浏览次数: 252
Transformer,6岁了!2017年,Attention is All You Need奠基之作问世,至今被引数近8万。这个王者架构还能继续打多久?
2017年6月12日,Attention is All You Need,一声炸雷,大名鼎鼎的Transformer横空出世。
它的出现,不仅让NLP变了天,成为自然语言领域的主流模型,还成功跨界CV,给AI界带来了意外的惊喜。
到今天为止,Transformer诞生6周年。而这篇论文被引数高达77926。
英伟达科学家Jim Fan对这篇盖世之作做了深度总结:
1. Transformer并没有发明注意力,而是将其推向极致。
这篇论文来自Yoshua Bengio的实验室,而标题并不起眼「Neural Machine Translation by Jointly Learning to Align and Translate」。
或许很多人都没有听说过这篇论文,但它是NLP中最伟大的里程碑之一,已经被引用了29K次(相比之下,Transformer为77K)。
2. Transformer和最初的注意力论文,都没有谈到通用序列计算机。
相反,两者都为了解决一个狭隘而具体的问题:机器翻译。值得注意的是,AGI(不久的某一天)可以追溯到不起眼的谷歌翻译。
3. Transformer发表在2017年的NeurIPS上,这是全球顶级的人工智能会议之一。然而,它甚至没有获得Oral演讲,更不用说获奖了。
那一年的NeurIPS上有3篇最佳论文。截止到今天,它们加起来有529次引用。
Transformer这一经典之作却在NeurIPS 2017没有引起很多人的关注。
对此,Jim Fan认为,在一项出色的工作变得有影响力之前,很难让人们认可它。
我不会责怪NeurIPS委员会——获奖论文仍然是一流的,但影响力没有那么大。一个反例是ResNet。
何凯明等人在CVPR 2016年获得了最佳论文。这篇论文当之无愧,得到了正确的认可。
2017年,该领域聪明的人中,很少有人能够预测到今天LLM革命性的规模。就像20世纪80年代一样,很少有人能预见自2012年以来深度学习的海啸。
OpenAI科学家Andrej Karpathy对Jim Fan第2点总结颇感兴趣,并表示,
介绍注意力的论文(由@DBahdanau , @kchonyc , Bengio)比 「Attention is All You Need」的论文受到的关注要少1000倍。而且从历史上看,这两篇论文都非常普通,但有趣的是恰好都是为机器翻译而开发的。
Transformer诞生之前,AI圈的人在自然语言处理中大都采用基于RNN(循环神经网络)的编码器-解码器(Encoder-Decoder)结构来完成序列翻译。
然而,RNN及其衍生的网络最致命的缺点就是慢。关键问题就在于前后隐藏状态的依赖性,无法实现并行。
Transformer的现世可谓是如日中天,让许多研究人员开启了追星之旅。
2017年,8位谷歌研究人员发表了Attention is All You Need。可以说,这篇论文是NLP领域的颠覆者。

论文地址:https://arxiv.org/pdf/1706.03762.pdf
它完全摒弃了递归结构,依赖注意力机制,挖掘输入和输出之间的关系,进而实现了并行计算。
甚至,有人发问「有了Transformer框架后是不是RNN完全可以废弃了?」
