryError" /path/to/your/logfile.gz#如果是多个文件的话在日志地址上增加通配符grep "java.lang.OutOfMemoryError" /path/to/your/logs/*.log
Step2 : 判断JVM内存问题来源
Step2.1 确认到底是哪个进程的内存问题
Step2.2 判断是否是JVM内存泄漏:内存占用缓慢增加一定是内存泄漏吗?
-
首先内存占用缓慢增加不一定是内存泄漏,如果是服务重启之后内存缓慢上涨,不一定是内存泄漏问题:
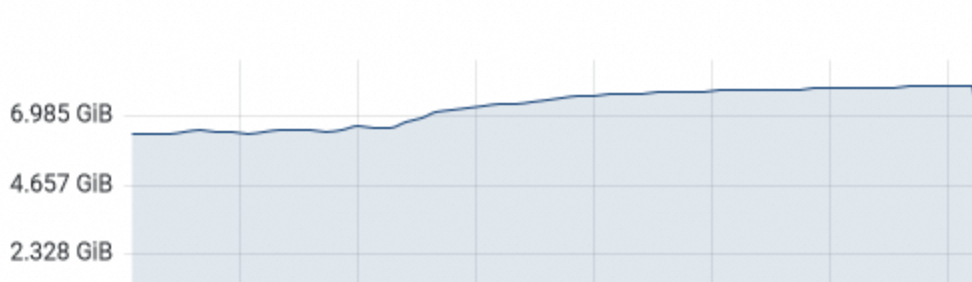
-
其次docker占用内存上升并不代表JVM占用内存也同步上升,最好还是看JVM监控指标。
Step2.3 分析日志
Step2.4 根据现象初步判断问题所在内存区域
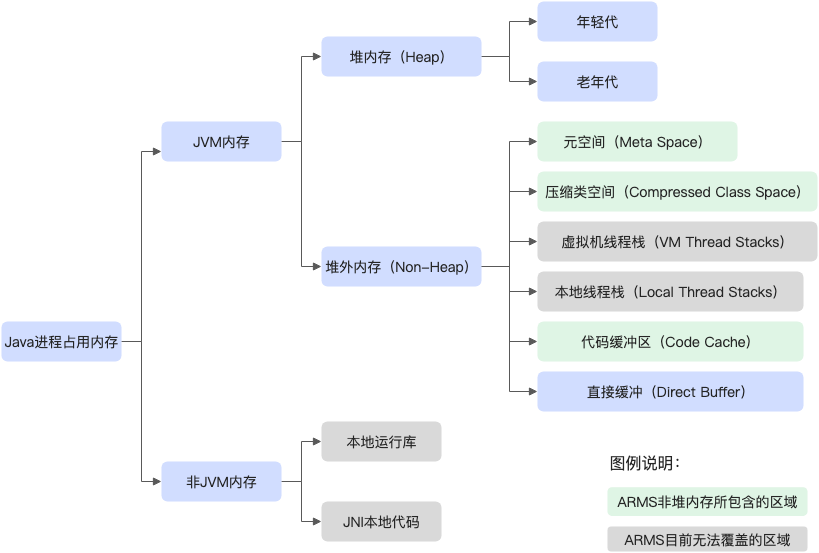
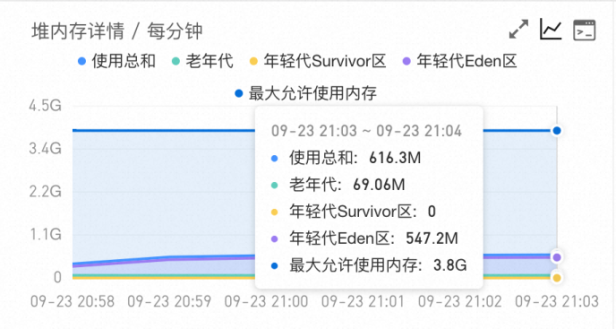
-
ARMS堆监控堆内存一直缓慢上涨 -> 跳转Step3 堆内问题排查;
-
ARMS堆监控堆内存保持不变,使用总和接近最大允许使用内存(同时伴随大量FulllGC) -> 跳转Step3 对内内存排查。
-
JVM监控在启动后或者某个时间点开始,MetaSpace 的已使用大小在持续增长,同时每次 GC 也无法释放,调大 MetaSpace 空间也无法彻底解决。-> 跳转Step4 堆外问题排查。
-
内存使用率不断上升,甚至开始使用 SWAP 内存,同时可能出现 GC 时间飙升,线程被 Block 等现象,通过 top 命令发现 Java 进程的 RES 甚至超过了 -Xmx 的大小。出现这些现象时,基本可以确定是出现了堆外内存泄漏。-> 跳转Step4 堆外问题排查。
Step3 : 堆内问题排查
-
工具
-
ATP GC分析[6]:分析GC, 同类功能有EasyGC.
