刚刚,UC伯克利、CMU、斯坦福等,联手发布了最新开源模型骆马(Vicuna)的权重。
3月31日,UC伯克利联手CMU、斯坦福、UCSD和MBZUAI,推出了130亿参数的Vicuna,俗称「小羊驼」(骆马),仅需300美元就能实现ChatGPT 90%的性能。
今天,团队正式发布了Vicuna的权重——只需单个GPU就能跑!

项目地址:https://github.com/lm-sys/FastChat/#fine-tuning
130亿参数,90%匹敌ChatGPT
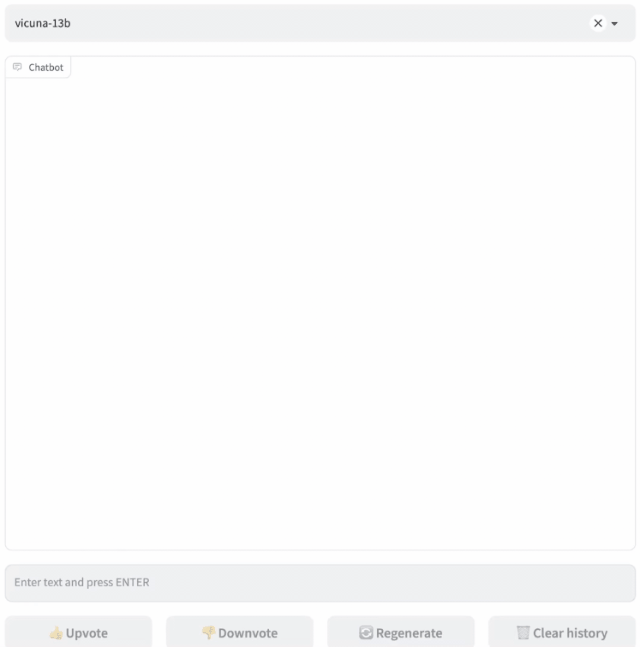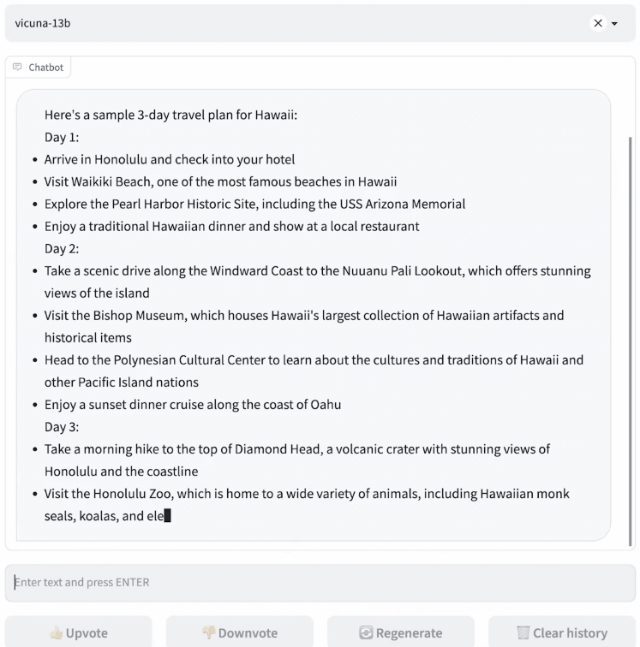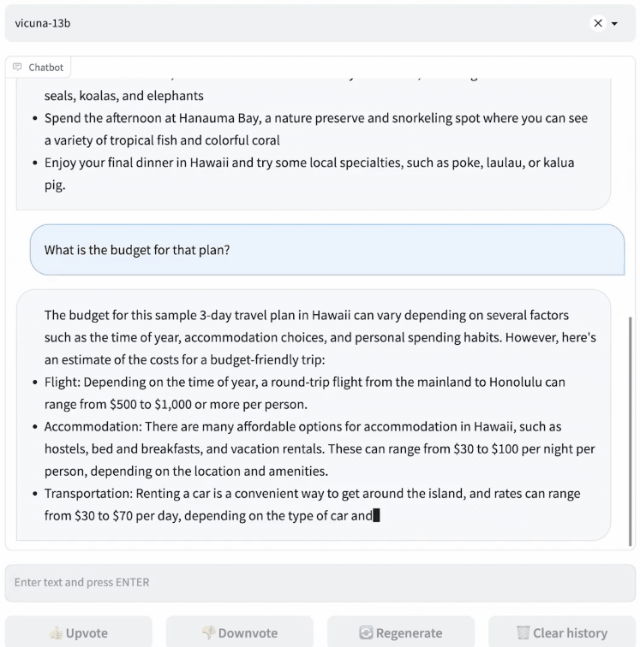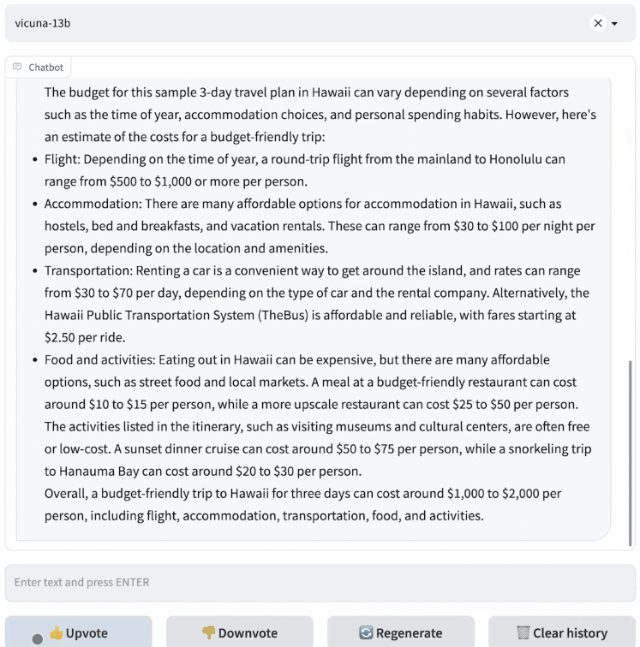
Vicuna是通过在ShareGPT收集的用户共享对话上对LLaMA进行微调训练而来,训练成本近300美元。
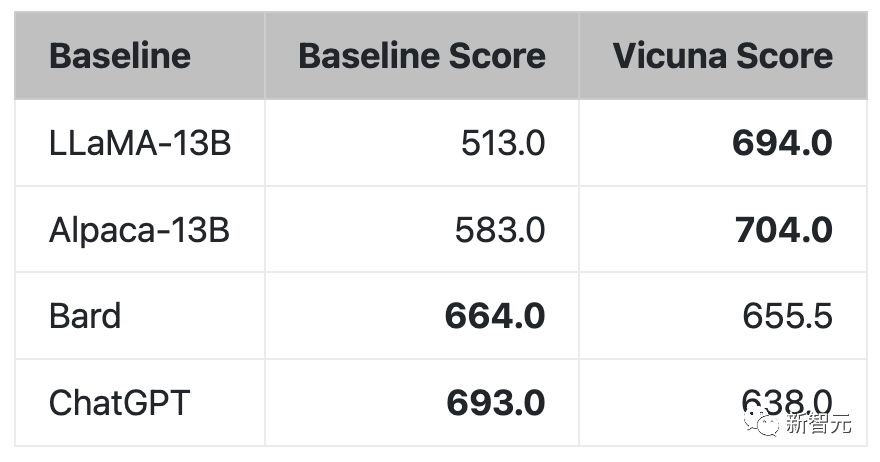
研究人员设计了8个问题类别,包括数学、写作、编码,对Vicuna-13B与其他四个模型进行了性能测试。
测试过程使用GPT-4作为评判标准,结果显示Vicuna-13B在超过90%的情况下实现了与ChatGPT和Bard相匹敌的能力。同时,在在超过90%的情况下胜过了其他模型,如LLaMA和斯坦福的Alpaca。
训练