JimFan所称Transformer当初的设计是为了解决翻译问题,毋庸置疑。
谷歌当年发的博客,便阐述了Transformer是一种语言理解的新型神经网络架构。

文章地址:https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
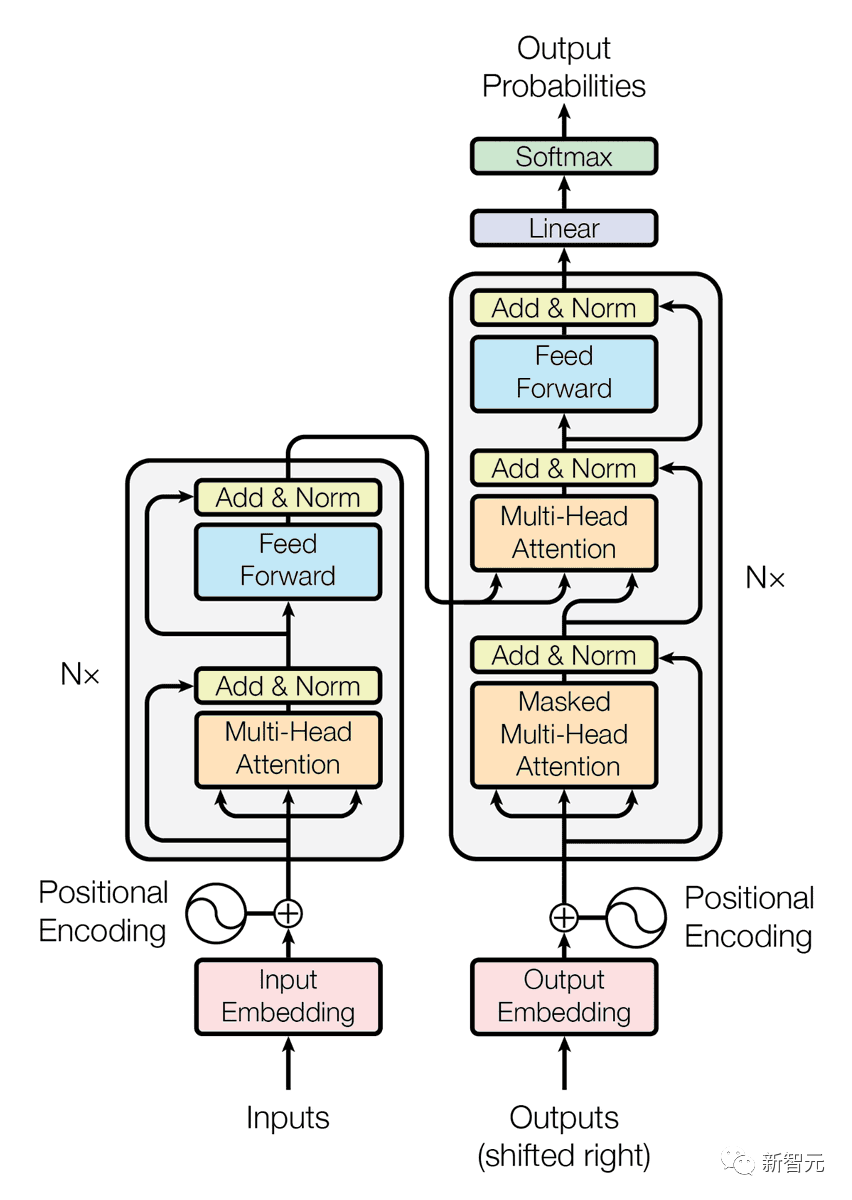
具体来讲,Transformer由四部分组成:输入、编码器、解码器,以及输出。
输入字符首先通过Embedding转为向量,并加入位置编码(Positional Encoding)来添加位置信息。
然后,通过使用多头自注意力和前馈神经网络的「编码器」和「解码器」来提取特征,最后输出结果。
如下图所示,谷歌给出了Transformer如何用在机器翻译中的例子。
机器翻译的神经网络通常包含一个编码器,在读取完句子后生成一个表征。空心圆代表着Transformer为每个单词生成的初始表征。
然后,利用自注意力,从所有其他的词中聚合信息,在整个上下文中为每个词产生一个新表征,由实心圆表示。
接着,将这个步骤对所有单词并行重复多次,依次生成新的表征。
同样,解码器的过程与之类似,但每次从左到右生成一个词。它不仅关注其他先前生成的单词,还关注编码器生成的最终表征。
自此,在自然语言处理中,Transformer逆袭之路颇有王者之风。
归宗溯源,现在各类层出不穷的GPT(Generative Pre-trained Transformer),都起源于这篇17年的论文。
然而,Transformer燃爆的不仅是NLP学术圈。
2017年的谷歌博客中,研究人员曾对Transformer未来应用潜力进行了畅享:
不仅涉及自然语言,还涉及非常不同的输入和输出,如图像和视频。
没错,在NLP领域掀起巨浪后,Transformer又来「踢馆」计算机视觉领域。甚至,当时许多人狂呼Transformer又攻下一城。
自2012年以来,CNN已经成为视觉任务的首选架构。
随着越来越高效的结构出现,使用Transformer来完成CV任务成为了一个新的研究方向,能够降低结构的复杂性,探索可扩展性和训练效率。
2020年10月,谷歌提出的Vision Transformer (ViT),不用卷积神经网络(CNN),可以直接用Transformer对图像进行分类。
值得一提的是,ViT性能表现出色,在计算资源减少4倍的情况下,超过最先进的CNN。
紧接着,2021年,OpenAI连仍两颗炸弹,发布了基于Transformer打造的DALL-E,还有CLIP。
这两个模型借助Transformer实现了很好的效果。DALL-E能够根据文字输出稳定的图像。而CLIP能够实现图像与文本的分类。
再到后来的DALL-E进化版DALL-E 2,还有Stable Diffusion,同样基于Transformer架构,再次颠覆了AI绘画。
以下,便是基于Transformer诞生的模型的整条时间线。
2021年,当时就连谷歌的研究人员David Ha表示,Transformers是新的LSTMs。
而他曾在Transformer诞生之前,还称LSTM就像神经网络中的AK47。无论我们如何努力用新的东西来取代它,它仍然会在50年后被使用。
Transformer仅用4年的时间,打破了这一预言。
如今,6年过去了,曾经联手打造出谷歌最强Transformer的「变形金刚们」怎么样了?