-
ATP 堆分析[7]: 类似MAT的在线平台:内部工具grace产品化, 可以快速使用。
-
MAT 堆分析:最推荐的堆内存分析工具,可以通过内存快照, 有一定的学习成本,推荐花点时间完整学一遍非常有用。ps: 扩展阅读-》常用第三方工具部分 会列出常用场景和OQL,帮助快速使用。
-
命令,从上到下排查,从整体到局部,从JVM到系统本身
-
jstat -gcutil
:获取JAVA堆,元空间,gc信息,详情参见扩展阅读示例 -
jmap -heap
:Java进程的堆内存详情,看在线情况 -
jmap -histo
:生成堆中的对象直方图:快速识别哪些类的实例占用了大量的堆内存 -
arthas的memory命令 :查看堆和对外具体信息,详情参见扩展阅读部分Arthas
-
pmap -x | sort -nrk3 | less :获取大内存块特别是堆,栈,代码段具体位置和布局
Step4 : 堆外问题排查
元空间 :
异常现象:
简要思路:定位具体类位置
查看类加载情况
#显示指定进程的类加载器相关的统计信息Jmap -clstats: #监视类加载器的行为,包括加载、卸载的类的数量以及相关的内存消耗。Jstat -class#统计在JVM的类加载中,每一个类的实例数量,并按照数量降序排列。jcmdGC.class_stats|awk '{print$13}'|sed 's/(.*).(.*)/1/g'|sort |uniq -c|sort -nrk1 #arthas的classloader命令玩法比较多,有一定学习成本arthas的classloader命令
追踪类加载,卸载情况:
简要思路:关注点,具体见扩展阅读-》案例部分
-
关注 fastjson, beanCopy, Orika, Groovy, 反射,CGLIB 动态代理
-
是否有设置-XX:MaxMetaspaceSize 元空间最大值
DirectMemory和JNI Memory
异常现象:
排查策略
DirectMemory关注点(详见 扩展阅读-》案例部分)
JNI Memory关注点(详见 扩展阅读-》案例部分)
-
方向1:1.gpertools分析谁没有释放内存:定位C、C++的函数 2.确认C、C++的函数对应的Java 方法 3.jstack或arthas的stack命令:Java方法对应的调用栈; -
方向2:1.pmap定位内存块的分布:查看哪些内存块的Rss、Swap占用大 2.dump出内存块,打印出内存数据:把内存中的数据,打印成字符串,分析是什么数据 方向2具体操作参见pmap指令部分[9]和扩展阅读-》案例部分;
栈问题
Stackoverflow :
-
程序直接抛出StackOverflowError异常:直接可以检查 Java 调用栈看是哪个方法触发了溢出。注意,JVM可能不会完全打印所有栈帧,因为栈帧输出数量默认限制为1024(XX:MaxJavaStackTraceDepth=1024)。若需完整栈信息,将此参数设为-1。 -
分析Crash日志:如果进程崩溃后留下了Crash日志,查看日志中”Current thread”的栈范围和RSP寄存器的值。如果RSP值超出了栈范围,说明是栈溢出导致崩溃。 -
利用核心转储(core dump)分析:如果没有Crash日志,你需要依赖核心转储文件。在程序运行前设置ulimit -c unlimited来允许核心转储。进程崩溃时会生成core. 文件,使用jstack $JAVA_HOME/bin/java core. 来分析栈信息。检查是否有异常长的调用链。注意,使用jstack提取信息可能受到serviceability agent(SA)的bug影响。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
OutOfMemoryError: unable to create new native thread
-
应用层面上分析线程,判断是否创建了过多的线程,谁创建的这些线程。线程的变化趋势也可以通过ARMS的监控监控到,线程相关分析可以使用ATP-线程分析功能[11]。
-
线程数触限:系统层面上对线程数有相关限制,可以通过ulimit -u 查看,可以适当调大系统线程数。
-
内存耗尽:财大气粗就升配,没有必要就评估一下减少-xss(会有stackflowerror风险)
(一) JVM 内存简述
1. 堆内存(Heap):
简介:

关联异常类型:
相关参数:
相关问题:
问题1 :ARMS监控为什么显示堆内存和我设置的不同?
