目录:
1.为什么需要对数据进行脱敏
2.数据脱敏定义及分类
3.数据脱敏核心算法
4.数据脱敏工具技术架构设计
5.数据脱敏技术的实现
1.为什么需要对数据进行脱敏
为了便于市场研究人员和数据挖掘人员利用客户信息、订单数据来分析客户购买行为,需要提供一个与生产环境数据真实性相近的数据,进行数据建模测试新分析算法或功能,同时IT人员测试、修补程序也需要将生产数据复制到测试和开发环境中,以便进行程序的测试。因此一些企业会将大量的敏感客户数据、订单数据拷贝到开发、测试、数据分析环境,但并没有采取任何对数据脱敏的措施。
据安全情报供应商Risk Based Security (RBS) 的2019年Q3季度的报告,2019年1月1日至2019年9月30日,全球披露的数据泄露事件有5183起,泄露的数据量达到了79.95亿条记录!从数据泄露事件数量来看,整体呈现出递增趋势,其中2019年泄露事件(5183)比2018年(3886)上涨33.3%。2019年泄露记录数量(37.66亿)比2018年(79.95亿)上涨112%。
从政策法规方面无论是欧盟的GDPR法案还是国家互联网信息办公室发布的《数据安全管理办法(征求意见稿)》,都有明确对个人隐私信息的保存、使用的规定和处罚措施。欧盟在2018年出台《通用数据保护条例》(GDPR),规定了企业如何收集、使用和处理欧盟公民的个人数据。2019年5月28日,国家互联网信息办公室发布的《数据安全管理办法(征求意见稿)》中,明确要求对于个人信息的保存和提供要经过匿名化处理,以切实降低在数据应用中个人信息可能存在的泄露风险。
2.数据脱敏定义及分类
百度百科对数据脱敏的定义为:指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。在涉及客户安全数据或者一些商业性敏感数据的情况下,在不违反系统规则条件下,对真实数据进行改造并提供测试使用,如身份证号、手机号、卡号、客户号等个人信息都需要进行数据脱敏。
从个人理解来说,数据脱敏就是为原始数据创建结构类似但不真实的数据的方法,以便将数据在开发、测试、培训、分析等非生产环境下的使用。在数据脱敏中只是改变数据值但数据的格式和原始数据保持一致,需要注意的是原始数据不能探测到或者经过转换还原出原始数据。数据脱敏将被广泛应用于遵守政策、法规需求、防止数据泄露、防止数据被意外接触等方面。
数据脱敏工具通过将真实敏感数据按照数据脱敏规则进行转换、处理,去除敏感信息,从而帮助组织实现生产数据的依法依规共享。数据脱敏可以通过各种不同的方法进行实现,但是这些方法都必须遵循数据脱敏的五项基本原则。
1)防逆向破解原则
无论采用哪种脱敏方法,都不能够通过破解方法获取到原始敏感数据。
2)表征原始数据原则
脱敏后数据要保持一定的真实性以便数据能够应用开发、测试、分析的环境。例如对姓名处理,脱敏后形式类似王*凯,而不能采用随意的值来替换姓名。
3)引用完整性原则
经过脱敏后数据要保持引用完整性,例如对银行卡号进行脱敏处理(银行卡号是一个主键)所有引用了银行卡号信息的实体,经过脱敏处理后要能够关联到一起。
4)防数据推理原则
数据脱敏不需要将所有的数据进行脱敏处理,只处理被定义为敏感数据内容。但需要注意的是有些非敏感数据能够被用来重新生成敏感数据或者能够回溯到敏感数据,这些非敏感数据同样需要进行脱敏处理。
5) 自动化原则
针对一个数据源只需要配置一次,就可以重复进行脱敏处理。开发和测试环境的数据需要能够及时反映生产数据的变化。分析数据也需要每天甚至每小时来生成。如果不是通过自动化的方式进行,那么数据脱敏就是一个低效且耗费成本的工作。
3.数据脱敏核心算法
常用的脱敏有混淆、替换、置空、加密:
混淆算法:打乱现有数据的位置,使数据不再表示其原有的含义。
可以使用java的Collection类对数据内容的ArrayList进行顺序打乱,经实际试验效果不太好,无法保证数据项顺序和原来顺序完全不一致。
任意替换:替换敏感数据的内容,使数据看上去和原始数据类似,但实际上两者没有任何关联。常用于姓名替换、数值替换、日期替换及卡号替换等。
置空算法:删除敏感数据将其置空。
数据加密:敏感数据进行加密处理,加密后的数据与原始数据差异较大。
可以使用的数据脱敏算法包括:MD5加密、AES对称加密、FPE格式保留加密等方法。