Jakob Uszkoreit被公认是Transformer架构的主要贡献者。
他在2021年中离开了Google,并共同创立了Inceptive Labs,致力于使用神经网络设计mRNA。
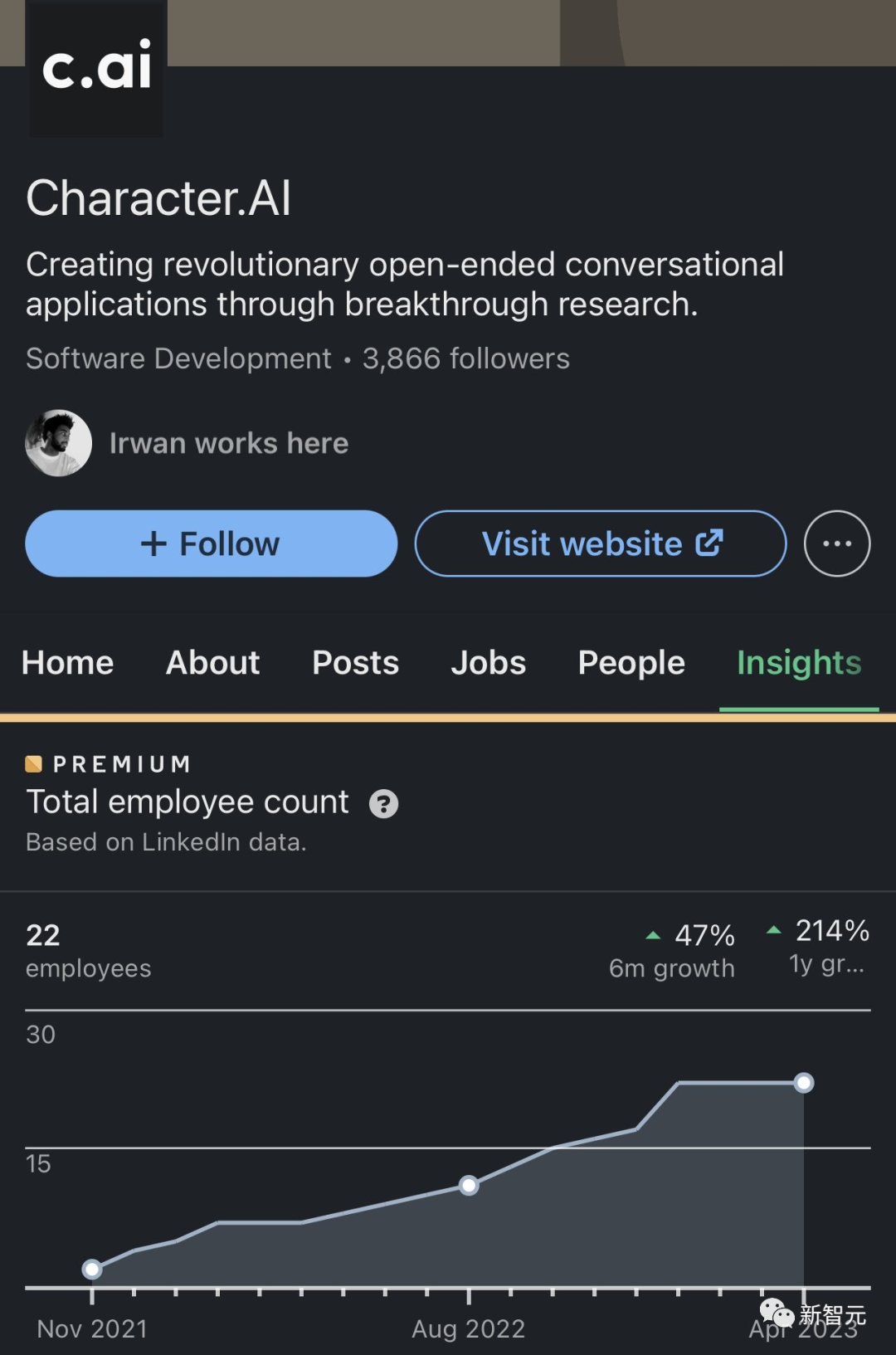
到目前为止,他们已经筹集了2000万美元,并且团队规模也超过了20人。
Ashish Vaswani在2021年底离开Google,创立了AdeptAILabs。
可以说,AdeptAILabs正处在高速发展的阶段。
目前,公司不仅已经筹集了4.15亿美元,而且也估值超过了10亿美元。
在Transformers论文中,Niki Parmar是唯一的女性作者。
她在2021年底离开Google,并和刚刚提到的Ashish Vaswani一起,创立了AdeptAILabs。