问题2 :Xmx(Heap的最大大小)设置多大合适?
2. 堆外内存:元空间(MetaSpace):
简介:
-
Klass MetaSpace:就是用来存 Klass 的,就是 Class 文件在 JVM 里的运行时数据结构,这部分默认放在 压缩类空间 中,是一块连续的内存区域,紧接着 Heap。Compressed Class Pointer Space 不是必须有的,如果设置了 -XX:-UseCompressedClassPointers,或者 -Xmx 设置大于 32 G,就不会有这块内存,这种情况下 Klass 都会存在 NoKlass Metaspace 里。 -
NoKlass MetaSpace: 专门来存 Klass 相关的其他的内容,比如 Method,ConstantPool 等,可以由多块不连续的内存组成。虽然叫做 NoKlass Metaspace,但是也其实可以存 Klass 的内容,上面已经提到了对应场景。
关联异常类型:
关联异常现象:
相关参数:
相关问题:
问题1 :Metaspace和PermGen有什么区别?
问题2 :堆内存使用量不高,为何会发生一次FULL GC?
问题3:如何查看元空间内的信息或者获取元空间的具体对象?
jcmd GC.class_stats|awk '{print$13}'|sed 's/(.*).(.*)/1/g'|sort |uniq -c|sort -nrk1 3. 堆外内存:直接缓存(Direct Buffer):
简介:
关联异常类型:
关联异常现象:
相关参数:
相关问题:
问题1 :哪些地方使用了Direct Memory?
问题2:Netty内存泄漏如何排查?
-
disabled 完全关闭内存泄露检测
-
simple 以约1%的抽样率检测是否泄露,默认级别
-
advanced 抽样率同simple,但显示详细的泄露报告
-
paranoid 抽样率为100%,显示报告信息同advanced
WARNING: 1 leak records were discarded because the leak record count is limited to 4. Use system property io.netty.leakDetection.maxRecords to increase the limit.Recent access records: 5#5:io.netty.buffer.AdvancedLeakAwareCompositeByteBuf.readBytes(AdvancedLeakAwareCompositeByteBuf.java:476)io.netty.buffer.AdvancedLeakAwareCompositeByteBuf.readBytes(AdvancedLeakAwareCompositeByteBuf.java:36)com.jd.jr.keeplive.front.service.nettyServer.handler.LongRotationServerHandler.getClientMassageInfo(LongRotationServerHandler.java:169)com.jd.jr.keeplive.front.service.nettyServer.handler.LongRotationServerHandler.handleHttpFrame(LongRotationServerHandler.java:121)com.jd.jr.keeplive.front.service.nettyServer.handler.LongRotationServerHandler.channelRead(LongRotationServerHandler.java:80)io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:362)io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:348)io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:340)io.netty.channel.ChannelInboundHandlerAdapter.channelRead(ChannelInboundHandlerAdapter.java:86)......
4. JNI内存:
简介:
private native int inflateBytes(long addr, byte[] b, int off, int len);
关联异常类型:
相关参数:
相关问题:
问题1 :JNI问题的排查思路?