4.数据脱敏工具技术架构设计
数据脱敏类型可以分为静态脱敏和动态脱敏:
静态数据脱敏(SDM),是数据存储时脱敏,存储的是脱敏数据。一般用在非生产环境,如开发、测试、外包和数据分析等环境。
动态数据脱敏(DDM),在数据使用时脱敏,存储的是明文数据或直接存储密文。一般用在生产环境,动态脱敏可以实现不同用户拥有不同的脱敏策略。
其总体技术架构如下:
电话号码识别,正则表达式((((010)|(0[2-9]\d{1,2}))[-\s]?)[1-9]\d{6,7}$)|((\+?0?86\-?)?1[3|4|5|7|8][0-9]\d{8}$)
银行卡号识别,正则表达式(([13-79]\d{3})|(2[1-9]\d{2})|(20[3-9]\d)|(8[01-79]\d{2}))\s?\d{4}\s?\d{4}\s?\d{4}(\s?\d{3})?$
身份证号识别,正则表达式 [1-9]\d{5}(19|20)\d{9}[0-9Xx]$
邮箱识别,正则表达式 [a-zA-Z0-9_%+-]{1,}@[a-zA-Z0-9-]{1,}\.[a-zA-Z]{2,4}$
姓名、地址采用关键字识别方法,例如姓名中内置三百个姓来做姓名的自动识别,地址中通过街道、区、市、县、村、栋等关键字来匹配。
这里我们使用了Python来实现敏感数据的扫描,只需要配置数据库连接参数,就能自动进行全库扫描。在进行全库扫描时为了防止占用的资源会比较多,通常会设置自动扫描参数,参数包括扫描最大数据量、采样数据量等,当表的数据量少于最大数据量这个阀值时,会进行全表扫描配置。另外一个参数是采样数据量,当表的数据量超过最大数据量时,会对表的数据进行采样,选取其中的一定量的数据(采样数据量)进行扫描。扫描的同时需要对扫描到的敏感数据记录下来。记录的信息包括:数据库IP、数据库用户、数据库、扫描表、扫描字段、敏感数据内容、敏感数据类型、敏感数据率等。
数据动态脱敏使用ShardingSphere分布式治理子功能模块。它通过对用户输入的SQL进行解析,并依据用户提供的脱敏配置对SQL进行改写,从而实现对原文数据进行加密,并将原文数据(可选)及密文数据同时存储到底层数据库。在用户查询数据时,它又从数据库中取出密文数据,并对其解密,最终将解密后的原始数据返回给用户。Apache ShardingSphere分布式数据库中间件屏蔽了数据脱敏过程,让用户无需关注数据脱敏的实现细节,像使用普通数据那样使用脱敏数据。先看下动态数据脱敏的的实现原理:
在使用 ShardingSphere-JDBC进行动态脱敏配置时,有几项关键的脱敏规则配置。
1)数据源配置,可以使用了Druid来做数据源配置,配置多个数据源。ShardingSphere-JDBC可以兼容的数据库连接池比较多,类似于DBCP,C3P0,BoneCP,Druid,HikariCP都可以用来和shardingsphere配合使用。采用Druid做为数据库连接池需要设置驱动、数据库连接地址、用户名、密码即可,filter参数为Druid连接池参数,用于配置监控sql语句的执行。
2)加密器配置, ShardingSphere-JDBC内置了AES/MD5两种加密算法。这里采用了AES对称加密算法,当然用户还可以通过实现ShardingSphere提供的接口,自行实现一套加解密算法。
3)脱敏表配置,比如要把user表中的用户密码进行加密存储。在脱敏表的列配置中plainColumn对应字段存储密码明文、cipherColumn对应字段存储加密后密码。对应的开发人员使用的是逻辑列pwd,开发人员在进行开发过程中,直接面向pwd进行编程即可,不需要关注是否进行加密和解密问题。下面是开发人员使用的mybatis进行的配置,直接使用的pwd字段进行开发。如下图:
参考资料:
1、https://shardingsphere.apache.org/ shardingshpere官网资料
2、A project report on“Masquerade – Data Masking Tool”
3、Risk Based Security. Data Breach QuickViewReport 2019 Q3 trends. 2019-11.