评估
安装使用
安装
方法一:
# Install FastChatpip3 install fschat# Install a specific commit of huggingface/transformers# Our released weights do not work with commits after this due to some upstream changes in the tokenizer.pip3 install git+https://github.com/huggingface/transformers@c612628045822f909020f7eb6784c79700813eda
方法二:
git clone https://github.com/lm-sys/FastChat.gitcd FastChat
pip3 install --upgrade pip # enable PEP 660 supportpip3 install -e .
权重
1. 按照huggingface上的说明,获得原始的LLaMA权重
2. 通过脚本,自动从团队的Hugging Face账户上下载delta权重
python3 -m fastchat.model.apply_delta--base /path/to/llama-13b--target /output/path/to/vicuna-13b--delta lmsys/vicuna-13b-delta-v0
python3 -m fastchat.serve.cli --model-name /path/to/vicuna/weightspython3 -m fastchat.serve.cli --model-name /path/to/vicuna/weights --num-gpus 2python3 -m fastchat.serve.cli --model-name /path/to/vicuna/weights --device cpupython3 -m fastchat.serve.controller· 启动model worker
python3 -m fastchat.serve.model_worker --model-path /path/to/vicuna/weights
当进程完成模型的加载后,会看到「Uvicorn running on …」。
· 发送测试消息
python3 -m fastchat.serve.test_message --model-name vicuna-13bpython3 -m fastchat.serve.gradio_web_server微调

# Install skypilot from the master branchpip install git+https://github.com/skypilot-org/skypilot.git
sky launch -c vicuna -s scripts/train-vicuna.yaml --env WANDB_API_KEYsky launch -c alpaca -s scripts/train-alpaca.yaml --env WANDB_API_KEY
· 使用本地GPU进行微调
torchrun --nnodes=1 --nproc_per_node=8 --master_port=fastchat/train/train_mem.py--model_name_or_path--data_path--bf16 True--output_dir ./checkpoints--num_train_epochs 3--per_device_train_batch_size 4--per_device_eval_batch_size 4--gradient_accumulation_steps 1--evaluation_strategy "no"--save_strategy "steps"--save_steps 1200--save_total_limit 100--learning_rate 2e-5--weight_decay 0.--warmup_ratio 0.03--lr_scheduler_type "cosine"--logging_steps 1--fsdp "full_shard auto_wrap"--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'--tf32 True--model_max_length 2048--gradient_checkpointing True--lazy_preprocess True
0 条评论