-
方向1:1.gpertools分析谁没有释放内存:定位C、C++的函数 2.确认C、C++的函数对应的Java 方法 3.jstack或arthas的stack命令:Java方法对应的调用栈
-
方向2:1.pmap定位内存块的分布:查看哪些内存块的Rss、Swap占用大 2.dump出内存块,打印出内存数据:把内存中的数据,打印成字符串,分析是什么数据 方向2具体操作参见pmap指令部分[13]和案例《一次Java内存占用高的排查案例,解释了我对内存问题的所有疑问》
5. Stack(栈内存)[包括 本地线程栈(Native Stack) 和 虚拟机线程栈(VM Stack)]:
简介:
-
VM Stack(Java虚拟机栈) 用于存储线程执行Java方法时所需的信息。当一个方法执行完成后,其对应的栈帧会从栈中弹出,释放该方法所占用的内存空间。每个线程对应一个Java线程栈,大小由-Xss参数控制,默认是1M,当超过1M会报错StackOverFlowError。
-
Native Stack(本地方法栈) 用于存储本地方法(通过Java Native Interface,JNI调用的方法)的信息。本地方法栈与Java虚拟机栈的主要区别在于,它是为本地方法提供内存空间,而不是Java方法。
关联异常类型:
相关参数:
相关问题:
问题1 :如何定位是否是栈溢出?
-
确认StackOverflowError异常:如果遇到StackOverflowError异常,这明显指示栈溢出。你可以检查 Java 调用栈看是哪个方法触发了溢出。注意,Java 虚拟机(JVM)可能不会完全打印所有栈帧,因为栈帧输出数量默认限制为1024(XX:MaxJavaStackTraceDepth=1024)。若需完整栈信息,将此参数设为-1。 -
分析Crash日志:如果进程崩溃后留下了Crash日志,查看日志中”Current thread”的栈范围和RSP寄存器的值。如果RSP值超出了栈范围,说明是栈溢出导致崩溃。 -
利用核心转储(core dump)分析:如果没有Crash日志,你需要依赖核心转储文件。在程序运行前设置ulimit -c unlimited来允许核心转储。进程崩溃时会生成core. 文件,使用jstack $JAVA_HOME/bin/java core. 来分析栈信息。检查是否有异常长的调用链。注意,使用jstack提取信息可能受到serviceability agent(SA)的bug影响。
(二) 常见案例
1. JNI Memory 溢出:
一、Linux使用默认ptmalloc2内存分配器在高并发分配内存时,存在较多内存碎片无法释放
-
治标:调用malloc_trim手动释放内存 -
治本:更换ptmalloc2为jemalloc或者tcmalloc(两者各有优劣,慎重变更)
二、在Java中流对象(FileInputStream)、网络连接对象(Socket)一般都关联了原生资源,对象未关闭导致native内存无法释放
2. 元空间泄漏:
一、FastJson 元空间泄漏相关文章,这类文章在内部和外部都出现过挺多次了,属于比较容易踩的一个坑了:
二、Groovy 导致的元空间泄漏
三、 beanCopy导致的元空间泄漏
3. Direct Memory溢出:
-
top发现JAVA实际占用的RES 甚至超过了 -Xmx 的大小,内存使用率不断上升,甚至开始使用 SWAP 内存,同时可能出现 GC 时间飙升,线程被 Block 等现象。 -
初步判断堆外内存泄漏是否和direct memory强相关。这里可以使用 NMT(NativeMemoryTracking)[24] 进行分析。在项目中添加 -XX:NativeMemoryTracking=detail JVM参数后重启项目(需要注意的是,打开 NMT 会带来 5%~10% 的性能损耗)。使用命令 jcmd pid VM.native_memory detail 查看内存分布。重点观察 total 中的 committed,因为 jcmd 命令显示的内存包含堆内内存、Code 区域、通过 Unsafe.allocateMemory 和 DirectByteBuffer 申请的内存,但是不包含其他 Native Code(C 代码)申请的堆外内存。如果 total 中的 committed 和 top 中的 RES 相差不大,则应为主动申请的Direct Memory未释放造成的。
4. 栈溢出
5. OOM-Killer
-
如果 生产环境容器只有JVM一个进程在跑,JVM 内存参数配置合理,远低于容器内存限制,,还是出现了 OOM Killer 的话,那么恭喜你,大概率是有什么 Native 内存泄漏,请跳转上文排查 JNI Memory 溢出。 -
如果生产环境中有多个进程在跑,比如有JAVA进程,监控日志进程(Filebeat),定时调度脚本等,手动运维变更动作。。。那就需要具体看日志看到底是谁触发oom,oom时的内存分布是什么了。
grep -i 'killed process' /var/log/messages或者egrep "oom-killer|total-vm" /var/log/messages