4、https://www.secrss.com/articles/19777 数据脱敏技术发展现状及趋势研究
精选提问:
问1:请问对于图库数据、地理信息数据等非结构化类数据的脱敏,具体的脱敏思路是什么样的,目前有无脱敏的开源工具。
答:图数据库脱敏需还要看应用场景,在分析应用的场景中,数据脱敏一般是在数据加载到图数据之前就已经从生产的数据进行脱敏处理过的了。生产环境图数据库脱敏主要是vertex属性的脱敏,可以参考动态脱敏的技术实现。对图数据库脱敏的开源工具没有进行深入分析过。
问2:如A经B到C,C经D到E,而给我们的关系脱敏后表现为A..B…D..E。类似的这类脱敏如何实现。
答:单独的客户信息,还是有需要进行脱敏处理的。融合关联的得到新信息,比如对客户和订单关联后,分析出客户的购买习惯。需要对客户基本信息、订单基本信息进行脱敏,购买习惯属于分析结果(包含的客户、订单已经脱敏过)不需要在进行脱敏处理。
原文 微信公众号EAWorld
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
敏感数据管理
更新时间:2020-06-16 20:57:55
背景
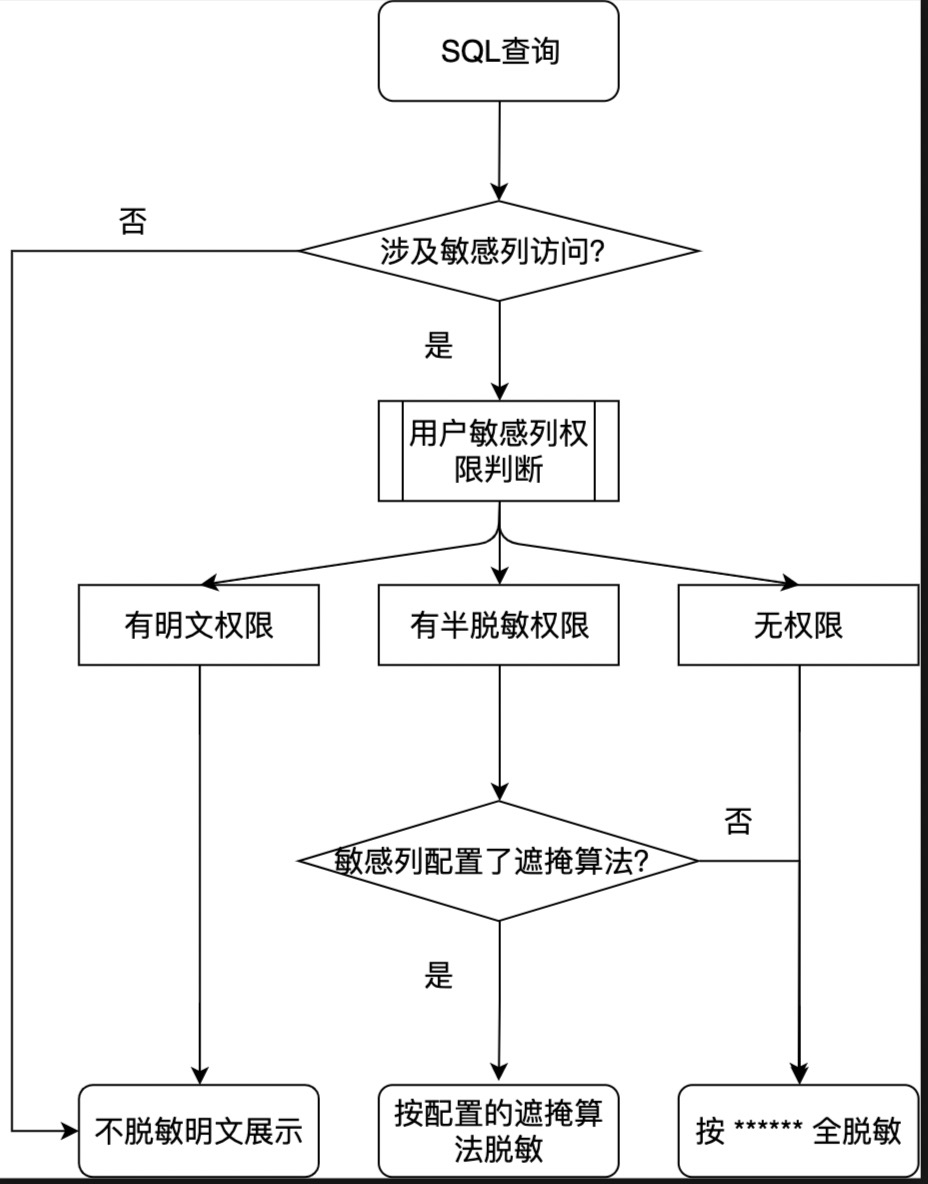
在 SQLConsole-数据查询的帮助手册里面已经介绍,若表上存在敏感、机密字段,并且未单独开通对应字段级别的权限,则在查询结果中会以******显示数据查询脱敏的相关内容,这可理解为对敏感数据进行全遮掩。