Noam Shazeer在Google工作了20年后,于2021年底离开了Google。
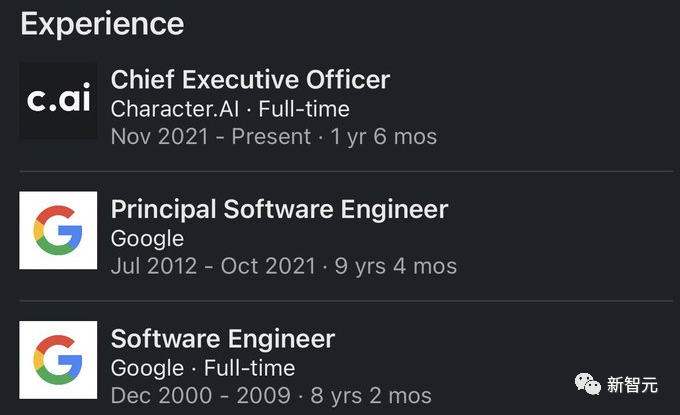
随后,他便立刻与自己的朋友Dan Abitbol一起,创立了Character AI。
目前,他们已经筹集了近2亿美元,并即将跻身独角兽的行列。
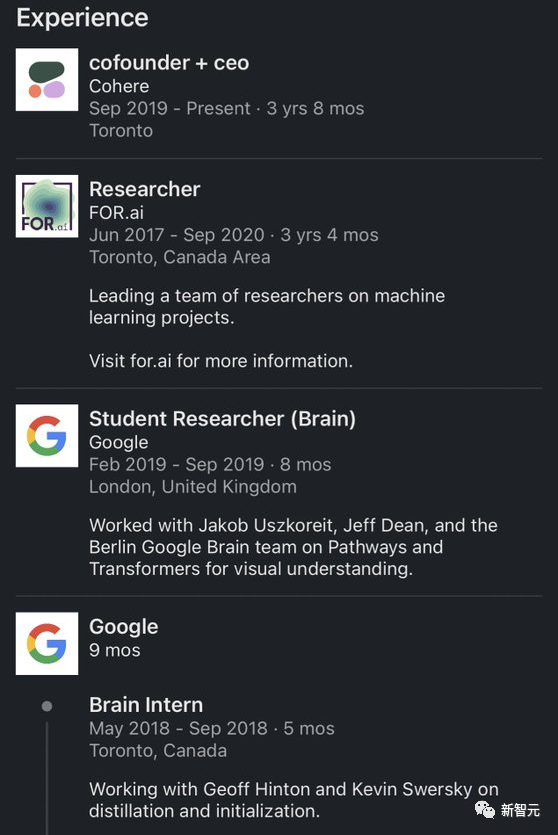
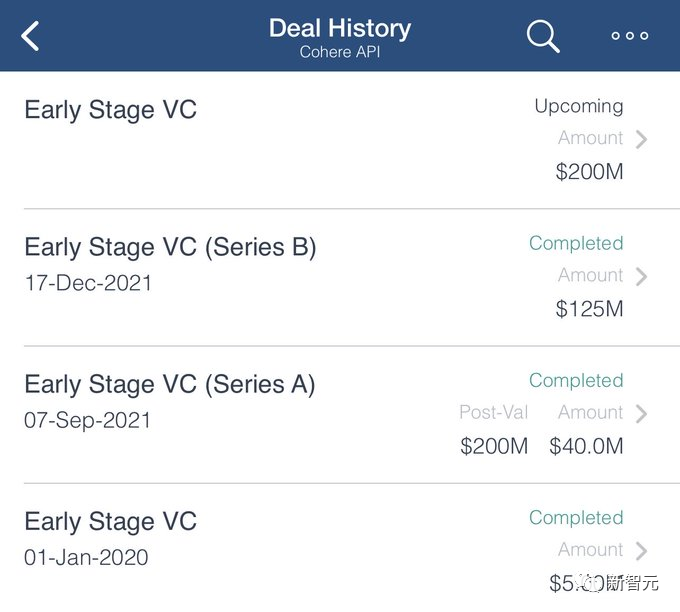
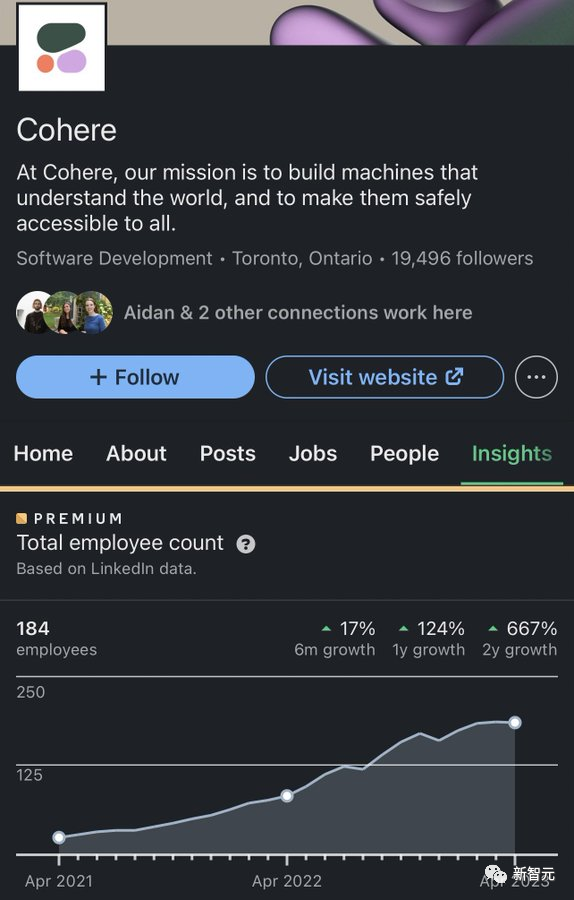
Aidan Gomez在2019年9月离开了Google Brain,创立了CohereAI。
经过3年的稳定发展后,公司依然正在扩大规模——Cohere的员工数量最近超过了180名。