[20220707-022639][23457.059849] ptz_task invoked oom-killer: gfp_mask=0x24200ca(GFP_HIGHUSER_MOVABLE), nodemask=0, order=0, oom_score_adj=0[20220707-022639][23457.079399] CPU: 0 PID: 732 Comm: ptz_task Not tainted 4.9.191 #4[20220707-022639][23457.104264] Hardware name: sun8iw21.......[20220707-022639][23457.551958] [ pid ] uid tgid total_vm rss nr_ptes nr_pmds swapents oom_score_adj name[20220707-022639][23457.577207] [ 632] 0 632 254 41 3 0 0 0 telnetd[20220707-022639][23457.587485] [ 633] 0 633 232 43 3 0 0 0 adbd[20220707-022639][23457.607393] [ 657] 0 657 585 72 4 0 0 0 wpa_supplicant[20220707-022639][23457.628416] [ 660] 0 660 254 36 3 0 0 0 telnetd[20220707-022639][23457.641304] [ 673] 0 673 244 48 3 0 0 0 sk_srv_syscall[20220707-022639][23457.662083] [ 676] 0 676 17203 4349 35 0 0 0 skyapp[20220707-022639][23457.682194] [ 677] 0 677 254 41 3 0 0 0 exe[20220707-022639][23457.698911] [ 899] 0 899 1056 97 6 0 0 0 skmongoose[20220707-022639][23457.712344] [ 900] 0 900 254 41 3 0 0 0 clearCached.sh[20220707-022639][23457.733172] [ 921] 0 921 254 33 3 0 0 0 udhcpc[20220707-022639][23457.752165] [ 1210] 0 1210 254 42 3 0 0 0 ash[20220707-022639][23457.762516] [11670] 0 11670 254 41 3 0 0 0 sleep[20220707-022639][23457.773158] [12021] 0 12021 228 24 3 0 0 0 sleep[20220707-022639][23457.788033] [12023] 0 12023 244 48 3 0 0 0 sk_srv_syscall[20220707-022639][23457.819352] Out of memory: Kill process 676 (skyapp) score 276 or sacrifice child[20220707-022639][23457.838273] Killed process 676 (skyapp) total-vm:68812kB, anon-rss:16536kB, file-rss:820kB, shmem-rss:40kB[20220707-022639][23457.882911] oom_reaper: reaped process 676 (skyapp), now anon-rss:0kB, file-rss:0kB, shmem-rss:40kB
Top


-
21:08:13:系统当前时间 -
up 1 day:系统开机后到现在的总运行时间 -
3 user:当前登录用户数 -
load average: 0.12, 0.08, 0.06:系统负载,系统运行队列的平均利用率,可认为是可运行进程平均数;三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。

-
total:系统全部进程的数量 -
running:运行状态的进程数量 -
sleeping:睡眠状态的进程数量 -
stoped:停止状态的进程数量 -
zombie:僵尸进程数量

-
us:用户空间占用CPU百分比 -
sy:内核空间占用CPU百分比 -
ni:已调整优先级的用户进程的CPU百分比 -
id:空闲CPU百分比,越低说明CPU使用率越高 -
wa:等待IO完成的CPU百分比 -
hi:处理硬件中断的占用CPU百分比 -
si:处理软中断占用CPU百分比 -
st:虚拟机占用CPU百分比

-
total:物理内存总量 -
free:空闲内存总量 -
used:使用中内存总量 -
buw/cache:用于内核缓存的内存量

-
total:交换区总量 -
free:空闲交换区总量 -
used:使用的交换区总量 -
avail Mem:可用交换区总量

-
top 输出界面的顶端,也显示了系统整体的内存使用情况,这些数据跟 free 类似。
-
PID:进程号
-
USER:运行进程的用户
-
PR:优先级
-
NI:nice值。负值表示高优先级,正值表示低优先级
-
VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内。
-
RES 是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享 内存。
-
SHR 是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及 程序的代码段等。
-
S:进程状态 (R运行状态 S睡眠状态 D不可中断状态 T跟踪/停止 Z僵尸进程)
-
%CPU:CPU 使用率
-
%MEM:进程使用物理内存占系统总内存的百分比
-
TIME+:上次启动后至今的总运行时间
-
COMMAND:命令名or命令行
pmap