然而,在某些场合下研发人员或者测试人员需要感知敏感数据的一部分内容进行问题排查;本文介绍的“敏感数据管理”基于数据遮掩开放的脱敏方式,配合敏感字段权限对脱敏方式的扩展,就能做到这一点。
支持范围
数据遮掩目前只支持关系型数据库、OLAP数据库,NoSQL如MongoDB、Redis暂不支持。
数据遮掩介绍
数据遮掩对数据查询(跨库查询)、数据导出提供了更灵活的脱敏遮掩方式。举个例子:手机号码,我们可以控制只对中间某几位进行遮掩,如136xxxxx799。
数据遮掩基于DMS企业版内置的遮掩算法来实现,用户可基于内置的遮掩算法对敏感字段需要的遮掩效果进行定制
遮掩算法
遮掩算法,是用来实现上述所说部分脱敏的核心,一个遮掩算法,决定了一个敏感字段的脱敏方式:
- 要怎么来实现部分脱敏,哪些部分需要脱敏展示,哪些部分需要原文展示。
- 脱敏展示使用什么字符来展示,是
******还是XXXXXX。
算法种类
目前系统内置以下3种遮掩算法:
- 固定位置:需要脱敏的位置非常明确,比如前N位,中间几位(从第M位到第N位),最后几位,进行脱敏处理。
- 固定字符:需要脱敏的字符非常明确,比如将邮寄地址“浙江省杭州市”进行脱敏处理。
- 全遮掩:对整个数据进行脱敏(算是对原始脱敏能力的一个扩展,让脱敏可以不再是“
******”)。
算法暂不支持自定义实现,用户仅能使用系统提供的内置算法。
支持的数据类型
遮掩算法作用在字段数据内容上面,目前遮掩算法没有对字段类型进行强限制,但是仍推荐只运用在字符串类型、数字类型的字段上面,且字符串类型长度尽可能短,最好是一些格式固定的字段,比如手机号,邮箱号码,身份证号码,姓名等等;太长的字符串在进行算法运算会消耗DB服务一定的计算资源。