与此同时,公司筹集到的资金也即将突破4亿美元大关。
Lukasz Kaiser是TensorFlow的共同作者人之一,他在2021年中离开了Google,加入了OpenAI。
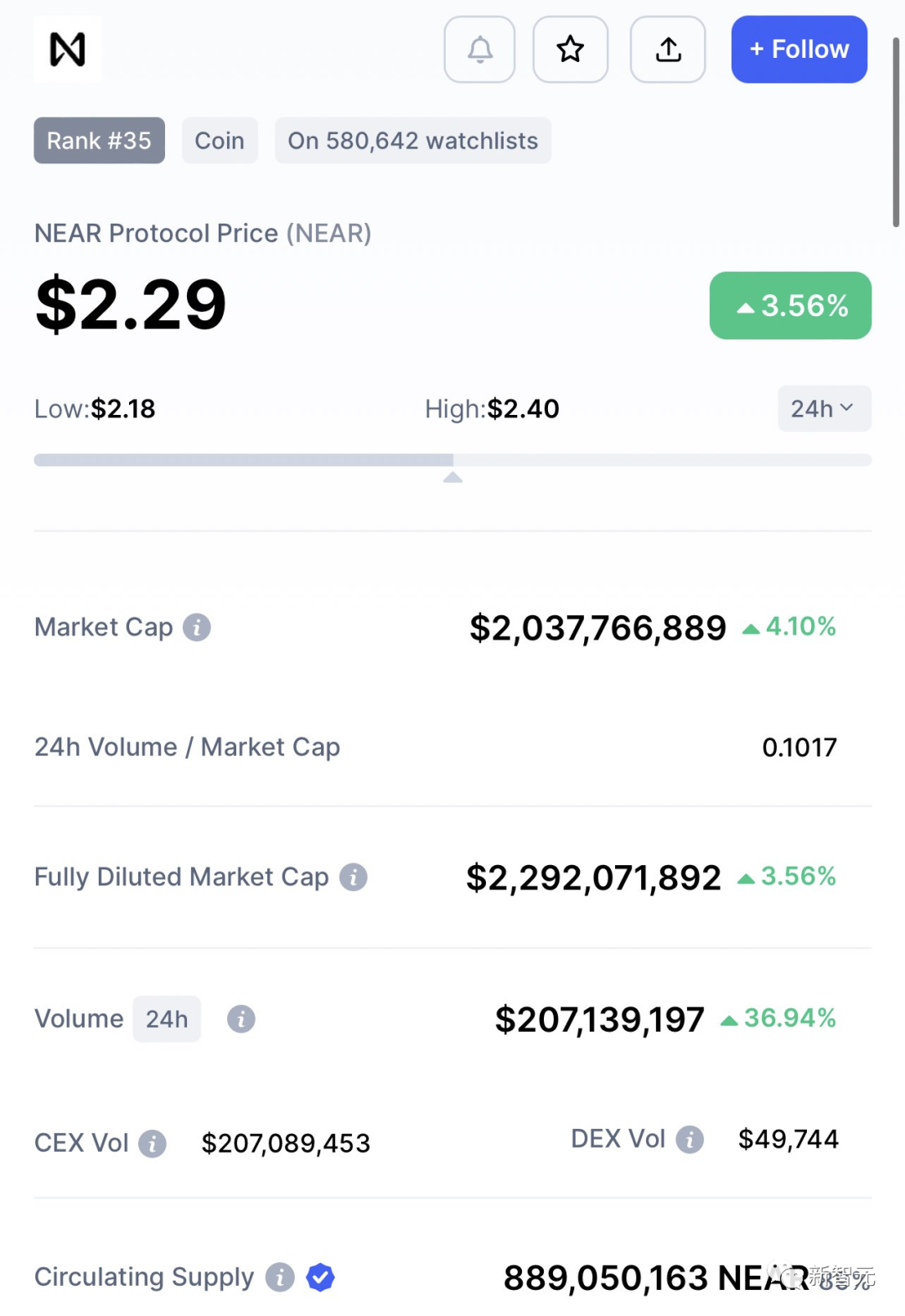
Illia Polosukhin在2017年2月离开了Google,于2017年6月创立了NEAR Protocol。
与此同时,公司已经筹集了约3.75亿美元,并进行了大量的二次融资。
在论文的贡献方面,他风趣地调侃道:「自己最大的意义在于——起标题。」
走到现在,回看Transformer,还是会引发不少网友的思考。
马库斯表示,这有点像波特兰开拓者队对迈克尔·乔丹的放弃。
这件事说明了,即使在这样的一级研究水平上,也很难预测哪篇论文会在该领域产生何种程度的影响。
这个故事告诉我们,一篇研究文章的真正价值是以一种长期的方式体现出来的。
哇,时间过得真快!令人惊讶的是,这个模型突破了注意力的极限,彻底改变了NLP。
在我攻读博士期间,我的导师 @WenmeiHwu 总是教育我们,最有影响力的论文永远不会获得最佳论文奖或任何认可,但随着时间的推移,它们最终会改变世界。我们不应该为奖项而奋斗,而应该专注于有影响力的研究!
https://twitter.com/DrJimFan/status/1668287791200108544
https://twitter.com/karpathy/status/1668302116576976906
https://twitter.com/JosephJacks_/status/1647328379266551808



































0 条评论