pmap [options] pid [...]-x, --extended :显示扩展格式。-d, --device :显示设备格式。-q, --quiet :不显示 header 和 footer 行。-A, --range low,high :将给定范围内的结果限制为低地址和高地址范围。请注意,low 和 high 参数是用逗号分隔的单个字符串。-X :显示比 -x 选项更多的详细信息。注意:格式根据 /proc/PID/smaps 更改。-XX :显示内核提供的一切。-p, --show-path :在映射列中显示文件的完整路径。-c, --read-rc :读取默认配置。-C, --read-rc-from file :从文件 file 中读取配置。-n, --create-rc :创建新的默认配置。-N, --create-rc-to file :创建新的配置,并保存到文件。-h, --help :显示帮助信息并退出。-V, --version :显示版本信息并退出。
-
检查那些占用内存较大的内存段,如下
pmap -x 1 | sort -nrk3 | less-
检查一段时间后新增了哪些内存段,或哪些变大了,如下:在不同的时间点多次保存pmap命令的输出,然后通过文本对比工具查看两个时间点内存段分布的差异。
pmap -x 1 > pmap-`date +%F-%H-%M-%S`.log
-
icdiff 获取新增内存块
icdiff pmap-2023-07-27-09-46-36.log pmap-2023-07-28-09-29-55.log | less -SR
-
查看变化的内存块内存储的字符串:
tail -c +$((0x00007face0000000+1)) /proc/$pid/mem|head -c $((11616*1024))|strings|less -S命令解释:
-
tail: 是一个常用的文本处理命令,用来输出文件的最后部分。
-
-c: 表示操作字节而不是行。
-
+$((0x00007face0000000+1)): 这部分是算术扩展,它将十六进制数 0x00007face0000000 转换为十进制,并加 1。表示 tail 命令将从这个偏移量开始输出 /proc/$pid/mem 文件的内容。
-
/proc/$pid/mem: 是一个特殊的文件,它代表内核中进程号为1的内存映像。
-
head: 与 tail 相对,用来输出文件的开始部分。
-
-c: 同样表示操作字节。
-
$((11616*1024)): 算术扩展,计算出要输出的字节数。11616 乘以 1024 等于要读取的字节总数,换算为约 11.6MB 的数据。
-
strings: 是一个工具,用来从二进制文件中提取可打印的字符串序列。
-
less: 是一个分页查看工具,允许前后翻阅文件。
-
-S: 选项使得 less 不会折叠超长的行,即不会自动换行。
Jcmd
Jhat
Jps
jinfo
jstat


jstack
1)使用Process Explorer工具找到cpu占用率较高的线程
2)在thread卡中找到cpu占用高的线程id
3)线程id转换成16进制
4)使用jstack -l 查看进程的线程快照 根据16进制id找到对应线程
jmap
(四) 常用第三方工具
1. ATP

-
使用ATP Java堆分析-》分析垃圾对象模式 有点bug,解析的时候会卡死,猜测是和后端用的机器内存不够。还是推荐使用MAT。 -
之前ATP不支持基于OQL的分析,但是前两天又用ATP的时候发现新增了好多功能,也支持了OQL, 新增了好多新的功能包括ByteBuffer,JVM等,非常非常牛批!(小小说一句功能上了但是文档没跟上。。。比如新增的容器对象就没有说明)
2. ARMS
3. MAT

-
jmap命令需要保存整个Java堆:jmap -dump:format=b,file=heap.bin -
MAT默认是只分析reachable对象实例,所以在”Preferences=>Memory Analyzer”中勾选”Keep Unreachable Objects”,删除索引文件Dump同路径下的所有”.index”,即可看到所有的对象。 -
对于可疑对象可以用OQL查询对象。
SELECT * FROM [ INSTANCEOF ] [ WHERE ] 按类型查找实例:SELECT * FROM java.lang.String
按类型查找对应的类实例:SELECT * FROM OBJECTS java.lang.String按地址查询:SELECT * FROM 0xcafebabe按类型查找实例, 并根据字段过滤:SELECT * FROM java.lang.String s WHERE s.value.@length > 10按类型查找实例, 并根据字段过滤:SELECT * FROM java.lang.String s WHERE toString(s) LIKE ".*center"按数组长度查询数组:SELECT * FROM int[] a where a.@length >= 1024 and a.@length查询所有DirectByteBuffer并根据字段过滤:SELECT * FROM java.nio.DirectByteBuffer d WHERE d.cleaner != null查询所有HashMap内容:SELECT h[0:-1] AS KeyValuePairs, h.table.@length AS Length FROM java.util.HashMap h查看所有线程栈顶:SELECT t AS Thread, ${snapshot}.getThreadStack(t.@objectId).@stackFrames[0].@text AS Frame FROM java.lang.Thread t
4. Jprofile
5. gperftools
6. arthas
参考文档
[1]https://help.aliyun.com/zh/atp/getting-started/preparations