敏感列权限——脱敏方式
为了迎合部分脱敏的能力,需要对申请的敏感列权限进行区分;原先的敏感列权限,包括查询、导出、变更,如果申请者申请了某个库、某个表的某个敏感列的查询权限,则在SQL查询,对这个敏感列数据的查询结果,直接以明文展示。
遮掩算法的引入,提供了部分脱敏的能力;敏感列权限的申请,增加了脱敏方式来与部分脱敏搭配使用,如下图所示:
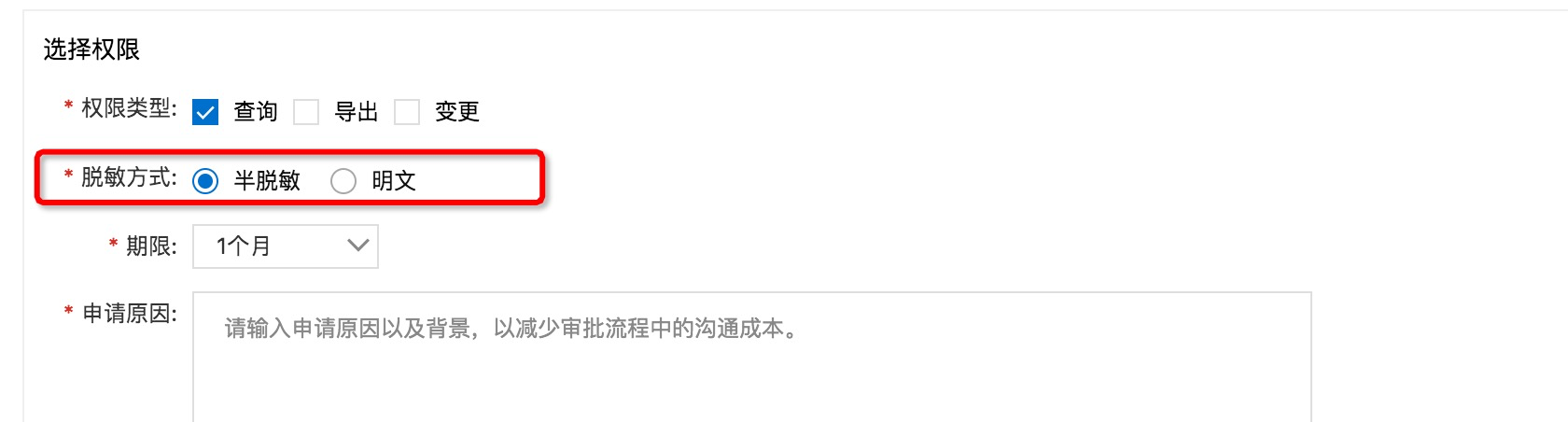
半脱敏
以查询权限为例,若申请时脱敏方式选择的是“半脱敏”,且当前敏感字段定义了遮掩算法(可提供半脱敏能力),则当申请者在SQL查询对这个字段数据的查询结果,将运用配置的遮掩算法来进行脱敏处理,不再是以前的“******”,而是根据定义在该字段上面的遮掩算法,来决定其展示。
明文
同样以查询权限为例子,若申请时脱敏方式选择的是“明文”,则用户在SQL查询对这个字段数据的查询结果,将直接明文展示。
以上描述的逻辑用下面的流程图来展示,理解起来更直观:
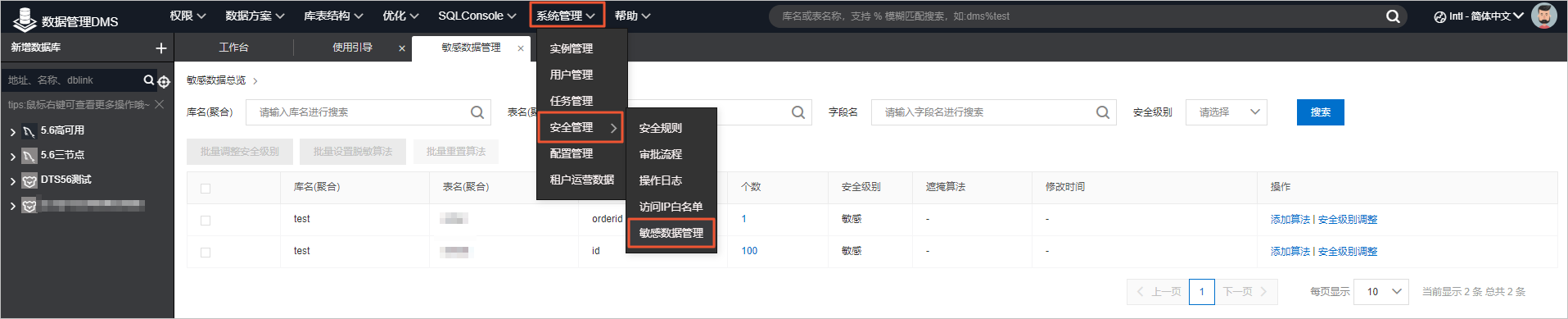
功能入口
数据遮掩功能,归纳到“【系统管理】”->“【敏感数据管理】”菜单页里面。仅限DMS企业版内的管理员、安全管理员、DBA角色可见入口可操作。入口处总览整个企业定义的所有敏感字段,在此处可进行对特定敏感字段设置特定的数据遮掩算法;此外,作为管理视图,可在此处方便的调整敏感字段安全级别。