[2]https://help.aliyun.com/zh/arms/application-monitoring/user-guide/memory-snapshot
[3]https://codefresh.io/blog/docker-memory-usage/
[4]https://help.aliyun.com/zh/arms/application-monitoring/use-cases/identify-business-exceptions-by-analyzing-traces-and-logs
[5]https://help.aliyun.com/zh/sls/user-guide/configure-alerts-based-on-log-keywords
[6]https://help.aliyun.com/zh/atp/user-guide/overview-of-analysis-views-1
[7]https://help.aliyun.com/zh/atp/user-guide/overview-of-analysis-views
[8]https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/tooldescr007.html
[9]https://ata.atatech.org/articles/new?draftId=50021023#kNwNS
[10]https://developer.aliyun.com/article/713353
[11]https://help.aliyun.com/zh/atp/getting-started/java-thread-stack-analysis-quick-start
[12]https://juejin.cn/post/7225875600644407357
[13]https://ata.atatech.org/articles/new?draftId=50021023#kNwNS
[14]https://juejin.cn/post/7255634554987020343
[15]https://juejin.cn/post/6854573220733911048
[16]https://juejin.cn/post/7078624931826794503
[17]https://zhuanlan.zhihu.com/p/652545321
[18]https://juejin.cn/post/6865231944390148103
[19]https://cloud.tencent.com/developer/article/2001945
[20]https://heapdump.cn/article/1924890
[21]https://juejin.cn/post/7295626801287610408
[22]https://blog.csdn.net/a807719447/article/details/123583849
[23]https://www.ucloud.cn/yun/74742.html
[24]https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/tooldescr007.html
[25]https://tech.meituan.com/2018/10/18/netty-direct-memory-screening.html
[26]https://cloud.tencent.com/developer/article/2315550?areaId=106001
[27]https://blog.51cto.com/u_16213354/7186633
[28]https://www.slf4j.org/codes.html#log4jDelegationLoop
[29]https://developer.aliyun.com/article/713353
[30]https://dzone.com/articles/troubleshoot-outofmemoryerror-unable-to-create-new
[31]https://help.aliyun.com/zh/alinux/support/causes-of-and-solutions-to-the-issue-of-oom-killer-being-triggered
[32]https://help.aliyun.com/zh/edas/user-guide/why-does-the-running-process-of-an-application-suddenly-disappear
[33]https://blog.csdn.net/weixin_39247141/article/details/126304526
[34]https://zhuanlan.zhihu.com/p/373307892
[35]https://help.aliyun.com/zh/atp/user-guide/overview-of-analysis-views-1
[36]https://heapdump.cn/article/2836272
[37]https://zhuanlan.zhihu.com/p/57347496
[38]https://juejin.cn/post/6908665391136899079
[39]https://help.aliyun.com/zh/atp/user-guide/oql-tutorial
[40]https://wiki.eclipse.org/MemoryAnalyzer/OQL
[41]https://help.eclipse.org/latest/index.jsp?topic=%2Forg.eclipse.mat.ui.help%2Freference%2Foqlsyntax.html&cp=66_4_2
0 条评论