【温馨提示】
- 1、此处只能看到敏感(安全级别为敏感或者机密)字段,非敏感(安全级别是内部)字段无法在这个页面被搜索到;如果在此总览页面内容为空,则证明您的企业内还没有定义过敏感字段。
- 2、作为管理视图,此处调整敏感字段安全级别仅限于调整原来已经被定为敏感的字段。
算法配置详解
通过“操作”里面的“添加算法”,可对字段设置遮掩算法。
固定位置
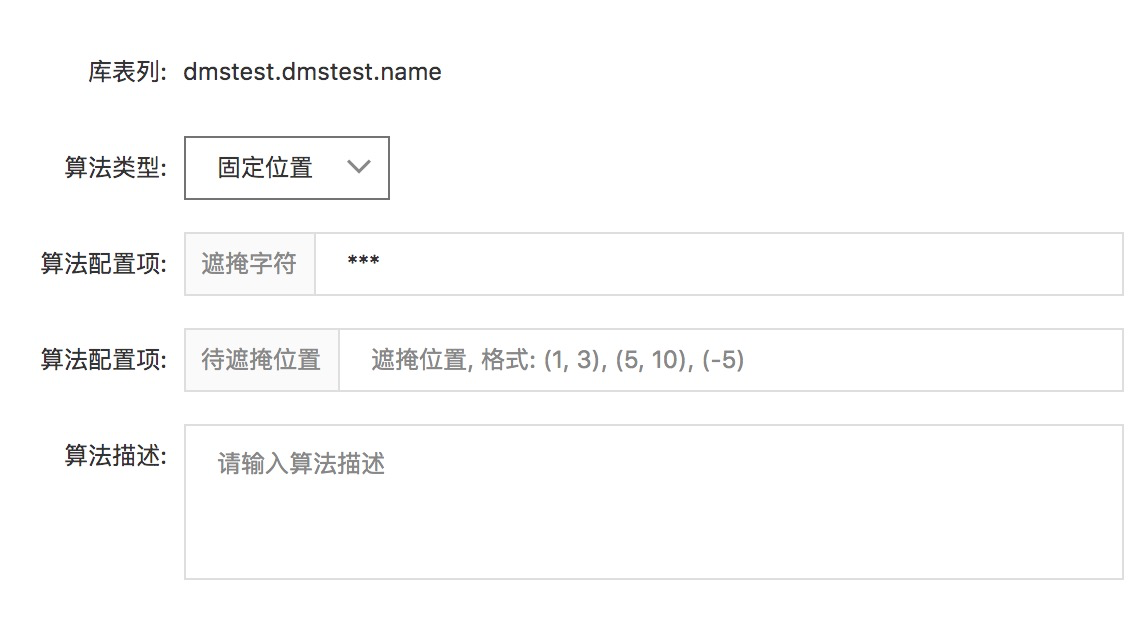
固定位置算法需要进行两个配置项的设置:
- 遮掩字符
- 脱敏展示的字符串,比如
***,xxx,【敏感数据】等等
- 脱敏展示的字符串,比如
- 待遮掩位置
- 定义数据的哪些位置需要进行脱敏,位置定义使用坐标格式,举个例子:
- (1,4) 表示遮掩前4位(字符串从1的位置,到4的位置),也可以使用简便写法(4);
- (8, 10) 表示遮掩中间2位,从第8个字符到第10字符;
- (-4) 表示最后4位,如果数据是定长的,那么你也可以使用坐标格式来定义,这个简便写法适用于非定长的数据
- 也可指定多个位置,但是最多不超过3个位置,具体示例:
(1, 4), (8, 10), (-4)
表示遮掩前4位,中间2位,最后4位
- 定义数据的哪些位置需要进行脱敏,位置定义使用坐标格式,举个例子:
固定字符
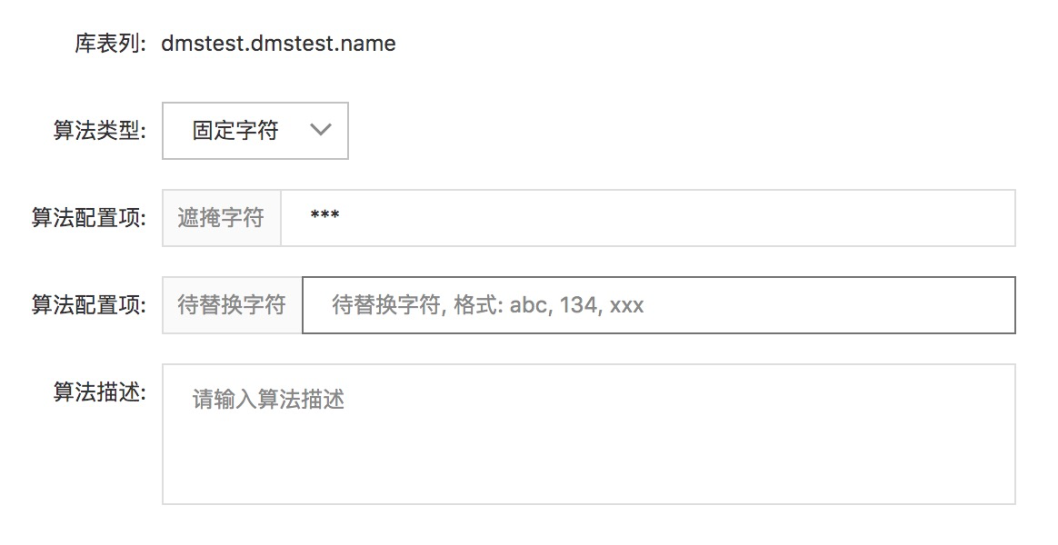
该算法也需要进行两个配置项的设置:
- 遮掩字符:同“固定位置”算法,不赘述
- 待替换字符:定义哪些个字符需要被替换,可配置多个待脱敏的字符串,但是最多不超过3个;举个例子:
test
【说明】对数据内容中的 “test”进行脱敏,脱敏的字符串在“遮掩字符”中定义
实践体验
前置准备
在体验数据遮掩功能之前,需要准备一张设置了敏感列的数据表。
按以下步骤,可实践体验数据遮掩:
- 管理员、安全管理员或者DBA对某个库表的敏感字段配置遮掩算法,入口为敏感数据管理,操作具体敏感字段的“添加算法”。
- 体验者在“权限申请”->“敏感列申请”中申请该敏感字段查询、导出权限,脱敏方式选择“半脱敏”。
- 使用数据查询或者数据导出功能来体验效果。
查询遮掩示例

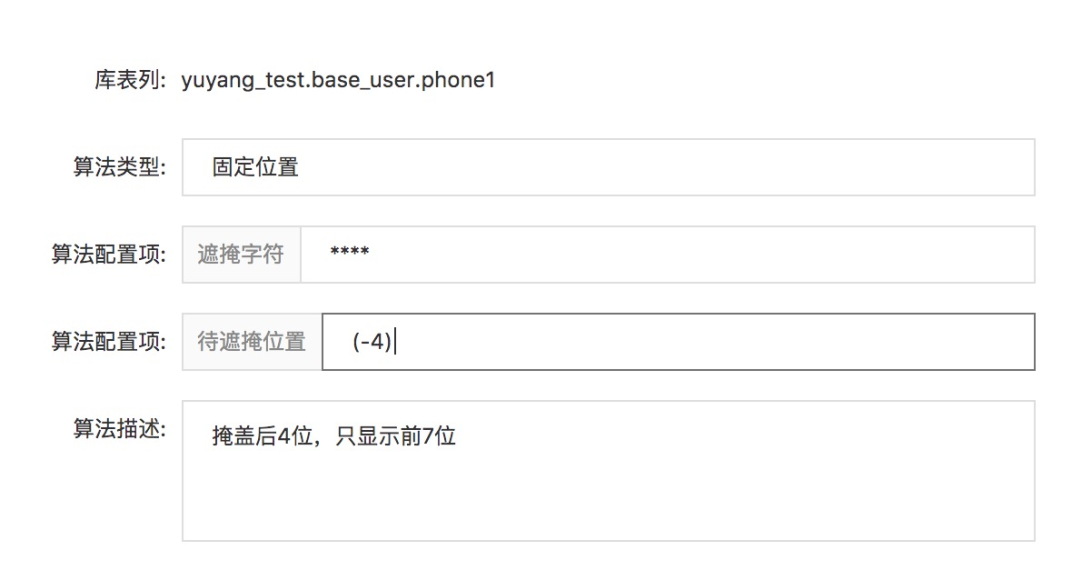

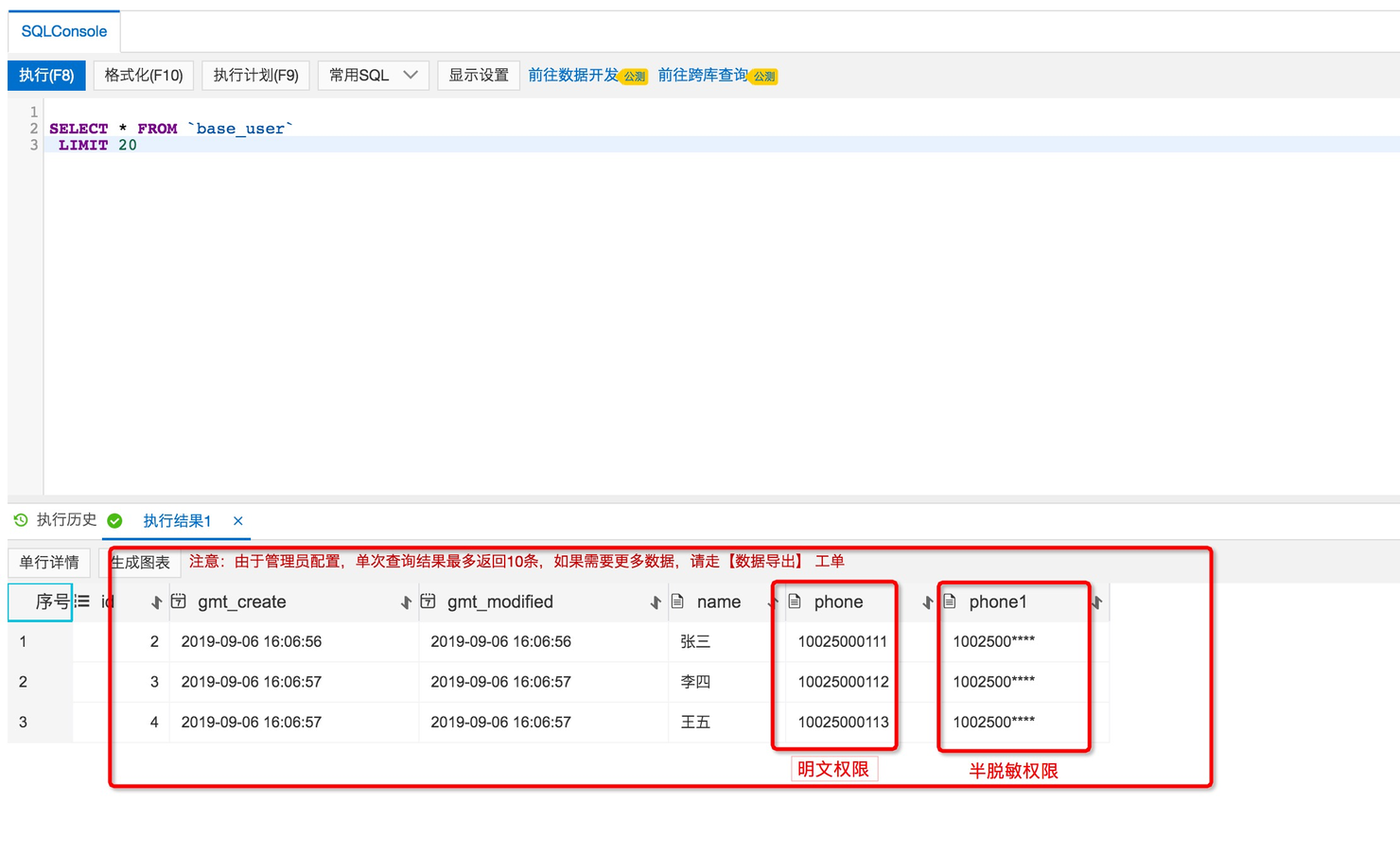
yuyang_test.base_user 定义了两个敏感字段,phone和phone1,phone1字段的遮掩算法设置如上图所示;其中用户对phone敏感字段有查询(明文)权限,对phone1敏感字段有查询(半脱敏)权限,则在SQL查询该表后数据的脱敏展示效果如下所示:
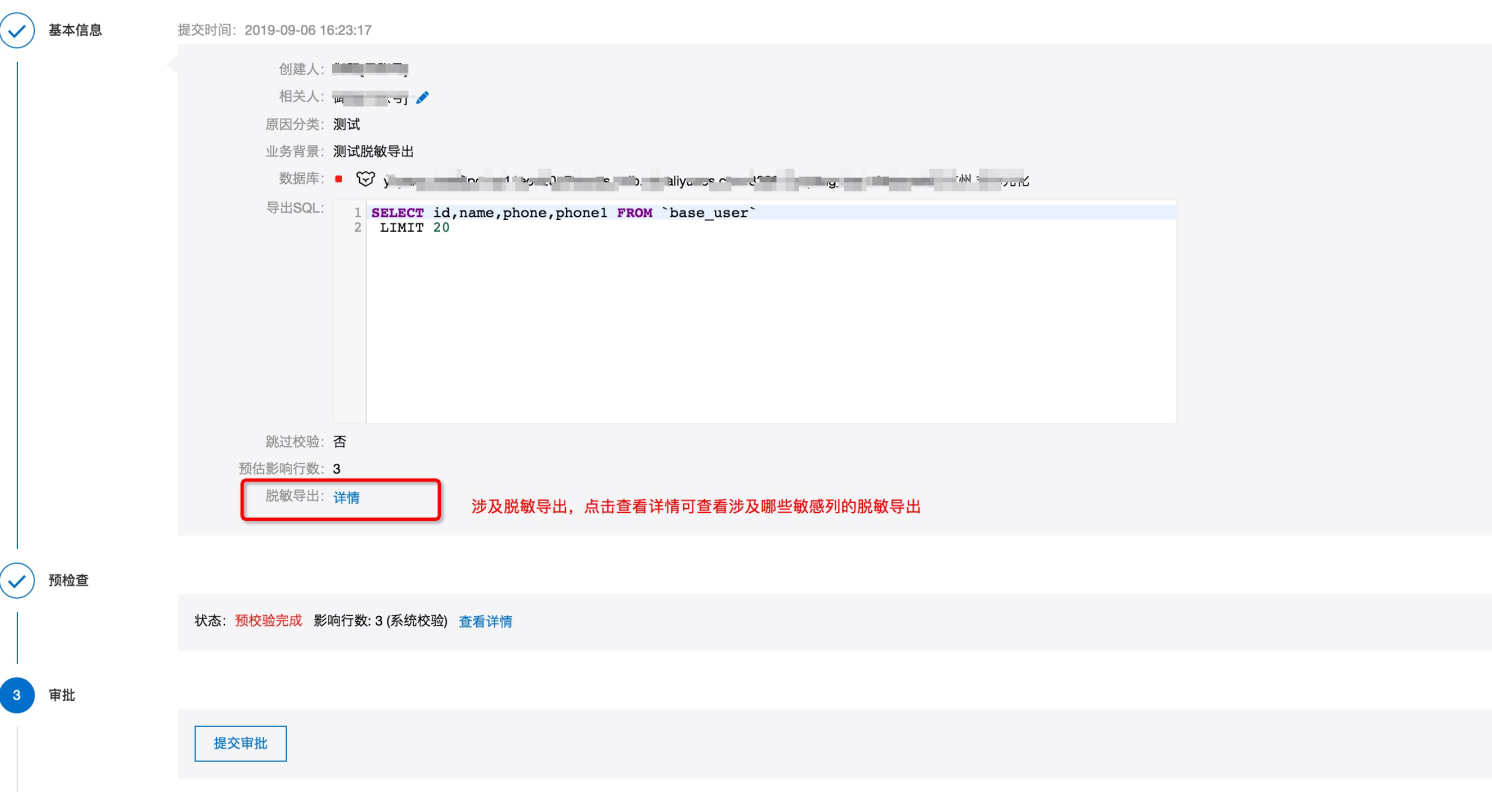
数据导出遮掩示例
数据导出,若导出SQL中包含敏感字段,且该用户具备了敏感字段的“半脱敏”导出权限,则提交申请后,该敏感字段的导出内容为经过遮掩算法运算后的结果,假设该字段没有定义遮掩算法,则使用“******”,逻辑同SQL查询。
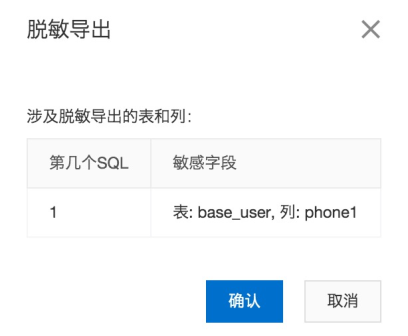
注意事项
- SQL语句无权限或者半脱敏敏感列参与函数运算,数据遮掩无法作用。
- 举个例子,select substr(phone, 10) from base_user,其中phone是敏感字段,因其使用了函数运算,使得脱敏无法正常支持。
- 如果想要在敏感列上面进行函数运算,需要申请对应敏感列的明文权限。
- 数据遮掩对字段类型无限制,但不排除遮掩算法不适用。
- 场景一
- 因为系统对敏感列、遮掩算法的定义存储是聚合的,举个例子:
- 实例A库表字段: dmstest.t1.c1 是敏感字段,c1字段类型是varchar
- 实例B库表字段: dmstest.t1.c1 同样会被标识为敏感字段,c1字段类型是int
- 假设遮掩算法按照c1为varchar的数据格式来定义,到了int类型的c1字段,也许就不适用了; 同名库表列的脱敏算法保持一致,因为列的字段类型无法感知,所以遮掩算法暂时没有对字段类型进行强限制。
- 因为系统对敏感列、遮掩算法的定义存储是聚合的,举个例子:
- 场景二
- 非字符串类型的遮掩,比如日期类型,运用遮掩算法以后,也可能出现不适用;原因非字符串类型要进行遮掩脱敏需要先强制转化为字符串类型,但是类型转化过程涉及到了日期格式化,不同DB类型如MySQL、PostgreSQL、SQLServer等的内置转化逻辑互不相同,可能出现遮掩效果不符合预期的情况;目前识别到SQLServer 日期类型在进行数据遮掩算法运算后,得到的日期格式化会存在问题,导致遮掩效果达不到预期
- 场景一
0 条评论